Expert Python
L'apprentissage automatique et la science des données s'accompagnent d'un ensemble de problèmes différents de ceux que vous rencontrerez dans l'ingénierie logicielle traditionnelle. Les systèmes de contrôle de version aident les développeurs à gérer les modifications du code source. Mais contrôle de version des données, gestion des modifications des modèles et jeux de données, n’est pas si bien établie.
Il n’est pas facile de suivre toutes les données que vous utilisez pour les expériences et les modèles que vous produisez. Avec précision reproduire des expériences que vous ou d'autres avez fait est un défi. De nombreuses équipes développent activement des outils et des cadres pour résoudre ces problèmes.
Dans ce didacticiel, vous apprendrez à:
- Utilisez un outil appelé DVC pour relever certains de ces défis
- Suivi et version vos jeux de données et modèles
- Partagez un ordinateur de développement unique entre coéquipiers
- Créer reproductible expériences d'apprentissage automatique
Ce didacticiel comprend plusieurs exemples de techniques de contrôle de version de données en action. Pour suivre, vous pouvez obtenir le référentiel avec l'exemple de code en cliquant sur le lien suivant:
Qu'est-ce que le contrôle de version des données?
Dans l'ingénierie logicielle standard, de nombreuses personnes doivent travailler sur une base de code partagée et gérer plusieurs versions du même code. Cela peut rapidement entraîner de la confusion et des erreurs coûteuses.
Pour résoudre ce problème, les développeurs utilisent systèmes de contrôle de version, comme Git, qui aident à garder les membres de l'équipe organisés.
Dans un système de contrôle de version, il existe un référentiel central de code qui représente l’état officiel actuel du projet. Un développeur peut faire une copie de ce projet, apporter des modifications et demander que sa nouvelle version devienne la version officielle. Leur code est ensuite examiné et testé avant d'être déployé en production.
Ces cycles de rétroaction rapides peuvent se produire plusieurs fois par jour dans les projets de développement traditionnels. Mais des conventions et des normes similaires sont largement absentes de la science des données commerciales et de l'apprentissage automatique. Contrôle de version des données est un ensemble d'outils et de processus qui tente d'adapter le processus de contrôle de version au monde des données.
La mise en place de systèmes permettant aux gens de travailler rapidement et de reprendre là où les autres se sont arrêtés augmenterait la vitesse et la qualité des résultats obtenus. Cela permettrait aux gens de gérer les données de manière transparente, de mener des expériences efficacement et de collaborer avec d'autres.
Remarque: Une expérience dans ce contexte, cela signifie soit former un modèle, soit exécuter des opérations sur un ensemble de données pour en tirer quelque chose.
Un outil qui aide les chercheurs à gérer leurs données et leurs modèles et à exécuter des expériences reproductibles est DVC, Qui veut dire Contrôle de la version des données.
Qu'est-ce que DVC?
DVC est un outil de ligne de commande écrit en Python. Il imite les commandes et les flux de travail Git pour s'assurer que les utilisateurs peuvent rapidement l'intégrer dans leur pratique Git habituelle. Si vous n'avez pas encore travaillé avec Git, assurez-vous de consulter Introduction à Git et GitHub pour les développeurs Python. Si vous connaissez Git, mais que vous souhaitez améliorer vos compétences, consultez les conseils avancés de Git pour les développeurs Python.
DVC est destiné à être exécuté avec Git. En fait, le git et dvc les commandes seront souvent utilisées en tandem, l'une après l'autre. Alors que Git est utilisé pour stocker et le code de version, DVC fait de même pour les fichiers de données et de modèles.
Git peut stocker du code localement et également sur un service d'hébergement comme GitHub, Bitbucket ou GitLab. De même, DVC utilise un référentiel distant pour stocker toutes vos données et modèles. C'est la seule source de vérité, et elle peut être partagée avec toute l'équipe. Vous pouvez obtenir une copie locale du référentiel distant, modifier les fichiers, puis télécharger vos modifications pour les partager avec les membres de l'équipe.
Le référentiel distant peut se trouver sur le même ordinateur sur lequel vous travaillez, ou il peut se trouver dans le cloud. DVC prend en charge la plupart des principaux fournisseurs de cloud, notamment AWS, GCP et Azure. Mais vous pouvez configurer un référentiel DVC distant sur n'importe quel serveur et le connecter à votre ordinateur portable. Il existe des mesures de protection pour empêcher les membres de corrompre ou de supprimer les données distantes.
Lorsque vous stockez vos données et modèles dans le référentiel distant, un .dvc fichier est créé. UNE .dvc file est un petit fichier texte qui pointe vers vos fichiers de données réels dans le stockage distant.
le .dvc Le fichier est léger et destiné à être stocké avec votre code dans GitHub. Lorsque vous téléchargez un référentiel Git, vous obtenez également le .dvc des dossiers. Vous pouvez ensuite utiliser ces fichiers pour obtenir les données associées à ce référentiel. Les fichiers de données et de modèles volumineux sont stockés dans votre stockage distant DVC, et les petits .dvc les fichiers qui pointent vers vos données vont dans GitHub.
La meilleure façon de comprendre le DVC est de l'utiliser, alors allons-y. Vous explorerez les fonctionnalités les plus importantes en travaillant à travers plusieurs exemples. Avant de commencer, vous devez configurer un environnement dans lequel travailler, puis obtenir des données.
Configurez votre environnement de travail
Dans ce didacticiel, vous apprendrez à utiliser DVC en vous entraînant sur des exemples qui fonctionnent avec des données d'image. Vous allez jouer avec de nombreux fichiers image et entraîner un modèle d'apprentissage automatique qui reconnaît le contenu d'une image.
Pour parcourir les exemples, vous devez avoir Python et Git installés sur votre système. Vous pouvez suivre le Guide d'installation et de configuration de Python 3 pour installer Python sur votre système. Pour installer Git, vous pouvez lire Installation de Git.
Étant donné que DVC est un outil de ligne de commande, vous devez être familiarisé avec l'utilisation de la ligne de commande de votre système d'exploitation. Si vous êtes un utilisateur Windows, jetez un œil à Exécution de DVC sous Windows.
Pour préparer votre espace de travail, vous devez suivre les étapes suivantes:
- Créez et activez un environnement virtuel.
- Installez DVC et ses bibliothèques Python prérequises.
- Forkez et clonez un référentiel GitHub avec tout le code.
- Téléchargez un ensemble de données gratuit à utiliser dans les exemples.
Vous pouvez utiliser n'importe quel package et gestionnaire d'environnement de votre choix. Ce didacticiel utilise conda car il prend en charge les outils de science des données et d'apprentissage automatique. Pour créer et activer un environnement virtuel, ouvrez l'interface de ligne de commande de votre choix et tapez la commande suivante:
$ conda create --name dvc python=3.8.2 -y
le créer La commande crée un nouvel environnement virtuel. le --Nom switch donne un nom à cet environnement, qui dans ce cas est dvc. le python L'argument vous permet de sélectionner la version de Python que vous souhaitez installer dans l'environnement. Finalement, le -y switch accepte automatiquement d'installer tous les packages nécessaires dont Python a besoin, sans que vous ayez à répondre à aucune invite.
Une fois que tout est installé, activez l'environnement:
Vous disposez désormais d'un environnement Python distinct de l'installation Python de votre système d'exploitation. Cela vous donne une table rase et vous évite de gâcher accidentellement quelque chose dans votre version par défaut de Python.
Vous utiliserez également des bibliothèques externes dans ce didacticiel:
dvcest la vedette de ce tutoriel.scikit-learnest une bibliothèque d'apprentissage automatique qui vous permet de former des modèles.scikit-imageest une bibliothèque de traitement d'image que vous utiliserez pour préparer les données pour la formation.pandasest une bibliothèque pour l'analyse de données qui organise les données dans des structures de type tableau.engourdiest une bibliothèque de calcul numérique qui prend en charge les données multidimensionnelles, comme les images.
Certains d'entre eux ne sont disponibles que via conda-forge, vous devrez donc l'ajouter à votre configuration et utiliser installation de conda pour installer toutes les bibliothèques:
$ conda config - ajouter des chaînes conda-forge
$ conda installer dvc scikit-learn scikit-image pandas numpy
Vous pouvez également utiliser le pépin installateur:
$ python -m pip installer dvc scikit-learn scikit-image pandas numpy
Vous disposez maintenant de toutes les bibliothèques Python nécessaires pour exécuter le code.
Ce didacticiel est livré avec un référentiel prêt à l'emploi qui contient la structure du répertoire et le code pour vous permettre d'expérimenter rapidement DVC. Vous pouvez obtenir le référentiel en cliquant sur le lien ci-dessous:
Vous devez transférer le référentiel sur votre propre compte GitHub. Sur la page GitHub du référentiel, cliquez sur Fourchette dans le coin supérieur droit de l'écran et sélectionnez votre compte privé dans la fenêtre qui apparaît. GitHub créera une copie fourchue du référentiel sous votre compte.
Clonez le référentiel forké sur votre ordinateur avec le clone git et positionnez votre ligne de commande dans le dossier du référentiel:
$ git clone https://github.com/YourUsername/data-version-control
$ CD contrôle de la version des données
N'oubliez pas de remplacer Ton nom d'utilisateur dans la commande ci-dessus avec votre nom d'utilisateur réel. Vous devriez maintenant avoir un clone du référentiel sur votre ordinateur.
Voici la structure des dossiers pour le référentiel:
contrôle de la version des données /
|
├── données /
│ ├── préparé /
│ └── brut /
|
├── métriques /
├── modèle /
└── src /
├── evaluer.py
├── prepare.py
└── train.py
Il y a six dossiers dans votre référentiel:
src /est pour le code source.Les données/est pour toutes les versions de l'ensemble de données.données / brutes /est pour les données obtenues à partir d'une source externe.données / préparé /est pour les données modifiées en interne.modèle/est destiné aux modèles d'apprentissage automatique.données / métriques /est pour suivre les métriques de performance de vos modèles.
le src / Le dossier contient trois fichiers Python:
prepare.pycontient du code pour préparer les données pour la formation.train.pycontient du code pour entraîner un modèle d'apprentissage automatique.évaluer.pycontient du code pour évaluer les résultats d'un modèle d'apprentissage automatique.
La dernière étape de la préparation consiste à obtenir un exemple de jeu de données que vous pouvez utiliser pour pratiquer le DVC. Les images sont bien adaptées à ce didacticiel particulier, car la gestion de nombreux fichiers volumineux est le domaine où DVC brille, vous aurez donc un bon aperçu des fonctionnalités les plus puissantes de DVC. Vous utiliserez l'ensemble de données Imagenette de fastai.
Imagenette est un sous-ensemble de l'ensemble de données ImageNet, qui est souvent utilisé comme ensemble de données de référence dans de nombreux articles sur l'apprentissage automatique. ImageNet est trop volumineux pour être utilisé comme exemple sur un ordinateur portable, vous utiliserez donc le plus petit ensemble de données Imagenette. Accédez à la page Imagenette GitHub et cliquez sur Téléchargement 160 px dans le LISEZ-MOI.
Cela téléchargera l'ensemble de données compressé dans une archive TAR. Les utilisateurs Mac peuvent extraire les fichiers en double-cliquant sur l'archive dans le Finder. Les utilisateurs Linux peuvent le décompresser avec le le goudron commander. Les utilisateurs de Windows devront installer un outil qui décompresse les fichiers TAR, comme 7-zip.
L'ensemble de données est structuré d'une manière particulière. Il comporte deux dossiers principaux:
train/comprend des images utilisées pour entraîner un modèle.val /inclut des images utilisées pour valider un modèle.
Remarque: La validation se produit généralement tandis que le modèle est la formation afin que les chercheurs puissent comprendre rapidement à quel point le modèle fonctionne. Étant donné que ce didacticiel n'est pas axé sur les mesures de performances, vous utiliserez l'ensemble de validation pour tester votre modèle après il a été formé.
Imagenette est une classification ensemble de données, ce qui signifie que chaque image a une classe associée qui décrit le contenu de l'image. Pour résoudre un problème de classification, vous devez former un modèle qui peut déterminer avec précision la classe d'une image. Il doit regarder une image et identifier correctement ce qui est montré.
le train/ et val / les dossiers sont ensuite divisés en plusieurs dossiers. Chaque dossier a un code qui représente l'une des 10 classes possibles, et chaque image de cet ensemble de données appartient à l'une des dix classes:
- Tanche
- Springer anglais
- Lecteur de cassettes
- Tronçonneuse
- Église
- cor français
- Camion à ordures
- Pompe à essence
- Balle de golf
- Parachute
Pour plus de simplicité et de rapidité, vous entraînerez un modèle en utilisant seulement deux des dix classes, balle de golf et parachute. Une fois entraîné, le modèle acceptera n'importe quelle image et vous dira s'il s'agit d'une image d'une balle de golf ou d'une image d'un parachute. Ce type de problème, dans lequel un modèle décide entre deux types d'objets, est appelé classification binaire.
Copiez le train/ et val / dossiers et placez-les dans votre nouveau référentiel, dans le données / brutes / dossier. La structure de votre référentiel devrait maintenant ressembler à ceci:
contrôle de la version des données /
|
├── données /
│ ├── préparé /
│ └── brut /
│ ├── train /
│ │ ├── n01440764 /
│ │ ├── n02102040 /
│ │ ├── n02979186 /
│ │ ├── n03000684 /
│ │ ├── n03028079 /
│ │ ├── n03394916 /
│ │ ├── n03417042 /
│ │ ├── n03425413 /
│ │ ├── n03445777 /
│ │ └── n03888257 /
| |
│ └── val /
│ ├── n01440764 /
│ ├── n02102040 /
│ ├── n02979186 /
│ ├── n03000684 /
│ ├── n03028079 /
│ ├── n03394916 /
│ ├── n03417042 /
│ ├── n03425413 /
│ ├── n03445777 /
│ └── n03888257 /
|
├── métriques /
├── modèle /
└── src /
├── evaluer.py
├── prepare.py
└── train.py
Vous pouvez également obtenir les données en utilisant le boucle commander:
$ curl https://s3.amazonaws.com/fast-ai-imageclas/imagenette2-160.tgz
-O imagenette2-160.tgz
La barre oblique inverse () vous permet de séparer une commande en plusieurs lignes pour une meilleure lisibilité. La commande ci-dessus téléchargera l'archive TAR.
Vous pouvez ensuite extraire le jeu de données et le déplacer vers les dossiers de données:
$ tar -xzvf imagenette2-160.tgz
$ mv imagenette2-160 / train data / raw / train
$ mv imagenette2-160 / données val / raw / val
Enfin, supprimez l'archive et le dossier extrait:
$ rm -rf imagenette2-160
$ rm imagenette2-160.tgz
Génial! Vous avez terminé la configuration et êtes prêt à commencer à jouer avec DVC.
Pratiquez le flux de travail DVC de base
L'ensemble de données que vous avez téléchargé suffit pour commencer à pratiquer les bases du DVC. Dans cette section, vous découvrirez comment DVC fonctionne en tandem avec Git pour gérer votre code et vos données.
Pour commencer, créez une branche pour votre première expérience:
$ git checkout -b "first_experiment"
git checkout change votre succursale actuelle et le -b switch indique à Git que cette branche n'existe pas et doit être créée.
Ensuite, vous devez initialiser DVC. Assurez-vous que vous êtes placé dans le dossier de niveau supérieur du référentiel, puis exécutez dvc init:
Cela créera un .dvc dossier contenant les informations de configuration, tout comme le .git dossier pour Git. En principe, vous n’avez jamais besoin d’ouvrir ce dossier, mais vous allez jeter un œil dans ce didacticiel pour comprendre ce qui se passe sous le capot.
Remarque: DVC a récemment commencé à collecter des analyses d'utilisation anonymes afin que les auteurs puissent mieux comprendre comment DVC est utilisé. Cela les aide à améliorer l'outil. Vous pouvez le désactiver en définissant l'option de configuration d'analyse sur faux:
$ dvc config core.analytics faux
Git vous donne la possibilité de pousser votre code local vers un référentiel distant afin que vous ayez une seule source de vérité partagée avec d'autres développeurs. D'autres personnes peuvent vérifier votre code et travailler dessus localement sans craindre de corrompre le code pour tout le monde. La même chose est vraie pour DVC.
Vous avez besoin d'une sorte de stockage à distance pour les fichiers de données et de modèles contrôlés par DVC. Cela peut être aussi simple qu'un autre dossier sur votre système. Créez un dossier quelque part sur votre système en dehors du contrôle de la version des données / référentiel et appelez-le dvc_remote.
Maintenant reviens à ton contrôle de la version des données / référentiel et indiquez à DVC où se trouve le stockage distant sur votre système:
$ dvc remote ajouter -d chemin de stockage_distant / vers / votre / dvc_remote
DVC sait maintenant où sauvegarder vos données et modèles. ajout à distance dvc stocke l'emplacement sur votre stockage distant et le nomme remote_storage. Vous pouvez choisir un autre nom si vous le souhaitez. le -ré Le commutateur indique à DVC qu'il s'agit de votre stockage distant par défaut. Vous pouvez ajouter plusieurs emplacements de stockage et basculer entre eux.
Vous pouvez toujours vérifier la télécommande de votre référentiel. À l'intérieur de .dvc le dossier de votre référentiel est un fichier appelé config, qui stocke les informations de configuration sur le référentiel:
[core]
analytique = faux
remote = remote_storage
['remote "remote_storage"']
URL = / chemin / vers / votre / stockage_distant
remote = remote_storage définit votre remote_storage dossier par défaut, et ['remote "remote_storage"'] définit la configuration de votre télécommande. le URL pointe vers le dossier de votre système. Si votre stockage distant était plutôt un système de stockage cloud, alors le URL variable serait définie sur une URL Web.
DVC prend en charge de nombreux systèmes de stockage basés sur le cloud, tels que les buckets AWS S3, Google Cloud Storage et Microsoft Azure Blob Storage. Pour en savoir plus, consultez la documentation DVC officielle de la commande dvc remote add.
Votre référentiel est maintenant initialisé et prêt à fonctionner. Vous aborderez trois actions de base:
- Suivi des fichiers
- Téléchargement de fichiers
- Téléchargement de fichiers
La règle de base que vous suivrez est que les petits fichiers vont sur GitHub et les gros fichiers vont vers le stockage à distance DVC.
Suivi des fichiers
Git et DVC utilisent le ajouter commande pour démarrer le suivi des fichiers. Cela place les fichiers sous leur contrôle respectif.
Ajouter le train/ et val / dossiers au contrôle DVC:
$ dvc ajouter des données / brutes / train
$ dvc ajouter des données / brutes / val
Les images sont considérées comme des fichiers volumineux, surtout si elles sont rassemblées dans des ensembles de données contenant des centaines ou des milliers de fichiers. le ajouter La commande ajoute ces deux dossiers sous le contrôle DVC. Voici ce que fait DVC sous le capot:
- Ajoute votre
train/etval /dossiers à.gitignore - Crée deux fichiers avec le
.dvcextension,train.dvcetval.dvc - Copies les
train/etval /dossiers dans une zone de transit
Ce processus est un peu complexe et mérite une explication plus détaillée.
.gitignore est un fichier texte contenant une liste de fichiers que Git doit ignorer ou ne pas suivre. Lorsqu'un fichier est répertorié dans .gitignore, il est invisible pour git commandes. En ajoutant le train/ et val / dossiers à .gitignore, DVC s'assure que vous ne téléverserez pas accidentellement de gros fichiers de données sur GitHub.
Vous avez appris .dvc fichiers dans la section Qu'est-ce que DVC? Ce sont de petits fichiers texte qui pointent DVC vers vos données stockées à distance. Rappelez-vous la règle d'or: les fichiers et dossiers de données volumineux vont dans le stockage à distance DVC, .dvc les fichiers vont dans GitHub. Lorsque vous reviendrez au travail et que vous vérifierez tout le code de GitHub, vous obtiendrez également le .dvc fichiers, que vous pouvez utiliser pour obtenir vos fichiers de données volumineux.
Enfin, DVC copie les fichiers de données dans une zone de transit. La zone de rassemblement s'appelle un cache. Lorsque vous avez initialisé DVC avec dvc init, il a créé un .dvc dossier dans votre référentiel. Dans ce dossier, il a créé le dossier cache, .dvc / cache. Quand tu cours dvc ajouter, tous les fichiers sont copiés dans .dvc / cache.
Cela soulève deux questions:
- La copie de fichiers ne gaspille-t-elle pas beaucoup d'espace?
- Pouvez-vous mettre le cache ailleurs?
La réponse aux deux questions est oui. Vous aborderez ces deux problèmes dans la section Partager une machine de développement.
Voici à quoi ressemble le référentiel avant l'exécution de toute commande:

Tout ce que contrôle DVC est à gauche (en vert) et tout ce que contrôle Git est à droite (en bleu). Le référentiel local a un code.py fichier avec du code Python et un train/ dossier contenant les données d'entraînement. Ceci est une version simplifiée de ce qui se passera avec votre référentiel.
Quand tu cours dvc ajouter un train /, le dossier contenant des fichiers volumineux passe sous contrôle DVC et le petit .dvc et .gitignore les fichiers passent sous le contrôle de Git. le train/ dossier va également dans la zone de préparation, ou cache:

Une fois que les gros fichiers image ont été placés sous contrôle DVC, vous pouvez ajouter tout le code et les petits fichiers au contrôle Git avec git ajouter:
le --tout switch ajoute tous les fichiers visibles par Git à la zone de préparation.
Désormais, tous les fichiers sont sous le contrôle de leurs systèmes de contrôle de version respectifs:

Pour récapituler, les fichiers d'image volumineux passent sous contrôle DVC et les petits fichiers sous contrôle Git. Si quelqu'un veut travailler sur votre projet et utiliser le train/ et val / data, ils devront d'abord télécharger votre référentiel Git. Ils pourraient alors utiliser le .dvc fichiers pour obtenir les données.
Mais avant que les gens puissent obtenir votre référentiel et vos données, vous devez télécharger vos fichiers sur un stockage distant.
Téléchargement de fichiers
Pour télécharger des fichiers sur GitHub, vous devez d'abord créer un instantané de l'état actuel de votre référentiel. Lorsque vous ajoutez tous les fichiers modifiés à la zone de préparation avec git ajouter, créez un instantané avec commettre commander:
$ git commit -m "Première validation avec les fichiers d'installation et DVC"
le -m switch signifie que le texte cité qui suit est un message de validation expliquant ce qui a été fait. Cette commande transforme les modifications suivies individuelles en un instantané complet de l'état de votre référentiel.
DVC dispose également d'un commettre commande, mais il ne fait pas la même chose que git commit. DVC n’a pas besoin d’un instantané de l’ensemble du référentiel. Il peut simplement importer des fichiers individuels dès qu'ils sont suivis avec dvc ajouter.
Tu utilises commit dvc lorsqu'un fichier déjà suivi change. Si vous apportez une modification locale aux données, vous devez valider la modification dans le cache avant de la télécharger sur Remote. Vous n'avez pas modifié vos données depuis leur ajout, vous pouvez donc ignorer l'étape de validation.
Remarque: Étant donné que cette partie de DVC est différente de Git, vous voudrez peut-être en savoir plus sur la ajouter et commettre commandes dans la documentation officielle DVC.
Pour télécharger vos fichiers du cache vers la télécommande, utilisez le pousser commander:
DVC examinera tous les dossiers de votre référentiel pour trouver .dvc des dossiers. Comme mentionné, ces fichiers indiqueront à DVC quelles données doivent être sauvegardées, et DVC les copiera du cache vers le stockage distant:

Vos données sont désormais stockées en toute sécurité dans un emplacement éloigné de votre référentiel. Enfin, transférez les fichiers sous contrôle Git vers GitHub:
$ git push --set-upstream origin first_experiment
GitHub ne connaît pas la nouvelle branche que vous avez créée localement, donc la première pousser doit utiliser le --set-upstream option. origine est l'endroit où se trouve votre principale version hébergée du code. Dans ce cas, cela signifie GitHub. Votre code et d'autres petits fichiers sont désormais stockés en toute sécurité dans GitHub:

Bien joué! Tous vos fichiers ont été sauvegardés dans un stockage distant.
Téléchargement de fichiers
Pour savoir comment télécharger des fichiers, vous devez d'abord en supprimer certains de votre référentiel.
Dès que vous avez ajouté vos données avec dvc ajouter et l'a poussé avec pousser dvc, il est sauvegardé et sécurisé. Si vous souhaitez économiser de l'espace, vous pouvez supprimer les données réelles. Tant que tous les fichiers sont suivis par DVC, et leur .dvc les fichiers sont dans votre référentiel, vous pouvez récupérer rapidement les données.
Vous pouvez supprimer l'ensemble val / dossier, mais assurez-vous que le .dvc le fichier n'est pas supprimé:
Cela supprimera le data / raw / val / dossier de votre référentiel, mais le dossier est toujours stocké en toute sécurité dans votre cache et le stockage distant. Vous pouvez le récupérer à tout moment.
Pour récupérer vos données du cache, utilisez le paiement dvc commander:
$ dvc checkout data / raw / val.dvc
Votre data / raw / val / le dossier a été restauré. Si vous souhaitez que DVC effectue une recherche dans tout votre référentiel et vérifie tout ce qui manque, utilisez paiement dvc sans arguments supplémentaires.
Lorsque vous clonez votre référentiel GitHub sur une nouvelle machine, le cache sera vide. le chercher La commande récupère le contenu du stockage distant dans le cache:
$ dvc récupérer les données / raw / val.dvc
Ou vous pouvez utiliser simplement récupération dvc pour obtenir les données pour tout Fichiers DVC dans le référentiel. Une fois que les données sont dans votre cache, récupérez-les dans le référentiel avec paiement dvc. Vous pouvez effectuer les deux chercher et check-out avec une seule commande, tirage dvc:
tirage dvc exécute récupération dvc suivi par paiement dvc. Il copie vos données de la télécommande vers le cache et dans votre référentiel en un seul passage. Ces commandes imitent à peu près ce que fait Git, puisque Git a également chercher, check-out, et tirer commandes:

Gardez à l'esprit que vous devez d'abord obtenir le .dvc fichiers de Git, et alors seulement vous pouvez appeler des commandes DVC comme chercher et check-out pour obtenir vos données. Si la .dvc les fichiers ne sont pas dans votre référentiel, alors DVC ne saura pas quelles données vous souhaitez récupérer et extraire.
Vous avez maintenant appris le flux de travail de base pour DVC et Git. Chaque fois que vous ajoutez plus de données ou modifiez du code, vous pouvez ajouter, commettre, et pousser pour garder tout versionné et sauvegardé en toute sécurité. Pour de nombreuses personnes, ce flux de travail de base sera suffisant pour leurs besoins quotidiens.
Le reste de ce didacticiel se concentre sur certains cas d'utilisation spécifiques tels que le partage d'ordinateurs avec plusieurs personnes et la création de pipelines reproductibles. Pour découvrir comment DVC gère ces problèmes, vous devez disposer d'un code permettant d'exécuter des expériences d'apprentissage automatique.
Créer un modèle d'apprentissage automatique
À l'aide du jeu de données Imagenette, vous entraînerez un modèle pour distinguer les images de balles de golf et de parachutes.
Vous suivrez trois étapes principales:
- Préparez les données pour la formation.
- Formez votre modèle d'apprentissage automatique.
- Évaluez les performances de votre modèle.
Comme mentionné précédemment, ces étapes correspondent aux trois fichiers Python dans le src / dossier:
prepare.pytrain.pyévaluer.py
Les sous-sections suivantes expliquent ce que fait chaque fichier. Le contenu entier du fichier sera affiché, suivi d'une explication de ce que fait chaque ligne.
Préparation des données
Étant donné que les données sont stockées dans plusieurs dossiers, Python devrait les rechercher dans tous pour trouver les images. Le nom du dossier détermine ce qu'est l'étiquette. Cela n’est peut-être pas difficile pour un ordinateur, mais ce n’est pas très intuitif pour un humain.
Pour faciliter l'utilisation des données, vous allez créer un fichier CSV qui contiendra une liste de toutes les images et leurs libellés à utiliser pour la formation. Le fichier CSV aura deux colonnes, un nom de fichier colonne contenant le chemin complet d'une seule image et un étiquette colonne qui contiendra la chaîne d'étiquette réelle, comme "balle de golf" ou "parachute". Chaque ligne représentera une image.
Voici un aperçu de ce à quoi ressemblera le CSV:
nom de fichier, étiquette
full / path / to / data-version-control / raw / n03445777 / n03445777_5768.JPEG, balle de golf
full / path / to / data-version-control / raw / n03445777 / n03445777_5768, balle de golf
full / path / to / data-version-control / raw / n03445777 / n03445777_11967.JPEG, balle de golf
...
Vous aurez besoin de deux fichiers CSV:
train.csvcontiendra une liste d'images pour la formation.test.csvcontiendra une liste d'images à tester.
Vous pouvez créer les fichiers CSV en exécutant le prepare.py script, qui comporte trois étapes principales:
- Mappez les noms de dossier comme
n03445777 /pour étiqueter des noms commeballe de golf. - Obtenez une liste de fichiers pour
balle de golfetparachuteÉtiquettes. - Sauver le
liste de fichiers–étiquettepaires sous forme de fichier CSV.
Voici le code source que vous utiliserez pour l'étape de préparation:
1 # prepare.py
2 de pathlib importer Chemin
3
4 importer pandas comme pd
5
6 FOLDERS_TO_LABELS =
7 "n03445777": "balle de golf",
8 "n03888257": "parachute"
9
dix
11 def get_files_and_labels(source_path):
12 images = []
13 Étiquettes = []
14 pour image_path dans source_path.rglob("* / *. JPEG"):
15 nom de fichier = image_path.absolu()
16 dossier = image_path.parent.Nom
17 si dossier dans FOLDERS_TO_LABELS:
18 images.ajouter(nom de fichier)
19 étiquette = FOLDERS_TO_LABELS[[[[dossier]
20 Étiquettes.ajouter(étiquette)
21 revenir images, Étiquettes
22
23 def save_as_csv(noms de fichiers, Étiquettes, destination):
24 dictionnaire de données = "nom de fichier": noms de fichiers, "étiquette": Étiquettes
25 trame de données = pd.Trame de données(dictionnaire de données)
26 trame de données.to_csv(destination)
27
28 def principale(repo_path):
29 Chemin de données = repo_path / "Les données"
30 train_path = Chemin de données / "brut / train"
31 test_path = Chemin de données / "raw / val"
32 train_files, train_labels = get_files_and_labels(train_path)
33 test_files, test_labels = get_files_and_labels(test_path)
34 préparé = Chemin de données / "préparé"
35 save_as_csv(train_files, train_labels, préparé / "train.csv")
36 save_as_csv(test_files, test_labels, préparé / "test.csv")
37
38 si __Nom__ == "__principale__":
39 repo_path = Chemin(__fichier__).parent.parent
40 principale(repo_path)
Vous n'avez pas besoin de comprendre tout ce qui se passe dans le code pour exécuter ce didacticiel. Au cas où vous seriez curieux, voici une explication détaillée de ce que fait le code:
-
Ligne 6: Les noms des dossiers contenant des images de balles de golf et de parachutes sont mappés sur les étiquettes
"balle de golf"et"parachute"dans un dictionnaire appeléFOLDERS_TO_LABELS. -
Lignes 11 à 21:
get_files_and_labels ()accepte unCheminqui pointe vers ledonnées / brutes /dossier. La fonction effectue une boucle sur tous les dossiers et sous-dossiers pour rechercher les fichiers qui se terminent par.jpegextension. Les étiquettes sont attribuées aux fichiers dont les dossiers sont représentés sous forme de clés dansFOLDERS_TO_LABELS. Les noms de fichiers et les étiquettes sont renvoyés sous forme de listes. -
Lignes 23 à 26:
save_as_csv ()accepte une liste de fichiers, une liste d'étiquettes et une destinationChemin. Les noms de fichiers et les étiquettes sont formatés en tant que DataFrame pandas et enregistrés en tant que fichier CSV à la destination. -
Lignes 28 à 36:
principale()pilote la fonctionnalité du script. Il courtget_files_and_labels ()pour retrouver toutes les images dans ledonnées / brutes / train /etdata / raw / val /Dossiers. Les noms de fichiers et leurs étiquettes correspondantes sont ensuite enregistrés sous forme de deux fichiers CSV dans ledonnées / préparé /dossier,train.csvettest.csv. -
Lignes 38 à 40: Quand tu cours
prepare.pyà partir de la ligne de commande, la portée principale du script est exécutée et appelleprincipale().
Toutes les manipulations de chemin sont effectuées à l'aide du pathlib module. Si vous n'êtes pas familier avec ces opérations, consultez Utilisation de fichiers en Python.
Exécutez le prepare.py script dans la ligne de commande:
Une fois le script terminé, vous aurez le train.csv et test.csv fichiers dans votre données / préparé / dossier. Vous devrez les ajouter à DVC et à la .dvc fichiers sur GitHub:
$ dvc ajouter des données / préparé / train.csv données / préparé / test.csv
$ git add --all
$ git commit -m "Création de fichiers CSV de formation et de test"
Génial! Vous disposez désormais d'une liste de fichiers à utiliser pour entraîner et tester un modèle d'apprentissage automatique. L'étape suivante consiste à charger les images et à les utiliser pour exécuter la formation.
Entraîner le modèle
Pour entraîner ce modèle, vous utiliserez une méthode appelée enseignement supervisé. Cette méthode consiste à montrer au modèle une image et à lui faire deviner ce que l'image montre. Ensuite, vous lui montrez l'étiquette correcte. S'il a mal deviné, alors il se corrigera. Vous faites cela plusieurs fois pour chaque image et étiquette de l'ensemble de données.
Expliquer le fonctionnement de chaque modèle dépasse le cadre de ce didacticiel. Heureusement, scikit-learn propose de nombreux modèles prêts à l'emploi qui résolvent une variété de problèmes. Chaque modèle peut être entraîné en appelant quelques méthodes standard.
En utilisant le train.py fichier, vous exécuterez six étapes:
- Lisez le fichier CSV qui indique à Python où se trouvent les images.
- Chargez les images d'entraînement dans la mémoire.
- Chargez les étiquettes de classe en mémoire.
- Prétraitez les images afin qu'elles puissent être utilisées pour la formation.
- Formez un modèle d'apprentissage automatique pour classer les images.
- Enregistrez le modèle d'apprentissage automatique sur votre disque.
Voici le code source que vous allez utiliser pour l'étape d'entraînement:
1 # train.py
2 de joblib importer déverser
3 de pathlib importer Chemin
4
5 importer engourdi comme np
6 importer pandas comme pd
7 de skimage.io importer imread_collection
8 de skimage.transform importer redimensionner
9 de sklearn.linear_model importer SGDClassifier
dix
11 def charger des images(trame de données, nom de colonne):
12 liste de fichiers = trame de données[[[[nom de colonne].lister()
13 image_list = imread_collection(liste de fichiers)
14 revenir image_list
15
16 def load_labels(trame de données, nom de colonne):
17 label_list = trame de données[[[[nom de colonne].lister()
18 revenir label_list
19
20 def prétraiter(image):
21 redimensionné = redimensionner(image, (100, 100, 3))
22 remodelé = redimensionné.remodeler((1, 30000))
23 revenir remodeler
24
25 def load_data(Chemin de données):
26 df = pd.read_csv(Chemin de données)
27 Étiquettes = load_labels(trame de données=df, nom de colonne="étiquette")
28 raw_images = charger des images(trame de données=df, nom de colonne="nom de fichier")
29 traitées_images = [[[[prétraiter(image) pour image dans raw_images]
30 Les données = np.enchaîner(traitées_images, axe=0)
31 revenir Les données, Étiquettes
32
33 def principale(repo_path):
34 train_csv_path = repo_path / "données / préparé / train.csv"
35 train_data, Étiquettes = load_data(train_csv_path)
36 sgd = SGDClassifier(max_iter=dix)
37 modèle_formé = sgd.en forme(train_data, Étiquettes)
38 déverser(modèle_formé, repo_path / "model / model.joblib")
39
40 si __Nom__ == "__principale__":
41 repo_path = Chemin(__fichier__).parent.parent
42 principale(repo_path)
Voici ce que fait le code:
-
Lignes 11 à 14:
charger des images()accepte un DataFrame qui représente l'un des fichiers CSV générés dansprepare.pyet le nom de la colonne contenant les noms de fichiers d'image. La fonction charge ensuite et renvoie les images sous forme de liste de tableaux NumPy. -
Lignes 16 à 18:
load_labels ()accepte le même DataFrame quecharger des images()et le nom de la colonne qui contient les étiquettes. La fonction lit et renvoie une liste d'étiquettes correspondant à chaque image. -
Lignes 20 à 23:
prétraitement ()accepte un tableau NumPy qui représente une seule image, la redimensionne et la remodèle en une seule ligne de données. -
Lignes 25 à 31:
load_data ()accepte leCheminà latrain.csvfichier. The function loads the images and labels, preprocesses them, and stacks them into a single two-dimensional NumPy array since the scikit-learn classifiers you’ll use expect data to be in this format. The data array and the labels are returned to the caller. -
Lines 33 to 38:
main()loads the data in memory and defines an example classifier called SGDClassifier. The classifier is trained using the training data and saved in themodel/dossier. scikit-learn recommends thejoblibmodule to accomplish this. -
Lines 40 to 42: The main scope of the script runs
main()quandtrain.pyis executed.
Now run the train.py script in the command line:
The code can take a few minutes to run, depending on how strong your computer is. You might get a warning while executing this code:
ConvergenceWarning: Maximum number of iteration reached before convergence.
Consider increasing max_iter to improve the fit.
This means scikit-learn thinks you could increase max_iter and get better results. You’ll do that in one of the following sections, but the goal of this tutorial is for your experiments to run quickly rather than have the highest possible accuracy.
When the script finishes, you’ll have a trained machine learning model saved in the model/ folder with the name model.joblib. This is the most important file of the experiment. It needs to be added to DVC, with the corresponding .dvc file committed to GitHub:
$ dvc add model/model.joblib
$ git add --all
$ git commit -m "Trained an SGD classifier"
Well done! You’ve trained a machine learning model to distinguish between two classes of images. The next step is to determine how accurately the model performs on test images, which the model hasn’t seen during training.
Evaluating the Model
Evaluation brings a bit of a reward because you finally get some feedback on your efforts. At the end of this process, you’ll have some hard numbers to tell you how well the model is doing.
Here’s the source code you’re going to use for the evaluation step:
1 # evaluate.py
2 de joblib importer charge
3 importer json
4 de pathlib importer Path
5
6 de sklearn.metrics importer accuracy_score
7
8 de train importer load_data
9
dix def main(repo_path):
11 test_csv_path = repo_path / "data/prepared/test.csv"
12 test_data, labels = load_data(test_csv_path)
13 modèle = charge(repo_path / "model/model.joblib")
14 predictions = modèle.predict(test_data)
15 précision = accuracy_score(labels, predictions)
16 metrics = "accuracy": précision
17 accuracy_path = repo_path / "metrics/accuracy.json"
18 accuracy_path.write_text(json.dumps(metrics))
19
20 si __name__ == "__main__":
21 repo_path = Path(__file__).parent.parent
22 main(repo_path)
Here’s what the code does:
-
Lines 10 to 14:
main()evaluates the trained model on the test data. The function loads the test images, loads the model, and predicts which images correspond to which labels. -
Lines 15 to 18: The predictions generated by the model are compared to the actual labels from
test.csv, and the accuracy is saved as a JSON file in themetrics/dossier. The accuracy represents the ratio of correctly classified images. The JSON format is selected because DVC can use it to compare metrics between different experiments, which you’ll learn to do in the section Create Reproducible Pipelines. -
Lines 20 to 22: The main scope of the script runs
main()quandevaluate.pyis executed.
Run the evaluate.py script in the command line:
Your model is now evaluated, and the metrics are safely stored in a the accuracy.json fichier. Whenever you change something about your model or use a different one, you can see if it’s improving by comparing it to this value.
In this case, your JSON file contains only one object, the accuracy of your model:
"accuracy": 0.670595690747782
If you print the précision variable multiplied by 100, you’ll get the percentage of correct classifications. In this case, the model classified 67.06 percent of test images correctly.
le précision JSON file is really small, and it’s useful to keep it in GitHub so you can quickly check how well each experiment performed:
$ git add --all
$ git commit -m "Evaluate the SGD model accuracy"
Great work! With evaluation completed, you’re ready to dig into some of DVC’s advanced features and processes.
Version Datasets and Models
At the core of reproducible data science is the ability to take snapshots of everything used to build a model. Every time you run an experiment, you want to know exactly what inputs went into the system and what outputs were created.
In this section, you’ll play with a more complex workflow for versioning your experiments. You’ll also open a .dvc file and look under the hood.
First, push all the changes you’ve made to the first_experiment branch to your GitHub and DVC remote storage:
Your code and model are now backed up on remote storage.
Training a model or finishing an experiment is a milestone for a project. You should have a way to find and return to this specific point.
Tagging Commits
A common practice is to use tagging to mark a specific point in your Git history as being important. Since you’ve completed an experiment and produced a new model, create a tag to signal to yourself and others that you have a ready-to-go model:
$ git tag -a sgd-classifier -m "SGDClassifier with accuracy 67.06%"
le -a switch is used to annotate your tag. You can make this as simple or as complex as you want. Some teams version their trained models with version number, like v1.0, v1.3, and so on. Others use dates and the initials of the team member who trained the model. You and your team decide how to keep track of your models. le -m switch allows you to add a message string to the tag, just like with commits.
Git tags aren’t pushed with regular commits, so they have to be pushed separately to your repository’s origin on GitHub or whatever platform you use. Use the --tags switch to push all tags from your local repository to the remote:
If you’re using GitHub, then you can access tags through the Releases tab of your repository.
You can always have a look at all the tags in the current repository:
DVC workflows heavily rely on effective Git practices. Tagging specific commits marks important milestones for your project. Another way to give your workflow more order and transparency is to use branching.
Creating One Git Branch Per Experiment
So far, you’ve done everything on the first_experiment branch. Complex problems or long-term projects often require running many experiments. A good idea is to create a new branch for every experiment.
In your first experiment, you set the maximum number of iterations of the model to dix. You can try setting that number higher to see if it improves the result. Create a new branch and call it sgd-100-iterations:
$ git checkout -b "sgd-100-iterations"
When you create a new branch, all the .dvc files you had in the previous branch will be present in the new branch, just like other files and folders.
Update the code in train.py so that the SGDClassifier model has the parameter max_iter=100:
# train.py
def main(repo_path):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
sgd = SGDClassifier(max_iter=100)
trained_model = sgd.fit(train_data, labels)
dump(trained_model, repo_path / "model/model.joblib")
That’s the only change you’ll make. Rerun the training and evaluation by running train.py et evaluate.py:
$ python src/train.py
$ python src/evaluate.py
You should now have a new model.joblib file and a new accuracy.json fichier.
Since the training process has changed the model.joblib file, you need to commit it to the DVC cache:
DVC will throw a prompt that asks if you’re sure you want to make the change. presse Oui and then Enter.
Rappelles toi, dvc commit works differently from git commit and is used to update an already tracked fichier. This won’t delete the previous model, but it will create a new one.
Add and commit the changes you’ve made to Git:
$ git add --all
$ git commit -m "Change SGD max_iter to 100"
Tag your new experiment:
$ git tag -a sgd-100-iter -m "Trained an SGD Classifier for 100 iterations"
$ git push origin --tags
Push the code changes to GitHub and the DVC changes to your remote storage:
$ git push --set-upstream origin sgd-100-iter
$ dvc push
You can jump between branches by checking out the code from GitHub and then checking out the data and model from DVC. For example, you can check out the first_example branch and get the associated data and model:
$ git checkout first_experiment
$ dvc checkout
Excellent. You now have multiple experiments and their results versioned and stored, and you can access them by checking out the content via Git and DVC.
Looking Inside DVC Files
You’ve created and committed a few .dvc files to GitHub, but what’s inside the files? Open the current .dvc file for the model, data-version-control/model/model.joblib.dvc. Here’s an example of the contents:
md5: 62bdac455a6574ed68a1744da1505745
outs:
- md5: 96652bd680f9b8bd7c223488ac97f151
path: model.joblib
cache: vrai
metric: faux
persist: faux
The contents can be confusing. DVC files are YAML files. The information is stored in key-value pairs and lists. The first one is the md5 key followed by a string of seemingly random characters.
MD5 is a well-known hashing function. Hashing takes a file of arbitrary size and uses its contents to produce a string of characters of fixed length, called a hacher ou checksum. In this case, the length is thirty-two characters. Regardless of what the original size of the file is, MD5 will always calculate a hash of thirty-two characters.
Two files that are exactly the same will produce the same hash. But if even a single bit changes in one of the files, then the hashes will be completely different. DVC uses these properties of MD5 to accomplish two important goals:
- To keep track of which files have changed just by looking at their hash values
- To see when two large files are the same so that only one copy can be stored in the cache or remote storage
In the example .dvc file that you’re looking at, there are two md5 values. The first one describes the .dvc file itself, and the second one describes the model.joblib fichier. path is a file path to the model, relative to your working directory, and cache is a Boolean that determines whether DVC should cache the model.
You’ll see some of the other fields in later sections, but you can learn everything there is to know about the .dvc file format in the official docs.
The workflow you’ve just learned is enough if you’re the only one using the computer where you run experiments. But lots of teams have to share powerful machines to do their work.
Share a Development Machine
In many academic and work settings, computationally heavy work isn’t done on individual laptops because they’re not powerful enough to handle large amounts of data or intense processing. Instead, teams use cloud computers or on-premises workstations. Multiple users often work on a single machine.
With multiple users working with the same data, you don’t want to have many copies of the same data spread out among users and repositories. To save space, DVC allows you to set up a shared cache. When you initialize a DVC repository with dvc init, DVC will put the cache in the repository’s .dvc/cache folder by default.
You can change that default to point somewhere else on the computer. Create a new folder somewhere on your computer. Call it shared_cache, and tell DVC to use that folder as the cache:
$ dvc cache dir path/to/shared_cache
Now every time you run dvc add ou dvc commit, the data will be backed up in that folder. When you use dvc fetch to get data from remote storage, it will go to the shared cache, and dvc checkout will bring it to your working repository.
If you’ve been following along and working through the examples in this tutorial, then all your files will be in your repository’s .dvc/cache dossier. After executing the above command, move the data from the default cache to the new, shared one:
$ mv .dvc/cache/* path/to/shared_cache
All users on that machine can now point their repository caches to the shared cache:
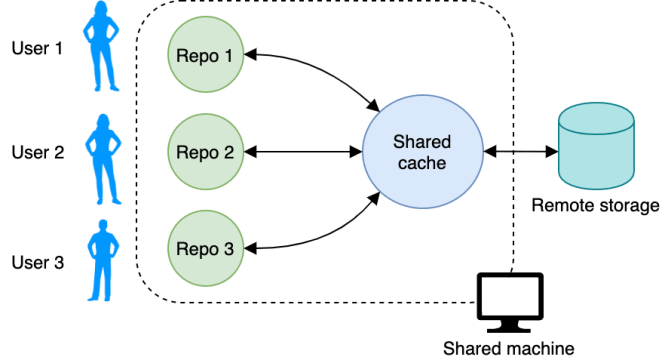
Génial. Now you have a shared cache that all other users can share for their repositories. If your operating system (OS) doesn’t allow everyone to work with the shared cache, then make sure all the permissions on your system are set correctly. You can find more details on setting up a shared system in the DVC docs.
If you check your repository’s .dvc/config file, then you’ll see a new section appear:
[cache]
dir = /path/to/shared_cache
This allows you to double-check where your data gets backed up.
But how does this help you save space? Instead of having copies of the same data in your local repository, the shared cache, et all the other repositories on the machine, DVC can use links. Links are a feature of operating systems.
If you have a file, like an image, then you can create a link to that file. The link looks just like another file on your system, but it doesn’t contain the data. It only refers to the actual file somewhere else on the system, like a shortcut. There are many types of links, like reflinks, symlinks, et hardlinks. Each has different properties.
DVC will try to use reflinks by default, but they’re not available on all computers. If your OS doesn’t support reflinks, DVC will default to creating copies. You can learn more about file link types in the DVC docs.
You can change the default behavior of your cache by changing the cache.type configuration option:
$ dvc config cache.type symlink
You can replace symlink avec reflink, hardlink, ou copies. Research each type of link and choose the most appropriate option for the OS you’re working on. Remember, you can check how your DVC repository is currently configured by reading the .dvc/config file:
[cache]
dir = /path/to/shared_cache
type = symlink
If you make a change to the cache.type, it doesn’t take effect immediately. You need to tell DVC to check out links instead of file copies:
le --relink switch will tell DVC to check the cache type and relink all the files that are currently tracked by DVC.
If there are models or data files in your repository or cache that aren’t being used, then you can save additional space by cleaning up your repository with dvc gc. gc signifie garbage collection and will remove any unused files and directories from the cache.
Important: Be careful with any commands that delete data!
Make sure you understand all the nuances by consulting the official docs for commands that remove files, such as gc et retirer.
You’re now all set to share a development machine with your team. The next feature to explore is creating pipelines.
Create Reproducible Pipelines
Here’s a recap of the steps you made so far to train your machine learning model:
- Fetching the data
- Preparing the data
- Running training
- Evaluating the training run
You fetched the data manually and added it to remote storage. You can now get it with dvc checkout ou dvc pull. The other steps were executed by running various Python files. These can be chained together into a single execution called a DVC pipeline that requires only one command.
Create a new branch and call it sgd-pipeline:
$ git checkout -b sgd-pipeline
You’ll use this branch to rerun the experiment as a DVC pipeline. A pipeline consists of multiple stages and is executed using a dvc run command. Each stage has three components:
- Inputs
- Outputs
- Command
DVC uses the term dependencies for inputs and outs for outputs. The command can be anything you usually run in the command line, including Python files. You can practice creating a pipeline of stages while running another experiment. Each of your three Python files, prepare.py, train.py, et evaluate.py will be represented by a stage in the pipeline.
Remarque: You’re going to reproduce all the files you created with prepare.py, train.py, et evaluate.py by creating pipelines.
A pipeline automatically adds newly created files to DVC control, just as if you’ve typed dvc add. Since you’ve manually added a lot of your files to DVC control already, DVC will get confused if you try to create the same files using a pipeline.
To avoid that, first remove the CSV files, models, and metrics using dvc remove:
$ dvc remove data/prepared/train.csv.dvc
data/prepared/test.csv.dvc
model/model.joblib.dvc --outs
This will remove the .dvc files and the associated data targeted by the .dvc files. You should now have a blank slate to re-create these files using DVC pipelines.
First, you’re going to run prepare.py as a DVC pipeline stage. The command for this is dvc run, which needs to know the dependencies, outputs, and command:
- Dependencies:
prepare.pyand the data indata/raw - Les sorties:
train.csvettest.csv - Command:
python prepare.py
Exécuter prepare.py as a DVC pipeline stage with the dvc run command:
1 $ dvc run -n prepare
2 -d src/prepare.py -d data/raw
3 -o data/prepared/train.csv -o data/prepared/test.csv
4 python src/prepare.py
All this is a single command. The first row starts the dvc run command and accepts a few options:
- le
-nswitch gives the stage a name. - le
-dswitch passes the dependencies to the command. - le
-oswitch defines the outputs of the command.
The main argument to the command is the Python command that will be executed, python src/prepare.py. In plain English, the above dvc run command gives DVC the following information:
- Line 1: You want to run a pipeline stage and call it
prepare. - Line 2: The pipeline needs the
prepare.pyfile and thedata/rawdossier. - Line 3: The pipeline will produce the
train.csvettest.csvfiles. - Line 4: The command to execute is
python src/prepare.py.
Once you create the stage, DVC will create two files, dvc.yaml et dvc.lock. Open them and take a look inside.
This is an example of what you’ll see in dvc.yaml:
étapes:
prepare:
cmd: python src/prepare.py
deps:
- data/raw
- src/prepare.py
outs:
- data/prepared/test.csv
- data/prepared/train.csv
It’s all the information you put in the dvc run command. The top-level element, étapes, has elements nested under it, one for each stage. Currently, you have only one stage, prepare. As you chain more, they’ll show up in this file. Technically, you don’t have to type dvc run commands in the command line—you can create all your stages here.
Chaque dvc.yaml has a corresponding dvc.lock file, which is also in the YAML format. The information inside is similar, with the addition of MD5 hashes for all dependencies and outputs:
prepare:
cmd: python src/prepare.py
deps:
- path: data/raw
md5: a8a5252d9b14ab2c1be283822a86981a.dir
- path: src/prepare.py
md5: 0e29f075d51efc6d280851d66f8943fe
outs:
- path: data/prepared/test.csv
md5: d4a8cdf527c2c58d8cc4464c48f2b5c5
- path: data/prepared/train.csv
md5: 50cbdb38dbf0121a6314c4ad9ff786fe
Adding MD5 hashes allows DVC to track all dependencies and outputs and detect if any of these files change. For example, if a dependency file changes, then it will have a different hash value, and DVC will know it needs to rerun that stage with the new dependency. So instead of having individual .dvc files for train.csv, test.csv, et model.joblib, everything is tracked in the .lock fichier.
Great—you’ve automated the first stage of the pipeline, which can be visualized as a flow diagram:

You’ll use the CSV files produced by this stage in the following stage.
The next stage in the pipeline is training. The dependencies are the train.py file itself and the train.csv file in data/prepared. The only output is the model.joblib fichier. To create a pipeline stage out of train.py, execute it with dvc run, specifying the correct dependencies and outputs:
$ dvc run -n train
-d src/train.py -d data/prepared/train.csv
-o model/model.joblib
python src/train.py
This will create the second stage of the pipeline and record it in the dvc.yml et dvc.lock files. Here’s a visualization of the new state of the pipeline:

Two down, one to go! The final stage will be the evaluation. The dependencies are the evaluate.py file and the model file generated in the previous stage. The output is the metrics file, accuracy.json. Exécuter evaluate.py avec dvc run:
$ dvc run -n evaluate
-d src/evaluate.py -d model/model.joblib
-M metrics/accuracy.json
python src/evaluate.py
Notice that you used the -M switch instead of -o. DVC treats metrics differently from other outputs. When you run this command, it will generate the accuracy.json file, but DVC will know that it’s a metric used to measure the performance of the model.
You can get DVC to show you all the metrics it knows about with the dvc show command:
$ dvc metrics show
metrics/accuracy.json:
accuracy: 0.6996197718631179
You’ve completed the final stage of the pipeline, which looks like this:

You can now see your entire workflow in a single image. Don’t forget to tag your new branch and push all the changes to GitHub and DVC:
$ git add --all
$ git commit -m "Rerun SGD as pipeline"
$ dvc commit
$ git push --set-upstream origin sgd-pipeline
$ git tag -a sgd-pipeline -m "Trained SGD as DVC pipeline."
$ git push origin --tags
$ dvc push
This will version and store your code, models, and data for the new DVC pipeline.
Now for the best part!
For training, you’ll use a random forest classifier, which is a different model that can be used for classification. It’s more complex than the SGDClassifier and could potentially yield better results. Start by creating and checking out a new branch and calling it random_forest:
$ git checkout -b "random_forest"
The power of pipelines is the ability to reproduce them with minimal hassle whenever you change anything. Modify your train.py to use a RandomForestClassifier instead of the SGDClassifier:
# train.py
de joblib importer dump
de pathlib importer Path
importer numpy comme np
importer pandas comme pd
de skimage.io importer imread_collection
de skimage.transform importer resize
de sklearn.ensemble importer RandomForestClassifier
# ...
def main(path_to_repo):
train_csv_path = repo_path / "data/prepared/train.csv"
train_data, labels = load_data(train_csv_path)
rf = RandomForestClassifier()
trained_model = rf.fit(train_data, labels)
dump(trained_model, repo_path / "model/model.joblib")
The only lines that changed were importing the RandomForestClassifier instead of the SGDClassifier, creating an instance of the classifier, and calling its fit() method. Everything else remained the same.
Since your train.py file changed, its MD5 hash has changed. DVC will realize that one of the pipeline stages needs to be reproduced. You can check what changed with the dvc status command:
$ dvc status
train:
changed deps:
modified: src/train.py
This will display all the changed dependencies for every stage of the pipeline. Since the change in the model will affect the metric as well, you want to reproduce the whole chain. You can reproduce any DVC pipeline file with the dvc repro command:
Et c'est tout! When you run the repro command, DVC checks all the dependencies of the entire pipeline to determine what’s changed and which commands need to be executed again. Think about what this means. You can jump from branch to branch and reproduce any experiment with a single command!
To wrap up, push your random forest classifier code to GitHub and the model to DVC:
$ git add --all
$ git commit -m "Train Random Forrest classifier"
$ dvc commit
$ git push --set-upstream origin random-forest
$ git tag -a random-forest -m "Random Forest classifier with 80.99% accuracy."
$ git push origin --tags
$ dvc push
Now you can compare metrics across multiple branches and tags.
Call dvc metrics show avec le -T switch to display metrics across multiple tags:
$ dvc metrics show -T
sgd-pipeline:
metrics/accuracy.json:
accuracy: 0.6996197718631179
forest:
metrics/accuracy.json:
accuracy: 0.8098859315589354
Impressionnant! This gives you a quick way to keep track of what the best-performing experiment was in your repository.
When you come back to this project in six months and don’t remember the details, you can check which setup was the most successful with dvc metrics show -T and reproduce it with dvc repro! Anyone else who wants to reproduce your work can do the same. They’ll just need to take three steps:
- Courir
git cloneougit checkoutto get the code and.dvcfiles. - Get the training data with
dvc checkout. - Reproduce the entire workflow with
dvc repro evaluate.
If they can write a script to fetch the data and create a pipeline stage for it, then they won’t even need step 2.
Nice work! You ran multiple experiments and safely versioned and backed up the data and models. What’s more, you can quickly reproduce each experiment by just getting the necessary code and data and executing a single dvc repro command.
Next Steps
Congratulations on completing the tutorial! You’ve learned how to use data version control in your daily work. If you want to go deeper into optimizing your workflow or learning more about DVC, then this section offers some suggestions.
Remembering to run all the DVC and Git commands at the right time can be a challenge, especially when you’re just getting started. DVC offers the possibility to integrate the two tighter together. Using Git hooks, you can execute DVC commands automatically when you run certain Git commands. Read more about installing Git hooks for DVC in the official docs.
Git and GitHub allow you to track the history of changes for a particular repository. You can see who updated what and when. You can create pull requests to update data. Patterns like these are possible with DVC as well. Have a look at the section on data registries in the DVC docs.
DVC even has a Python API, which means you can call DVC commands in your Python code to access data or models stored in DVC repositories.
Even though this tutorial provides a broad overview of the possibilities of DVC, it’s impossible to cover everything in a single document. You can explore DVC in detail by checking out the official User Guide, Command Reference, and Interactive Tutorials.
Conclusion
You now know how to use DVC to solve problems data scientists have been struggling with for years! For every experiment you run, you can version the data you use and the model you train. You can share training machines with other team members without fear of losing your data or running out of disk space. Your experiments are reproducible, and anyone can repeat what you’ve done.
In this tutorial, you’ve learned how to:
- Use DVC in a workflow similar to Git, with
ajouter,commit, etpushcommands - Share development machines with other team members and save space with symlinks
- Créer experiment pipelines that can be reproduced with
dvc repro
If you’d like to reproduce the examples you saw above, then be sure to download the source code by clicking the following link:
Practice these techniques and you’ll start doing this process automatically. This will allow you to put all your focus into running cool experiments. Bonne chance!
[ad_2]