Python pas cher
Il existe de nombreuses façons de réaliser des applications rapides et réactives. Mise en cache est une approche qui, lorsqu'elle est utilisée correctement, rend les choses beaucoup plus rapides tout en réduisant la charge sur les ressources informatiques. Python functools module est livré avec le @lru_cache decorator, qui vous permet de mettre en cache le résultat de vos fonctions à l'aide du Stratégie le moins récent (LRU). Il s'agit d'une technique simple mais puissante que vous pouvez utiliser pour tirer parti de la puissance de la mise en cache dans votre code.
Dans ce didacticiel, vous apprendrez:
- Quoi stratégies de mise en cache sont disponibles et comment les implémenter en utilisant Décorateurs Python
- Qu'est-ce que Stratégie LRU est et comment ça marche
- Comment améliorer les performances en mettant en cache avec le
@lru_cachedécorateur - Comment étendre les fonctionnalités du
@lru_cachedécorateur et faites-le expirer après une heure précise
À la fin de ce didacticiel, vous comprendrez plus en profondeur le fonctionnement de la mise en cache et comment en tirer parti dans Python.
Bonus gratuit: 5 Réflexions sur la maîtrise de Python, un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour faire passer vos compétences Python au niveau supérieur.
La mise en cache et ses utilisations
Mise en cache est une technique d'optimisation que vous pouvez utiliser dans vos applications pour conserver les données récentes ou souvent utilisées dans des emplacements mémoire dont l'accès est plus rapide ou moins coûteux que leur source.
Imaginez que vous créez une application de lecture d’actualités qui récupère les dernières actualités de différentes sources. Au fur et à mesure que l'utilisateur navigue dans la liste, votre application télécharge les articles et les affiche à l'écran.
Que se passerait-il si l'utilisateur décidait de se déplacer à plusieurs reprises entre deux articles de presse? À moins que vous ne mettiez en cache les données, votre application devrait récupérer le même contenu à chaque fois! Cela rendrait le système de votre utilisateur lent et exercerait une pression supplémentaire sur le serveur hébergeant les articles.
Une meilleure approche serait de stocker le contenu localement après avoir récupéré chaque article. Ensuite, la prochaine fois que l'utilisateur a décidé d'ouvrir un article, votre application pourrait ouvrir le contenu à partir d'une copie stockée localement au lieu de revenir à la source. En informatique, cette technique s'appelle mise en cache.
Implémentation d'un cache à l'aide d'un dictionnaire Python
Vous pouvez implémenter une solution de mise en cache en Python à l'aide d'un dictionnaire.
En conservant l'exemple du lecteur de nouvelles, au lieu d'aller directement sur le serveur chaque fois que vous devez télécharger un article, vous pouvez vérifier si vous avez le contenu dans votre cache et revenir au serveur uniquement si vous ne l'avez pas. Vous pouvez utiliser l'URL de l'article comme clé et son contenu comme valeur.
Voici un exemple de ce à quoi pourrait ressembler cette technique de mise en cache:
1importer demandes
2
3cache = dict()
4
5def get_article_from_server(URL):
6 impression("Récupération de l'article sur le serveur ...")
sept réponse = demandes.avoir(URL)
8 revenir réponse.texte
9
dixdef get_article(URL):
11 impression("Obtention de l'article ...")
12 si URL ne pas dans cache:
13 cache[[[[URL] = get_article_from_server(URL)
14
15 revenir cache[[[[URL]
16
17get_article("https://realpython.com/sorting-algorithms-python/")
18get_article("https://realpython.com/sorting-algorithms-python/")
Enregistrez ce code dans un caching.py fichier, installez le demandes bibliothèque, puis exécutez le script:
$ demandes d'installation de pip
$ python caching.py
Obtention de l'article ...
Récupération de l'article sur le serveur ...
Obtention de l'article ...
Remarquez comment vous obtenez la chaîne "Récupération de l'article sur le serveur ..." imprimé une seule fois malgré l'appel get_article () deux fois, aux lignes 17 et 18. Cela se produit car, après avoir accédé à l'article pour la première fois, vous mettez son URL et son contenu dans le cache dictionnaire. La deuxième fois, le code n'a pas besoin de récupérer à nouveau l'élément sur le serveur.
Stratégies de mise en cache
Il y a un gros problème avec cette implémentation du cache: le contenu du dictionnaire augmentera indéfiniment! Au fur et à mesure que l'utilisateur télécharge plus d'articles, l'application continue de les stocker en mémoire, ce qui finit par provoquer le blocage de l'application.
Pour contourner ce problème, vous avez besoin d'une stratégie pour décider quels articles doivent rester en mémoire et lesquels doivent être supprimés. Ces stratégies de mise en cache sont des algorithmes qui se concentrent sur la gestion des informations mises en cache et sur le choix des éléments à supprimer pour faire de la place pour de nouveaux.
Il existe plusieurs stratégies différentes que vous pouvez utiliser pour expulser des éléments du cache et l'empêcher de dépasser sa taille maximale. Voici cinq des plus populaires, avec une explication du moment où chacun est le plus utile:
| Stratégie | Politique d'expulsion | Cas d'utilisation |
|---|---|---|
| Premier entré / premier sorti (FIFO) | Expulse la plus ancienne des entrées | Les nouvelles entrées sont les plus susceptibles d'être réutilisées |
| Dernier entré / premier sorti (LIFO) | Expulse la dernière des entrées | Les entrées plus anciennes sont les plus susceptibles d'être réutilisées |
| Le moins récemment utilisé (LRU) | Expulse l'entrée la moins récemment utilisée | Les entrées récemment utilisées sont les plus susceptibles d'être réutilisées |
| Récemment utilisé (MRU) | Expulse l'entrée la plus récemment utilisée | Les entrées les moins récemment utilisées sont les plus susceptibles d'être réutilisées |
| Le moins fréquemment utilisé (LFU) | Expulse l'entrée la moins consultée | Les entrées avec beaucoup d'appels sont plus susceptibles d'être réutilisées |
Dans les sections ci-dessous, vous examinerez de plus près la stratégie LRU et comment la mettre en œuvre à l'aide du @lru_cache décorateur de Python functools module.
Plonger dans la stratégie de cache le moins récemment utilisé (LRU)
Un cache implémenté à l'aide de la stratégie LRU organise ses éléments par ordre d'utilisation. Chaque fois que vous accédez à une entrée, l'algorithme LRU la déplace vers le haut du cache. De cette façon, l'algorithme peut identifier rapidement l'entrée qui est restée inutilisée le plus longtemps en regardant en bas de la liste.
La figure suivante montre une représentation hypothétique du cache une fois que votre utilisateur a demandé un article au réseau:

Notez comment le cache stocke l'article dans l'emplacement le plus récent avant de le servir à l'utilisateur. La figure suivante montre ce qui se passe lorsque l'utilisateur demande un deuxième article:

Le deuxième article prend l'emplacement le plus récent, poussant le premier article vers le bas de la liste.
La stratégie LRU suppose que plus un objet a été utilisé récemment, plus il sera probablement nécessaire à l'avenir, donc il essaie de garder cet objet dans le cache le plus longtemps.
Jetant un coup d'œil dans les coulisses du cache LRU
Une façon d'implémenter un cache LRU en Python consiste à utiliser une combinaison d'une liste doublement liée et d'une carte de hachage. le élément de tête de la liste doublement liée pointerait vers l'entrée la plus récemment utilisée, et le queue indiquerait l'entrée la moins récemment utilisée.
La figure ci-dessous montre la structure potentielle de l'implémentation du cache LRU dans les coulisses:
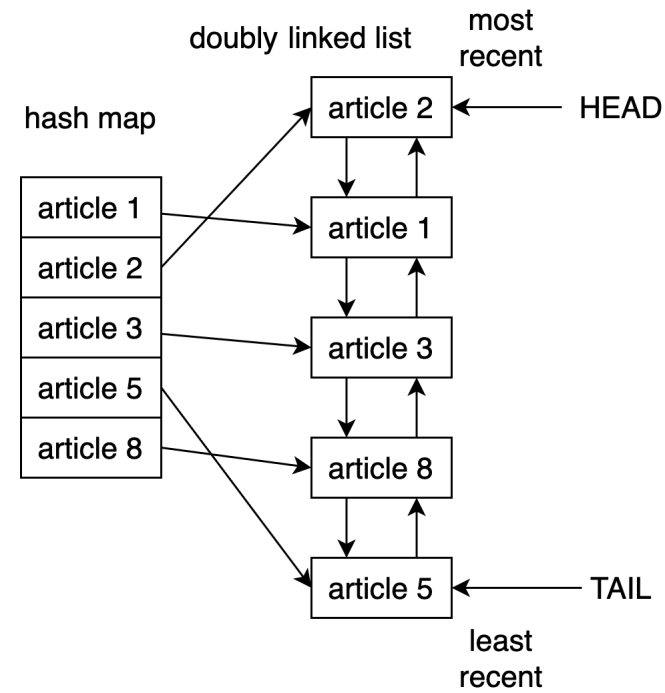
À l'aide de la carte de hachage, vous pouvez garantir l'accès à chaque élément du cache en mappant chaque entrée à l'emplacement spécifique dans la liste à double liaison.
Cette stratégie est très rapide. L'accès à l'élément le moins récemment utilisé et la mise à jour du cache sont des opérations avec un runtime de O(1).
Depuis la version 3.2, Python a inclus le @lru_cache décorateur pour la mise en œuvre de la stratégie LRU. Vous pouvez utiliser ce décorateur pour encapsuler des fonctions et mettre en cache leurs résultats jusqu'à un nombre maximum d'entrées.
Utilisation de @lru_cache pour implémenter un cache LRU en Python
Tout comme la solution de mise en cache que vous avez implémentée précédemment, @lru_cache utilise un dictionnaire dans les coulisses. Il met en cache le résultat de la fonction sous une clé qui consiste en l’appel de la fonction, y compris les arguments fournis. Ceci est important car cela signifie que ces arguments doivent être hashable pour que le décorateur travaille.
Jouer avec les escaliers
Imaginez que vous souhaitiez déterminer toutes les différentes façons dont vous pouvez atteindre un escalier spécifique dans un escalier en sautant un, deux ou trois escaliers à la fois. Combien de chemins y a-t-il au quatrième escalier? Voici toutes les différentes combinaisons:

Vous pouvez encadrer une solution à ce problème en indiquant que, pour atteindre votre escalier actuel, vous pouvez sauter d'un escalier, de deux escaliers ou de trois escaliers plus bas. L'addition du nombre de combinaisons de sauts que vous pouvez utiliser pour atteindre chacun de ces points devrait vous donner le nombre total de façons possibles d'atteindre votre position actuelle.
Par exemple, le nombre de combinaisons pour atteindre le quatrième escalier sera égal au nombre total de manières différentes d'atteindre le troisième, le deuxième et le premier escalier:

Comme le montre l'image, il existe sept façons différentes d'atteindre le quatrième escalier. Remarquez comment la solution pour un escalier donné s'appuie sur les réponses à des sous-problèmes plus petits. Dans ce cas, pour déterminer les différents chemins menant au quatrième escalier, vous pouvez additionner les trois façons d'atteindre le troisième escalier, les deux façons d'atteindre le deuxième escalier et la seule façon d'atteindre le premier escalier.
Cette approche s'appelle récursivité. Si vous souhaitez en savoir plus, consultez Penser récursivement en Python pour une introduction au sujet.
Voici une fonction qui implémente cette récursivité:
1def étapes_à(escalier):
2 si escalier == 1:
3 # Vous pouvez accéder au premier escalier avec une seule marche
4 # du sol.
5 revenir 1
6 elif escalier == 2:
sept # Vous pouvez accéder au deuxième escalier en sautant du
8 # étage avec un seul saut de deux marches ou en sautant un seul
9 # escalier plusieurs fois.
dix revenir 2
11 elif escalier == 3:
12 # Vous pouvez atteindre le troisième escalier en utilisant quatre
13 # combinaisons:
14 # 1. Sauter du sol
15 # 2. Sauter deux escaliers, puis un
16 # 3. Sauter un escalier, puis deux
17 # 4. Sauter un escalier trois fois
18 revenir 4
19 autre:
20 # Vous pouvez accéder à votre escalier actuel depuis trois endroits différents:
21 # 1. De trois marches plus bas
22 # 2. De deux marches plus bas
23 # 2. D'un escalier vers le bas
24 #
25 # Si vous additionnez le nombre de façons d'y accéder
26 # ces trois positions, alors vous devriez avoir votre solution.
27 revenir (
28 étapes_à(escalier - 3)
29 + étapes_à(escalier - 2)
30 + étapes_à(escalier - 1)
31 )
32
33impression(étapes_à(4))
Enregistrez ce code dans un fichier nommé escaliers.py et exécutez-le avec la commande suivante:
Génial! Le code fonctionne pour 4 escaliers, mais que diriez-vous de compter combien de marches pour atteindre une place plus élevée dans l'escalier? Remplacez le numéro de l'escalier de la ligne 33 par 30 et relancez le script:
$ escaliers en python.py
53798080
Wow, plus de 53 millions de combinaisons! C’est beaucoup de houblon!
Chronométrage de votre code
Lors de la recherche de la solution pour le trentième escalier, le script a mis un peu de temps à se terminer. Pour obtenir une référence, vous pouvez mesurer le temps nécessaire à l'exécution du code.
Pour ce faire, vous pouvez utiliser Python timeit module. Ajoutez les lignes suivantes après la ligne 33:
35setup_code = "de __main__ importer les étapes_à"
36stmt = "étapes_à (30)"
37fois = répéter(installer=setup_code, stmt=stmt, répéter=3, nombre=dix)
38impression(F"Temps d'exécution minimum: min(fois)")
Vous devez également importer le timeit module en haut du code:
1de timeit importer répéter
Voici une explication ligne par ligne de ces ajouts:
- Ligne 35 importe le nom de
étapes_à ()pour quetimeit.repeat ()sait comment l'appeler. - Ligne 36 prépare l'appel à la fonction avec le numéro de l'escalier que vous souhaitez atteindre, qui dans ce cas est
30. C'est l'instruction qui sera exécutée et chronométrée. - Ligne 37 appels
timeit.repeat ()avec le code de configuration et l'instruction. Cela appellera la fonctiondixfois, renvoyant le nombre de secondes que chaque exécution a pris. - Ligne 38 identifie et imprime le temps le plus court renvoyé.
Remarque: Une idée fausse courante est que vous devriez trouver le temps moyen de chaque exécution de la fonction au lieu de sélectionner le temps le plus court.
Les mesures de temps sont bruyantes car le système exécute d'autres processus simultanément. Le temps le plus court est toujours le moins bruyant, ce qui en fait la meilleure représentation du runtime de la fonction.
Maintenant, exécutez à nouveau le script:
$ escaliers en python.py
53798080
Temps d'exécution minimum: 40.014977024000004
Le nombre de secondes que vous verrez dépend de votre matériel spécifique. Sur mon système, le script a pris quarante secondes, ce qui est assez lent pour seulement trente marches!
Une solution qui prend autant de temps est un problème, mais vous pouvez l'améliorer à l'aide de la mémorisation.
Utilisation de la mémorisation pour améliorer la solution
Cette implémentation récursive résout le problème en le divisant en étapes plus petites qui s'appuient les unes sur les autres. La figure suivante montre une arborescence dans laquelle chaque nœud représente un appel spécifique à étapes_à ():

Remarquez comment vous devez appeler étapes_à () avec le même argument plusieurs fois. Par exemple, étapes_à (5) est calculé deux fois, étapes_à (4) est calculé quatre fois, étapes_à (3) sept fois, et étapes_à (2) six fois. Appeler la même fonction plusieurs fois ajoute des cycles de calcul qui ne sont pas nécessaires – le résultat sera toujours le même.
Pour résoudre ce problème, vous pouvez utiliser une technique appelée mémorisation. Cette approche garantit qu’une fonction ne s’exécute pas plus d’une fois pour les mêmes entrées en stockant son résultat en mémoire, puis en le référençant ultérieurement si nécessaire. Ce scénario semble être l’occasion idéale d’utiliser Python @lru_cache décorateur!
Remarque: Pour plus d'informations sur mémorisation et en utilisant @lru_cache pour l'implémenter, consultez Memoization in Python.
Avec seulement deux changements, vous pouvez considérablement améliorer le temps d'exécution de l'algorithme:
- Importez le
@lru_cachedécorateur dufunctoolsmodule. - Utilisation
@lru_cachedécorerétapes_à ().
Voici à quoi ressemblera le haut du script avec les deux mises à jour:
1de functools importer lru_cache
2de timeit importer répéter
3
4@lru_cache
5def étapes_à(escalier):
6 si escalier == 1:
L'exécution du script mis à jour produit le résultat suivant:
$ escaliers en python.py
53798080
Temps d'exécution minimum: 7,999999999987184e-07
La mise en cache du résultat de la fonction fait passer le temps d'exécution de 40 secondes à 0,0008 millisecondes! C’est une amélioration fantastique!
Remarque: Dans Python 3.8 et supérieur, vous pouvez utiliser le @lru_cache décorateur sans parenthèses si vous ne spécifiez aucun paramètre. Dans les versions précédentes, vous devrez peut-être inclure les parenthèses: @lru_cache ().
Rappelez-vous, dans les coulisses, le @lru_cache le décorateur stocke le résultat de étapes_à () pour chaque entrée différente. Chaque fois que le code appelle la fonction avec les mêmes paramètres, au lieu de calculer à nouveau une réponse, il renvoie le résultat correct directement à partir de la mémoire. Cela explique l'amélioration massive des performances lors de l'utilisation @lru_cache.
Déballage des fonctionnalités de @lru_cache
Avec le @lru_cache décorateur en place, vous stockez chaque appel et répondez en mémoire pour y accéder plus tard si demandé à nouveau. Mais combien d'appels pouvez-vous enregistrer avant de manquer de mémoire?
Python @lru_cache décorateur propose un taille max attribut qui définit le nombre maximal d'entrées avant que le cache ne commence à expulser les anciens éléments. Par défaut, taille max est réglé sur 128. Si vous définissez taille max à Aucun, alors le cache augmentera indéfiniment et aucune entrée ne sera jamais expulsée. Cela peut devenir un problème si vous stockez un grand nombre d'appels différents en mémoire.
Voici un exemple de @lru_cache en utilisant le taille max attribut:
1de functools importer lru_cache
2de timeit importer répéter
3
4@lru_cache(taille max=16)
5def étapes_à(escalier):
6 si escalier == 1:
Dans ce cas, vous limitez le cache à un maximum de 16 entrées. Lorsqu'un nouvel appel arrive, la mise en œuvre du décorateur expulsera le moins récemment utilisé de l'existant 16 entrées pour faire une place pour le nouvel élément.
Pour voir ce qui se passe avec ce nouvel ajout au code, vous pouvez utiliser cache_info (), fourni par le @lru_cache décorateur, pour inspecter le nombre de les coups et manque et la taille actuelle du cache. Pour plus de clarté, supprimez le code qui multiplie le temps d'exécution de la fonction. Voici à quoi ressemble le script final après toutes les modifications:
1de functools importer lru_cache
2de timeit importer répéter
3
4@lru_cache(taille max=16)
5def étapes_à(escalier):
6 si escalier == 1:
sept # Vous pouvez accéder au premier escalier avec une seule marche
8 # du sol.
9 revenir 1
dix elif escalier == 2:
11 # Vous pouvez accéder au deuxième escalier en sautant du
12 # étage avec un seul saut de deux marches ou en sautant un seul
13 # escalier plusieurs fois.
14 revenir 2
15 elif escalier == 3:
16 # Vous pouvez atteindre le troisième escalier en utilisant quatre
17 # combinaisons:
18 # 1. Sauter du sol
19 # 2. Sauter deux escaliers, puis un
20 # 3. Sauter un escalier, puis deux
21 # 4. Sauter un escalier trois fois
22 revenir 4
23 autre:
24 # Vous pouvez accéder à votre escalier actuel depuis trois endroits différents:
25 # 1. De trois marches plus bas
26 # 2. De deux marches plus bas
27 # 2. D'un escalier vers le bas
28 #
29 # Si vous additionnez le nombre de façons d'y accéder
30 # ces trois positions, alors vous devriez avoir votre solution.
31 revenir (
32 étapes_à(escalier - 3)
33 + étapes_à(escalier - 2)
34 + étapes_à(escalier - 1)
35 )
36
37impression(étapes_à(30))
38
39impression(étapes_à.cache_info())
Si vous appelez à nouveau le script, vous verrez le résultat suivant:
$ escaliers en python.py
53798080
CacheInfo (hits = 52, échecs = 30, maxsize = 16, currsize = 16)
Vous pouvez utiliser les informations renvoyées par cache_info () pour comprendre les performances du cache et l'ajuster pour trouver l'équilibre approprié entre la vitesse et le stockage.
Voici une liste des propriétés fournies par cache_info ():
-
coups = 52est le nombre d'appels@lru_cacherenvoyés directement de la mémoire car ils existaient dans le cache. -
manque = 30est le nombre d'appels qui ne proviennent pas de la mémoire et qui ont été calculés. Étant donné que vous essayez de trouver le nombre de marches pour atteindre le trentième escalier, il est logique que chacun de ces appels ait manqué le cache la première fois qu'il a été effectué. -
maxsize = 16est la taille du cache tel que vous l'avez défini avec letaille maxattribut du décorateur. -
currsize = 16est la taille actuelle du cache. Dans ce cas, cela montre que votre cache est plein.
Si vous devez supprimer toutes les entrées du cache, vous pouvez utiliser cache_clear () fourni par @lru_cache.
Ajout de l'expiration du cache
Imaginez que vous vouliez développer un script qui surveille Vrai Python et imprime le nombre de caractères de tout article contenant le mot python.
Vrai Python fournit un flux Atom, vous pouvez donc utiliser le analyseur d'alimentation bibliothèque pour analyser le flux et le demandes bibliothèque pour charger le contenu de l'article comme vous l'avez fait auparavant.
Voici une implémentation du script de surveillance:
1importer analyseur d'alimentation
2importer demandes
3importer ssl
4importer temps
5
6si hasattr(ssl, "_create_unverified_context"):
sept ssl._create_default_https_context = ssl._create_unverified_context
8
9def get_article_from_server(URL):
dix impression("Récupération de l'article sur le serveur ...")
11 réponse = demandes.avoir(URL)
12 revenir réponse.texte
13
14def moniteur(URL):
15 Maxlen = 45
16 tandis que Vrai:
17 impression(" nVérification du flux ... ")
18 alimentation = analyseur d'alimentation.analyser(URL)
19
20 pour entrée dans alimentation.entrées[:[:[:[:5]:
21 si "python" dans entrée.Titre.inférieur():
22 truncated_title = (
23 entrée.Titre[:[:[:[:Maxlen] + "..."
24 si len(entrée.Titre) > Maxlen
25 autre entrée.Titre
26 )
27 impression(
28 "Correspondance trouvée:",
29 truncated_title,
30 len(get_article_from_server(entrée.lien)),
31 )
32
33 temps.sommeil(5)
34
35moniteur("https://realpython.com/atom.xml")
Enregistrez ce script dans un fichier appelé monitor.py, installez le analyseur d'alimentation et demandes bibliothèques et exécutez le script. Il fonctionnera en continu jusqu'à ce que vous l'arrêtiez en appuyant sur Ctrl+C dans la fenêtre de votre terminal:
$ pip installer les demandes de feedparser
$ python monitor.py
Vérification du flux ...
Récupération de l'article sur le serveur ...
Podcast Real Python - Épisode # 28: Utilisation de ... 29520
Récupération de l'article sur le serveur ...
Entretien de la communauté Python avec David Amos 54256
Récupération de l'article sur le serveur ...
Utilisation de listes liées dans Python 37099
Récupération de l'article sur le serveur ...
Problèmes de pratique Python: préparez-vous pour votre ... 164888
Récupération de l'article sur le serveur ...
Podcast Real Python - Épisode # 27: Préparez ... 30784
Vérification du flux ...
Récupération de l'article sur le serveur ...
Podcast Real Python - Épisode # 28: Utilisation de ... 29520
Récupération de l'article sur le serveur ...
Entretien de la communauté Python avec David Amos 54256
Récupération de l'article sur le serveur ...
Utilisation de listes liées dans Python 37099
Récupération de l'article sur le serveur ...
Problèmes de pratique Python: préparez-vous pour votre ... 164888
Récupération de l'article sur le serveur ...
Podcast Real Python - Épisode # 27: Préparez ... 30784
Voici une explication étape par étape du code:
- Lignes 6 et 7: Il s'agit d'une solution de contournement à un problème lorsque
analyseur d'alimentationtente d'accéder au contenu diffusé via HTTPS. Voir la note ci-dessous pour plus d'informations. - Ligne 16:
moniteur()boucle indéfiniment. - Ligne 18: En utilisant
analyseur d'alimentation, le code charge et analyse le flux de Vrai Python. - Ligne 20: La boucle passe par le premier
5entrées de la liste. - Lignes 21 à 31: Si le mot
pythonfait partie du titre, puis le code l'imprime avec la longueur de l'article. - Ligne 33: Le code dort pendant
5secondes avant de continuer. - Ligne 35: Cette ligne lance le processus de surveillance en transmettant l'URL du Vrai Python alimenter
moniteur().
Chaque fois que le script charge un article, le message "Récupération de l'article sur le serveur ..." est imprimé sur la console. Si vous laissez le script s'exécuter suffisamment longtemps, vous verrez comment ce message s'affiche à plusieurs reprises, même lors du chargement du même lien.
Remarque: Pour plus d'informations sur le problème avec analyseur d'alimentation accéder au contenu servi via HTTPS, consultez le numéro 84 sur le analyseur d'alimentation dépôt. PEP 476 décrit comment Python a commencé à activer la vérification de certificat par défaut pour stdlib Clients HTTP, qui est la cause sous-jacente de cette erreur.
Il s'agit d'une excellente occasion de mettre en cache le contenu de l'article et d'éviter de toucher le réseau toutes les cinq secondes. Vous pouvez utiliser le @lru_cache décorateur, mais que se passe-t-il si le contenu de l'article est mis à jour?
La première fois que vous accédez à l'article, le décorateur stocke son contenu et renvoie les mêmes données à chaque fois par la suite. Si la publication est mise à jour, le script du moniteur ne s'en rendra jamais compte car il extraira l'ancienne copie stockée dans le cache. Pour résoudre ce problème, vous pouvez définir l'expiration de vos entrées de cache.
Expulsion des entrées du cache en fonction à la fois du temps et de l'espace
le @lru_cache Decorator supprime les entrées existantes uniquement lorsqu'il n'y a plus d'espace pour stocker de nouvelles fiches. Avec un espace suffisant, les entrées du cache vivront éternellement et ne seront jamais actualisées.
Cela pose un problème pour votre script de surveillance, car vous ne récupérerez jamais les mises à jour publiées pour les articles précédemment mis en cache. Pour contourner ce problème, vous pouvez mettre à jour l'implémentation du cache afin qu'elle expire après une heure spécifique.
Vous pouvez mettre en œuvre cette idée dans un nouveau décorateur qui prolonge @lru_cache. Si l'appelant tente d'accéder à un élément qui a dépassé sa durée de vie, le cache ne renvoie pas son contenu, ce qui oblige l'appelant à récupérer l'article sur le réseau.
Voici une implémentation possible de ce nouveau décorateur:
1de functools importer lru_cache, enveloppements
2de datetime importer datetime, timedelta
3
4def timed_lru_cache(secondes: int, taille max: int = 128):
5 def wrapper_cache(func):
6 func = lru_cache(taille max=taille max) (func)
sept func.durée de vie = timedelta(secondes=secondes)
8 func.expiration = datetime.utcnow() + func.durée de vie
9
dix @wraps(func)
11 def wrapped_func(*args, **kwargs):
12 si datetime.utcnow() > = func.expiration:
13 func.cache_clear()
14 func.expiration = datetime.utcnow() + func.durée de vie
15
16 revenir func(*args, **kwargs)
17
18 revenir wrapped_func
19
20 revenir wrapper_cache
Voici un aperçu de cette mise en œuvre:
- Ligne 4: Le
@timed_lru_cachedecorator prendra en charge la durée de vie des entrées dans le cache (en secondes) et la taille maximale du cache. - Ligne 6: Le code encapsule la fonction décorée avec le
lru_cachedécorateur. Cela vous permet d'utiliser la fonctionnalité de cache déjà fournie parlru_cache. - Lignes 7 et 8: Ces deux lignes instrumentent la fonction décorée avec deux attributs représentant la durée de vie du cache et la date réelle à laquelle il expirera.
- Lignes 12 à 14: Avant d'accéder à une entrée dans le cache, le décorateur vérifie si la date actuelle est passée la date d'expiration. Si tel est le cas, il efface le cache et recalcule la durée de vie et la date d'expiration.
Remarquez comment, lorsqu'une entrée est expirée, ce décorateur efface tout le cache associé à la fonction. La durée de vie s'applique au cache dans son ensemble, pas aux articles individuels. Une mise en œuvre plus sophistiquée de cette stratégie expulserait les entrées en fonction de leur durée de vie individuelle.
Mise en cache d'articles avec le nouveau décorateur
Vous pouvez maintenant utiliser votre nouveau @timed_lru_cache décorateur avec le moniteur script pour éviter de récupérer le contenu d'un article à chaque fois que vous y accédez.
En rassemblant le code dans un seul script pour plus de simplicité, vous vous retrouvez avec ce qui suit:
1importer analyseur d'alimentation
2importer demandes
3importer ssl
4importer temps
5
6de functools importer lru_cache, enveloppements
septde datetime importer datetime, timedelta
8
9si hasattr(ssl, "_create_unverified_context"):
dix ssl._create_default_https_context = ssl._create_unverified_context
11
12def timed_lru_cache(secondes: int, taille max: int = 128):
13 def wrapper_cache(func):
14 func = lru_cache(taille max=taille max) (func)
15 func.durée de vie = timedelta(secondes=secondes)
16 func.expiration = datetime.utcnow() + func.durée de vie
17
18 @wraps(func)
19 def wrapped_func(*args, **kwargs):
20 si datetime.utcnow() > = func.expiration:
21 func.cache_clear()
22 func.expiration = datetime.utcnow() + func.durée de vie
23
24 revenir func(*args, **kwargs)
25
26 revenir wrapped_func
27
28 revenir wrapper_cache
29
30@timed_lru_cache(dix)
31def get_article_from_server(URL):
32 impression("Récupération de l'article sur le serveur ...")
33 réponse = demandes.avoir(URL)
34 revenir réponse.texte
35
36def moniteur(URL):
37 Maxlen = 45
38 tandis que Vrai:
39 impression(" nVérification du flux ... ")
40 alimentation = analyseur d'alimentation.analyser(URL)
41
42 pour entrée dans alimentation.entrées[:[:[:[:5]:
43 si "python" dans entrée.Titre.inférieur():
44 truncated_title = (
45 entrée.Titre[:[:[:[:Maxlen] + "..."
46 si len(entrée.Titre) > Maxlen
47 autre entrée.Titre
48 )
49 impression(
50 "Correspondance trouvée:",
51 truncated_title,
52 len(get_article_from_server(entrée.lien)),
53 )
54
55 temps.sommeil(5)
56
57moniteur("https://realpython.com/atom.xml")
Remarquez comment la ligne 30 décore get_article_from_server () avec le @timed_lru_cache et spécifie une validité de dix secondes. Toute tentative d'accès au même article depuis le serveur dans dix secondes après l'avoir récupéré, le contenu du cache sera renvoyé et ne touchera jamais le réseau.
Exécutez le script et regardez les résultats:
$ python monitor.py
Vérification du flux ...
Récupération de l'article sur le serveur ...
Correspondance trouvée: Podcast Real Python - Episode # 28: Utilisation de ... 29521
Récupération de l'article sur le serveur ...
Correspondance trouvée: Entretien de la communauté Python avec David Amos 54254
Récupération de l'article sur le serveur ...
Correspondance trouvée: utilisation de listes liées dans Python 37100
Récupération de l'article sur le serveur ...
Correspondance trouvée: Python Practice Problems: Get Ready for Your ... 164887
Récupération de l'article sur le serveur ...
Match trouvé: Podcast Real Python - Episode # 27: Prepar ... 30783
Vérification du flux ...
Correspondance trouvée: Podcast Real Python - Episode # 28: Utilisation de ... 29521
Correspondance trouvée: Entretien de la communauté Python avec David Amos 54254
Correspondance trouvée: utilisation de listes liées dans Python 37100
Correspondance trouvée: Python Practice Problems: Get Ready for Your ... 164887
Match trouvé: Podcast Real Python - Episode # 27: Prepar ... 30783
Vérification du flux ...
Correspondance trouvée: Podcast Real Python - Episode # 28: Utilisation de ... 29521
Correspondance trouvée: Entretien de la communauté Python avec David Amos 54254
Correspondance trouvée: utilisation de listes liées dans Python 37100
Correspondance trouvée: Python Practice Problems: Get Ready for Your ... 164887
Match trouvé: Le vrai podcast Python - Episode # 27: Préparez ... 30783
Vérification du flux ...
Récupération de l'article sur le serveur ...
Correspondance trouvée: Podcast Real Python - Episode # 28: Utilisation de ... 29521
Récupération de l'article sur le serveur ...
Correspondance trouvée: Interview de la communauté Python avec David Amos 54254
Récupération de l'article sur le serveur ...
Correspondance trouvée: utilisation de listes liées dans Python 37099
Récupération de l'article sur le serveur ...
Correspondance trouvée: Python Practice Problems: Get Ready for Your ... 164888
Récupération de l'article sur le serveur ...
Match trouvé: Le vrai podcast Python - Episode # 27: Préparez ... 30783
Remarquez comment le code imprime le message "Récupération de l'article sur le serveur ..." la première fois qu'il accède aux articles correspondants. Après cela, en fonction de la vitesse de votre réseau et de la puissance de calcul, le script récupérera les articles du cache une ou deux fois avant de toucher à nouveau le serveur.
Le script essaie d'accéder aux articles tous les 5 secondes et le cache expire toutes les dix secondes. Ces délais sont probablement trop courts pour une application réelle, vous pouvez donc obtenir une amélioration significative en ajustant ces configurations.
Conclusion
La mise en cache est une technique d'optimisation essentielle pour améliorer les performances de tout système logiciel. Understanding how caching works is a fundamental step toward incorporating it effectively in your applications.
In this tutorial, you learned:
- What the different caching strategies are and how they work
- How to use Python’s
@lru_cachedecorator - How to create a new decorator to extend the functionality of
@lru_cache - How to measure your code’s runtime using the
timeitmodule - What recursion is and how to solve a problem using it
- How memoization improves runtime by storing intermediate results in memory
The next step to implementing different caching strategies in your applications is looking at the cachetools module. This library provides several collections and decorators covering some of the most popular caching strategies that you can start using right away.
[ad_2]