Cours Python en ligne
- Qu'est-ce que le commerce sans tête et comment peut-il vous être bénéfique?
- astuce: dictionnaire get () fonctionne comme getattr
- Pourquoi la plupart des tests unitaires sont-ils des déchets?
- Épisode n ° 42: Python dans les start-ups et investissement
- 5 conseils essentiels sur la comptabilité WooCommerce
Listes liées sont comme un cousin de listes moins connu. Ils ne sont pas aussi populaires ou aussi cool, et vous ne vous en souvenez peut-être même pas dans votre classe d'algorithmes. Mais dans le bon contexte, ils peuvent vraiment briller.
Dans cet article, vous apprendrez:
- Que sont les listes chaînées et quand les utiliser
- Comment utiliser
collections.dequepour tous vos besoins de liste chaînée - Comment implémenter vos propres listes chaînées
- Quels sont les autres types de listes chaînées et à quoi peuvent-ils servir
Si vous cherchez à perfectionner vos compétences en codage pour un entretien d'embauche, ou si vous souhaitez en savoir plus sur les structures de données Python en plus des dictionnaires et des listes habituels, alors vous êtes au bon endroit!
Vous pouvez suivre les exemples de ce tutoriel en téléchargeant le code source disponible sur le lien ci-dessous:
Comprendre les listes liées
Les listes liées sont une collection ordonnée d'objets. Alors, qu'est-ce qui les différencie des listes normales? Les listes liées diffèrent des listes par la façon dont elles stockent les éléments en mémoire. Alors que les listes utilisent un bloc de mémoire contigu pour stocker les références à leurs données, les listes liées stockent les références dans le cadre de leurs propres éléments.
Concepts principaux
Avant d'approfondir ce que sont les listes chaînées et comment les utiliser, vous devez d'abord apprendre comment elles sont structurées. Chaque élément d'une liste chaînée est appelé nœudet chaque nœud a deux champs différents:
- Les données contient la valeur à stocker dans le nœud.
- Prochain contient une référence au nœud suivant de la liste.
Voici à quoi ressemble un nœud typique:

Une liste liée est une collection de nœuds. Le premier nœud est appelé tête, et il est utilisé comme point de départ pour toute itération dans la liste. Le dernier nœud doit avoir son suivant référence pointant vers Aucun pour déterminer la fin de la liste. Voici à quoi ça ressemble:

Maintenant que vous savez comment une liste chaînée est structurée, vous êtes prêt à examiner quelques cas d'utilisation pratiques.
Applications pratiques
Les listes liées servent à diverses fins dans le monde réel. Ils peuvent être utilisés pour implémenter (alerte spoil!) des files d'attente ou des piles ainsi que des graphiques. Ils sont également utiles pour des tâches beaucoup plus complexes, telles que la gestion du cycle de vie d'une application de système d'exploitation.
Files d'attente ou piles
Les files d'attente et les piles ne diffèrent que par la façon dont les éléments sont récupérés. Pour une file d'attente, vous utilisez un Premier entré, premier sorti (FIFO). Cela signifie que le premier élément inséré dans la liste est le premier à être récupéré:

Dans le diagramme ci-dessus, vous pouvez voir le de face et arrière éléments de la file d'attente. Lorsque vous ajoutez de nouveaux éléments à la file d'attente, ils iront à l'arrière. Lorsque vous récupérez des éléments, ils sont extraits de l'avant de la file d'attente.
Pour une pile, vous utilisez un Last-In / Fist-Out (LIFO), ce qui signifie que le dernier élément inséré dans la liste est le premier à être récupéré:

Dans le diagramme ci-dessus, vous pouvez voir que le premier élément inséré sur la pile (index 0) est en bas et le dernier élément inséré est en haut. Comme les piles utilisent l'approche LIFO, le dernier élément inséré (en haut) sera le premier à être récupéré.
En raison de la façon dont vous insérez et récupérez des éléments à partir des bords des files d'attente et des piles, les listes liées sont l'un des moyens les plus pratiques pour implémenter ces structures de données. Vous verrez des exemples de ces implémentations plus loin dans l'article.
Graphiques
Les graphiques peuvent être utilisés pour montrer les relations entre les objets ou pour représenter différents types de réseaux. Par exemple, une représentation visuelle d'un graphique – disons un graphique acyclique dirigé (DAG) – pourrait ressembler à ceci:

Il existe différentes façons d'implémenter des graphiques comme ceux ci-dessus, mais l'une des plus courantes consiste à utiliser un liste de contiguïté. Une liste d'adjacence est, par essence, une liste de listes liées où chaque sommet du graphe est stocké à côté d'une collection de sommets connectés:
| Sommet | Liste des sommets liés |
|---|---|
| 1 | 2 → 3 → Aucun |
| 2 | 4 → Aucun |
| 3 | Aucun |
| 4 | 5 → 6 → Aucun |
| 5 | 6 → Aucun |
| 6 | Aucun |
Dans le tableau ci-dessus, chaque sommet de votre graphique est répertorié dans la colonne de gauche. La colonne de droite contient une série de listes liées stockant les autres sommets connectés au sommet correspondant dans la colonne de gauche. Cette liste de contiguïté pourrait également être représentée dans le code à l'aide d'un dicter:
>>> graphique =
... 1: [[[[2, 3, Aucun],
... 2: [[[[4, Aucun],
... 3: [[[[Aucun],
... 4: [[[[5, 6, Aucun],
... 5: [[[[6, Aucun],
... 6: [[[[Aucun]
...
Les clés de ce dictionnaire sont les sommets source et la valeur de chaque clé est une liste. Cette liste est généralement implémentée en tant que liste liée.
Remarque: Dans l'exemple ci-dessus, vous pouvez éviter de stocker le Aucun valeurs, mais nous les avons conservées ici pour plus de clarté et de cohérence avec des exemples ultérieurs.
En termes de vitesse et de mémoire, la mise en œuvre de graphiques utilisant des listes de contiguïté est très efficace par rapport, par exemple, à un matrice d'adjacence. C'est pourquoi les listes chaînées sont si utiles pour l'implémentation de graphiques.
Comparaison des performances: listes vs listes liées
Dans la plupart des langages de programmation, il existe des différences claires dans la façon dont les listes et les tableaux liés sont stockés en mémoire. En Python, cependant, les listes sont des tableaux dynamiques. Cela signifie que l'utilisation de la mémoire des listes et des listes liées est très similaire.
Lectures complémentaires: L'implémentation de tableaux dynamiques par Python est assez intéressante et mérite vraiment d'être lue. Assurez-vous d'avoir un regard et d'utiliser ces connaissances pour vous démarquer lors de votre prochaine fête d'entreprise!
Étant donné que la différence d'utilisation de la mémoire entre les listes et les listes liées est si insignifiante, il est préférable de vous concentrer sur leurs différences de performances en matière de complexité temporelle.
Insertion et suppression d'éléments
Les temps d'insertion de liste varient en fonction de la nécessité de redimensionner la baie existante. Si vous lisez l'article ci-dessus sur la façon dont les listes sont implémentées, vous remarquerez que Python sur-utilise l'espace pour les tableaux en fonction de leur croissance. Cela signifie que l'insertion d'un nouvel élément dans une liste peut prendre de Θ (n) à Θ (1) selon que la baie existante doit être redimensionnée.
Il en va de même pour la suppression d'éléments du tableau. Si la taille du tableau est inférieure à la moitié de la taille allouée, Python réduira le tableau. Donc, dans l'ensemble, l'insertion ou la suppression d'éléments d'un tableau a une complexité temporelle moyenne de Θ (n).
Les listes liées, cependant, sont bien meilleures lorsqu'il s'agit d'insérer et de supprimer des éléments au début ou à la fin de la liste, où leur complexité temporelle est constante: Θ (1). Cet avantage de performances est la raison pour laquelle les listes liées sont si utiles pour les files d'attente et les piles, où les éléments sont insérés et supprimés en continu des bords.
Récupération des éléments
En ce qui concerne la recherche d'éléments, les listes fonctionnent bien mieux que les listes liées. Lorsque vous savez à quel élément vous souhaitez accéder, les listes peuvent effectuer cette opération dans Θ (1) temps. Essayer de faire de même avec une liste chaînée prendrait Θ (n) car vous devez parcourir toute la liste pour trouver l'élément.
Cependant, lors de la recherche d'un élément spécifique, les listes et les listes liées fonctionnent de manière très similaire, avec une complexité temporelle de Θ (n). Dans les deux cas, vous devez parcourir toute la liste pour trouver l'élément que vous recherchez.
Présentation collections.deque
En Python, il y a un objet spécifique dans le collections module que vous pouvez utiliser pour les listes chaînées appelées deque(prononcé «deck»), qui signifie file d'attente double.
collections.deque utilise une implémentation d'une liste liée dans laquelle vous pouvez accéder, insérer ou supprimer des éléments du début ou de la fin d'une liste avec une constante O (1) performance.
Comment utiliser collections.deque
Il y a pas mal de méthodes qui viennent, par défaut, avec un deque objet. Cependant, dans cet article, vous n'en aborderez que quelques-uns, principalement pour ajouter ou supprimer des éléments.
Tout d'abord, vous devez créer une liste chaînée. Vous pouvez utiliser le morceau de code suivant pour le faire avec deque:
>>> de collections importation deque
>>> deque()
deque ([])
Le code ci-dessus créera une liste chaînée vide. Si vous souhaitez le remplir lors de la création, vous pouvez lui donner un itérable en entrée:
>>> deque([[[['une',«b»,«c»])
deque (['a', 'b', 'c'])
>>> deque('abc')
deque (['a', 'b', 'c'])
>>> deque([{[{[{['Les données': 'une', 'Les données': «b»])
deque (['data': 'a', 'data': 'b'])
Lors de l'initialisation d'un deque , vous pouvez passer n'importe quel itérable en entrée, comme une chaîne (également un itérable) ou une liste d'objets.
Maintenant que vous savez comment créer un deque , vous pouvez interagir avec lui en ajoutant ou en supprimant des éléments. Vous pouvez créer un abcde liste liée et ajouter un nouvel élément F comme ça:
>>> llist = deque("abcde")
>>> llist
deque (['a', 'b', 'c', 'd', 'e'])
>>> llist.ajouter("F")
>>> llist
deque (['a', 'b', 'c', 'd', 'e', 'f'])
>>> llist.pop()
'F'
>>> llist
deque (['a', 'b', 'c', 'd', 'e'])
Tous les deux ajouter() et pop() ajouter ou supprimer des éléments du côté droit de la liste liée. Cependant, vous pouvez également utiliser deque pour ajouter ou supprimer rapidement des éléments du côté gauche, ou tête, de la liste:
>>> llist.appendleft("z")
>>> llist
deque (['z', 'a', 'b', 'c', 'd', 'e'])
>>> llist.popleft()
«z»
>>> llist
deque (['a', 'b', 'c', 'd', 'e'])
L'ajout ou la suppression d'éléments aux deux extrémités de la liste est assez simple en utilisant le deque objet. Vous êtes maintenant prêt à apprendre à utiliser collections.deque pour implémenter une file d'attente ou une pile.
Comment implémenter des files d'attente et des piles
Comme vous l'avez appris ci-dessus, la principale différence entre une file d'attente et une pile est la façon dont vous récupérez les éléments de chacune. Ensuite, vous découvrirez comment utiliser collections.deque pour mettre en œuvre les deux structures de données.
Files d'attente
Avec les files d'attente, vous souhaitez ajouter des valeurs à une liste (mettre en file d'attente), et lorsque le moment est opportun, vous souhaitez supprimer l'élément qui a été le plus longtemps sur la liste (retirer de la file d'attente). Par exemple, imaginez une file d'attente dans un restaurant branché et complet. Si vous tentiez de mettre en place un système équitable pour accueillir les invités, vous devriez commencer par créer une file d'attente et ajouter des personnes à leur arrivée:
>>> de collections importation deque
>>> queue = deque()
>>> queue
deque ([])
>>> queue.ajouter("Marie")
>>> queue.ajouter("John")
>>> queue.ajouter("Susan")
>>> queue
deque (['Mary', 'John', 'Susan'])
Maintenant, vous avez Mary, John et Susan dans la file d'attente. N'oubliez pas que les files d'attente étant FIFO, la première personne qui est entrée dans la file d'attente doit être la première à en sortir.
Imaginez maintenant que le temps passe et que quelques tableaux deviennent disponibles. À ce stade, vous souhaitez supprimer les personnes de la file d'attente dans le bon ordre. Voici comment procéder:
>>> queue.popleft()
'Marie'
>>> queue
deque (['John', 'Susan'])
>>> queue.popleft()
'John'
>>> queue
deque (['Susan'])
Chaque fois que vous appelez popleft (), vous supprimez l'élément head de la liste liée, imitant une file d'attente réelle.
Piles
Et si vous vouliez plutôt créer une pile? Eh bien, l'idée est plus ou moins la même que pour la file d'attente. La seule différence est que la pile utilise l'approche LIFO, ce qui signifie que le dernier élément à insérer dans la pile doit être le premier à être supprimé.
Imaginez que vous créez une fonctionnalité d'historique de navigateur Web dans laquelle stocker chaque page visitée par un utilisateur afin qu'il puisse remonter dans le temps facilement. Supposons que ce sont les actions qu'un utilisateur aléatoire effectue sur son navigateur:
- Visite le site Web de Real Python
- Navigue vers Pandas: comment lire et écrire des fichiers
- Clique sur un lien pour lire et écrire des fichiers CSV en Python
Si vous souhaitez mapper ce comportement dans une pile, vous pouvez faire quelque chose comme ceci:
>>> de collections importation deque
>>> histoire = deque()
>>> histoire.appendleft("https://realpython.com/")
>>> histoire.appendleft("https://realpython.com/pandas-read-write-files/")
>>> histoire.appendleft("https://realpython.com/python-csv/")
>>> histoire
deque (['https://realpythoncom/python-csv/'['https://realpythoncom/python-csv/'['https://realpythoncom/python-csv/'['https://realpythoncom/python-csv/'
«https://realpython.com/pandas-read-write-files/»,
«https://realpython.com/»])
Dans cet exemple, vous avez créé un espace vide histoire objet, et chaque fois que l'utilisateur a visité un nouveau site, vous l'avez ajouté à votre histoire variable utilisant appendleft (). Ainsi, chaque nouvel élément a été ajouté au tête de la liste chaînée.
Supposons maintenant qu'après avoir lu les deux articles, l'utilisateur ait voulu revenir à la page d'accueil de Real Python pour choisir un nouvel article à lire. Sachant que vous disposez d'une pile et que vous souhaitez supprimer des éléments à l'aide de LIFO, vous pouvez effectuer les opérations suivantes:
>>> histoire.popleft()
«https://realpython.com/python-csv/»
>>> histoire.popleft()
«https://realpython.com/pandas-read-write-files/»
>>> histoire
deque (['https://realpython.com/'])
Voilà! En utilisant popleft (), vous avez supprimé des éléments du tête de la liste liée jusqu'à ce que vous atteigniez la page d'accueil de Real Python.
À partir des exemples ci-dessus, vous pouvez voir à quel point il peut être utile d'avoir collections.deque dans votre boîte à outils, alors assurez-vous de l'utiliser la prochaine fois que vous aurez un défi basé sur une file d'attente ou une pile à résoudre.
Implémentation de votre propre liste liée
Maintenant que vous savez utiliser collections.deque pour gérer les listes chaînées, vous vous demandez peut-être pourquoi vous implémenteriez jamais votre propre liste chaînée en Python. Il y a plusieurs raisons de le faire:
- Pratiquer vos compétences en algorithme Python
- Apprendre la théorie de la structure des données
- Préparation aux entretiens d'embauche
N'hésitez pas à ignorer cette section suivante si vous n'êtes intéressé par aucun des éléments ci-dessus, ou si vous avez déjà mis en œuvre votre propre liste de liens en Python. Sinon, il est temps de mettre en place des listes chaînées!
Comment créer une liste liée
Tout d'abord, créez une classe pour représenter votre liste chaînée:
classe LinkedList:
def __init__(soi):
soi.tête = Aucun
La seule information dont vous avez besoin pour stocker une liste chaînée est l'endroit où la liste commence (le tête de la liste). Ensuite, créez une autre classe pour représenter chaque nœud de la liste chaînée:
classe Nœud:
def __init__(soi, Les données):
soi.Les données = Les données
soi.suivant = Aucun
Dans la définition de classe ci-dessus, vous pouvez voir les deux principaux éléments de chaque nœud: Les données et suivant. Vous pouvez également ajouter un __repr__ aux deux classes pour avoir une représentation plus utile des objets:
classe Nœud:
def __init__(soi, Les données):
soi.Les données = Les données
soi.suivant = Aucun
def __repr__(soi):
revenir soi.Les données
classe LinkedList:
def __init__(soi):
soi.tête = Aucun
def __repr__(soi):
nœud = soi.tête
noeuds = []
tandis que nœud est ne pas Aucun:
noeuds.ajouter(nœud.Les données)
nœud = nœud.suivant
noeuds.ajouter("Aucun")
revenir "->".joindre(noeuds)
Jetez un œil à un exemple d'utilisation des classes ci-dessus pour créer rapidement une liste liée avec trois nœuds:
>>> llist = LinkedList()
>>> llist
Aucun
>>> premier_noeud = Nœud("une")
>>> llist.tête = premier_noeud
>>> llist
a -> Aucun
>>> second_node = Nœud("b")
>>> troisième_noeud = Nœud("c")
>>> premier_noeud.suivant = second_node
>>> second_node.suivant = troisième_noeud
>>> llist
a -> b -> c -> Aucun
En définissant un nœud Les données et suivant valeurs, vous pouvez créer une liste chaînée assez rapidement. Celles-ci LinkedList et Nœud les classes sont les points de départ de notre implémentation. Désormais, il s’agit d’augmenter leurs fonctionnalités.
Voici une légère modification de la liste des liens __init __ () qui vous permet de créer rapidement des listes liées avec quelques données:
def __init__(soi, noeuds=Aucun):
soi.tête = Aucun
si noeuds est ne pas Aucun:
nœud = Nœud(Les données=noeuds.pop(0))
soi.tête = nœud
pour elem dans noeuds:
nœud.suivant = Nœud(Les données=elem)
nœud = nœud.suivant
Avec la modification ci-dessus, la création de listes liées à utiliser dans les exemples ci-dessous sera beaucoup plus rapide.
Comment parcourir une liste liée
L'une des choses les plus courantes que vous ferez avec une liste chaînée est de traverser il. Traverser signifie passer par chaque nœud, en commençant par le tête de la liste chaînée et se terminant sur le nœud qui a un suivant valeur de Aucun.
La traversée est juste une façon plus sophistiquée de dire itérer. Donc, dans cet esprit, créez un __iter__ pour ajouter le même comportement aux listes liées que vous attendez d'une liste normale:
def __iter__(soi):
nœud = soi.tête
tandis que nœud est ne pas Aucun:
rendement nœud
nœud = nœud.suivant
La méthode ci-dessus parcourt la liste et produit chaque nœud unique. La chose la plus importante à retenir à ce sujet __iter__ est que vous devez toujours valider que le courant nœud n'est pas Aucun. Lorsque cette condition est Vrai, cela signifie que vous avez atteint la fin de votre liste de liens.
Après avoir donné le nœud actuel, vous souhaitez passer au nœud suivant de la liste. C’est pourquoi vous ajoutez node = node.next. Voici un exemple de traversée d'une liste aléatoire et d'impression de chaque nœud:
>>> llist = LinkedList([[[["une", "b", "c", "ré", "e"])
>>> llist
a -> b -> c -> d -> e -> Aucun
>>> pour nœud dans llist:
... impression(nœud)
une
b
c
ré
e
Dans d'autres articles, vous pouvez voir la traversée définie dans une méthode spécifique appelée traverser(). Cependant, l'utilisation des méthodes intégrées de Python pour obtenir ce comportement rend cette implémentation de liste liée un peu plus Pythonic.
Comment insérer un nouveau nœud
Il existe différentes façons d'insérer de nouveaux nœuds dans une liste chaînée, chacun avec sa propre implémentation et son niveau de complexité. C'est pourquoi vous les verrez divisés en méthodes spécifiques pour l'insertion au début, à la fin ou entre les nœuds d'une liste.
Insertion au début
L'insertion d'un nouveau nœud au début d'une liste est probablement l'insertion la plus simple, car vous n'avez pas à parcourir toute la liste pour le faire. Il s'agit de créer un nouveau nœud, puis de pointer le tête de la liste.
Jetez un œil à l'implémentation suivante de add_first () pour la classe LinkedList:
def add_first(soi, nœud):
nœud.suivant = soi.tête
soi.tête = nœud
Dans l'exemple ci-dessus, vous définissez self.head comme le suivant référence du nouveau nœud de sorte que le nouveau nœud pointe vers l'ancien self.head. Après cela, vous devez déclarer que le nouveau tête de la liste est le nœud inséré.
Voici comment il se comporte avec une liste d'échantillons:
>>> llist = LinkedList()
>>> llist
Aucun
>>> llist.add_first(Nœud("b"))
>>> llist
b -> Aucun
>>> llist.add_first(Nœud("une"))
>>> llist
a -> b -> Aucun
Comme vous pouvez le voir, add_first () ajoute toujours le nœud au tête de la liste, même si la liste était vide auparavant.
Insertion à la fin
L'insertion d'un nouveau nœud à la fin de la liste vous oblige à parcourir d'abord la liste liée entière et à ajouter le nouveau nœud lorsque vous atteignez la fin. Vous ne pouvez pas simplement ajouter à la fin comme vous le feriez avec une liste normale, car dans une liste liée, vous ne savez pas quel nœud est le dernier.
Voici un exemple d'implémentation d'une fonction pour insérer un nœud à la fin d'une liste chaînée:
def add_last(soi, nœud):
si ne pas soi.tête:
soi.tête = nœud
revenir
pour noeud_actuel dans soi:
passer
noeud_actuel.suivant = nœud
Tout d'abord, vous voulez parcourir toute la liste jusqu'à la fin (c'est-à-dire jusqu'à ce que pour boucle soulève un StopIteration exception). Ensuite, vous souhaitez définir le noeud_actuel comme dernier nœud de la liste. Enfin, vous souhaitez ajouter le nouveau nœud en tant que suivant valeur de cela noeud_actuel.
Voici un exemple de add_last () en action:
>>> llist = LinkedList([[[["une", "b", "c", "ré"])
>>> llist
a -> b -> c -> d -> Aucun
>>> llist.add_last(Nœud("e"))
>>> llist
a -> b -> c -> d -> e -> Aucun
>>> llist.add_last(Nœud("F"))
>>> llist
a -> b -> c -> d -> e -> f -> Aucun
Dans le code ci-dessus, vous commencez par créer une liste avec quatre valeurs (une, b, c, et ré). Ensuite, lorsque vous ajoutez de nouveaux nœuds à l'aide add_last (), vous pouvez voir que les nœuds sont toujours ajoutés à la fin de la liste.
Insertion entre deux nœuds
L'insertion entre deux nœuds ajoute une couche de complexité supplémentaire aux insertions déjà complexes de la liste liée car il existe deux approches différentes que vous pouvez utiliser:
- Insertion après un nœud existant
- Insertion avant un nœud existant
Il peut sembler étrange de les diviser en deux méthodes, mais les listes liées se comportent différemment des listes normales et vous avez besoin d'une implémentation différente pour chaque cas.
Voici une méthode qui ajoute un nœud après un nœud existant avec une valeur de données spécifique:
def add_after(soi, target_node_data, new_node):
si ne pas soi.tête:
élever Exception("La liste est vide")
pour nœud dans soi:
si nœud.Les données == target_node_data:
new_node.suivant = nœud.suivant
nœud.suivant = new_node
revenir
élever Exception("Noeud avec données"% s' pas trouvé" % target_node_data)
Dans le code ci-dessus, vous parcourez la liste liée à la recherche du nœud avec des données indiquant où vous souhaitez insérer un nouveau nœud. Lorsque vous trouvez le nœud que vous recherchez, vous insérez le nouveau nœud immédiatement après celui-ci et recâblez le suivant référence pour maintenir la cohérence de la liste.
Les seules exceptions sont si la liste est vide, ce qui rend impossible l'insertion d'un nouveau nœud après un nœud existant, ou si la liste ne contient pas la valeur que vous recherchez. Voici quelques exemples de la façon dont add_after () se comporte:
>>> llist = LinkedList()
>>> llist.add_after("une", Nœud("b"))
Exception: la liste est vide
>>> llist = LinkedList([[[["une", "b", "c", "ré"])
>>> llist
a -> b -> c -> d -> Aucun
>>> llist.add_after("c", Nœud("cc"))
>>> llist
a -> b -> c -> cc -> d -> Aucun
>>> llist.add_after("F", Nœud("g"))
Exception: nœud avec les données «f» introuvable
Essayer d'utiliser add_after () sur une liste vide entraîne une exception. La même chose se produit lorsque vous essayez d'ajouter après un nœud inexistant. Tout le reste fonctionne comme prévu.
Maintenant, si vous voulez implémenter ajouter avant(), cela ressemblera à ceci:
1 def ajouter avant(soi, target_node_data, new_node):
2 si ne pas soi.tête:
3 élever Exception("La liste est vide")
4
5 si soi.tête.Les données == target_node_data:
6 revenir soi.add_first(new_node)
sept
8 prev_node = soi.tête
9 pour nœud dans soi:
dix si nœud.Les données == target_node_data:
11 prev_node.suivant = new_node
12 new_node.suivant = nœud
13 revenir
14 prev_node = nœud
15
16 élever Exception("Noeud avec données"% s' pas trouvé" % target_node_data)
Il y a quelques points à garder à l'esprit lors de la mise en œuvre de ce qui précède. Tout d'abord, comme avec add_after (), vous voulez vous assurer de déclencher une exception si la liste liée est vide (ligne 2) ou si le nœud que vous recherchez n'est pas présent (ligne 16).
Deuxièmement, si vous essayez d'ajouter un nouveau nœud avant le début de la liste (ligne 5), vous pouvez réutiliser add_first () car le nœud que vous insérez sera le nouveau tête de la liste.
Enfin, pour tout autre cas (ligne 9), vous devez garder une trace du dernier nœud vérifié en utilisant le prev_node variable. Ensuite, lorsque vous trouvez le nœud cible, vous pouvez l'utiliser prev_node variable pour recâbler la suivant valeurs.
Encore une fois, un exemple vaut mille mots:
>>> llist = LinkedList()
>>> llist.ajouter avant("une", Nœud("une"))
Exception: la liste est vide
>>> llist = LinkedList([[[["b", "c"])
>>> llist
b -> c -> Aucun
>>> llist.ajouter avant("b", Nœud("une"))
>>> llist
a -> b -> c -> Aucun
>>> llist.ajouter avant("b", Nœud("aa"))
>>> llist.ajouter avant("c", Nœud("bb"))
>>> llist
a -> aa -> b -> bb -> c -> Aucun
>>> llist.ajouter avant("n", Nœud("m"))
Exception: nœud avec les données «n» introuvable
Avec ajouter avant(), vous disposez désormais de toutes les méthodes nécessaires pour insérer des nœuds où vous le souhaitez dans votre liste.
Comment supprimer un nœud
Pour supprimer un nœud d'une liste liée, vous devez d'abord parcourir la liste jusqu'à ce que vous trouviez le nœud que vous souhaitez supprimer. Une fois que vous avez trouvé la cible, vous souhaitez lier ses nœuds précédent et suivant. Cette reconnexion est ce qui supprime le nœud cible de la liste.
Cela signifie que vous devez garder une trace du nœud précédent lorsque vous parcourez la liste. Jetez un œil à un exemple d'implémentation:
1 def remove_node(soi, target_node_data):
2 si ne pas soi.tête:
3 élever Exception("La liste est vide")
4
5 si soi.tête.Les données == target_node_data:
6 soi.tête = soi.tête.suivant
sept revenir
8
9 previous_node = soi.tête
dix pour nœud dans soi:
11 si nœud.Les données == target_node_data:
12 previous_node.suivant = nœud.suivant
13 revenir
14 previous_node = nœud
15
16 élever Exception("Noeud avec données"% s' pas trouvé" % target_node_data)
Dans le code ci-dessus, vous vérifiez d'abord que votre liste n'est pas vide (ligne 2). Si tel est le cas, vous soulève une exception. Après cela, vous vérifiez si le nœud à supprimer est l'actuel tête de la liste (ligne 5). Si tel est le cas, vous souhaitez que le nœud suivant de la liste devienne le nouveau tête.
Si rien de ce qui précède ne se produit, vous commencez à parcourir la liste à la recherche du nœud à supprimer (ligne 10). Si vous le trouvez, vous devez mettre à jour son nœud précédent pour pointer vers son nœud suivant, supprimant automatiquement le nœud trouvé de la liste. Enfin, si vous parcourez la liste entière sans trouver le nœud à supprimer (ligne 16), vous lève une exception.
Remarquez comment vous utilisez le code ci-dessus previous_node pour garder une trace du nœud, eh bien, précédent. Cela garantit que l'ensemble du processus sera beaucoup plus simple lorsque vous trouverez le bon nœud à supprimer.
Voici un exemple utilisant une liste:
>>> llist = LinkedList()
>>> llist.remove_node("une")
Exception: la liste est vide
>>> llist = LinkedList([[[["une", "b", "c", "ré", "e"])
>>> llist
a -> b -> c -> d -> e -> Aucun
>>> llist.remove_node("une")
>>> llist
b -> c -> d -> e -> Aucun
>>> llist.remove_node("e")
>>> llist
b -> c -> d -> Aucun
>>> llist.remove_node("c")
>>> llist
b -> d -> Aucun
>>> llist.remove_node("une")
Exception: nœud avec les données «a» introuvable
C'est ça! Vous savez maintenant comment implémenter une liste chaînée et toutes les principales méthodes pour parcourir, insérer et supprimer des nœuds. Si vous vous sentez à l'aise avec ce que vous avez appris et que vous en voulez plus, n'hésitez pas à choisir l'un des défis ci-dessous:
- Créez une méthode pour récupérer un élément à partir d'une position spécifique:
obtenir (i)ou mêmellist[i]. - Créez une méthode pour inverser la liste chaînée:
llist.reverse (). - Créer un
Queue()objet héritant de la liste chaînée de cet article avecenqueue ()etdequeue ()méthodes.
En plus d'être une excellente pratique, relever des défis supplémentaires par vous-même est un moyen efficace d'assimiler toutes les connaissances que vous avez acquises. Si vous souhaitez prendre une longueur d'avance en réutilisant tout le code source de cet article, vous pouvez télécharger tout ce dont vous avez besoin sur le lien ci-dessous:
Utilisation de listes liées avancées
Jusqu'à présent, vous avez découvert un type spécifique de liste chaînée appelé listes liées individuellement. Mais il existe plus de types de listes chaînées qui peuvent être utilisées à des fins légèrement différentes.
Comment utiliser des listes doublement liées
Les listes à double liaison sont différentes des listes à liaison unique en ce qu'elles ont deux références:
- le
précédentchamp fait référence au nœud précédent. - le
suivantle champ fait référence au nœud suivant.
Le résultat final ressemble à ceci:

Si vous souhaitez mettre en œuvre ce qui précède, vous pouvez apporter des modifications à votre Nœud classe afin d'inclure un précédent champ:
classe Nœud:
def __init__(soi, Les données):
soi.Les données = Les données
soi.suivant = Aucun
soi.précédent = Aucun
Ce type d'implémentation vous permettrait de parcourir une liste dans les deux sens au lieu de parcourir uniquement en utilisant suivant. Vous pourriez utiliser suivant aller de l'avant et précédent pour reculer.
En termes de structure, voici à quoi ressemblerait une liste doublement liée:

Vous avez appris plus tôt que collections.deque utilise une liste chaînée dans le cadre de sa structure de données. C'est le genre de liste chaînée qu'il utilise. Avec des listes doublement liées, deque est capable d'insérer ou de supprimer des éléments des deux extrémités d'une file d'attente avec une constante O (1) performance.
Comment utiliser les listes liées circulaires
Listes circulaires liées sont un type de liste chaînée dans laquelle le dernier nœud pointe vers le tête de la liste au lieu de pointer vers Aucun. C'est ce qui les rend circulaires. Les listes liées circulaires ont quelques cas d'utilisation intéressants:
- Faire le tour de chaque joueur dans une partie multijoueur
- Gérer le cycle de vie des applications d'un système d'exploitation donné
- Implémentation d'un tas Fibonacci
Voici à quoi ressemble une liste chaînée circulaire:
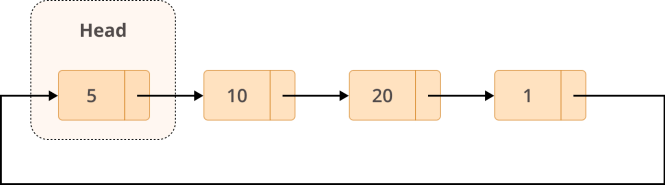
L'un des avantages des listes chaînées circulaires est que vous pouvez parcourir la liste entière en commençant par n'importe quel nœud. Puisque le dernier nœud pointe vers le tête de la liste, vous devez vous assurer que vous arrêtez de traverser lorsque vous atteignez le point de départ. Sinon, vous vous retrouverez dans une boucle infinie.
En termes de mise en œuvre, les listes chaînées circulaires sont très similaires à la liste chaînée unique. La seule différence est que vous pouvez définir le point de départ lorsque vous parcourez la liste:
classe CircularLinkedList:
def __init__(soi):
soi.tête = Aucun
def traverser(soi, point de départ=Aucun):
si point de départ est Aucun:
point de départ = soi.tête
nœud = point de départ
tandis que nœud est ne pas Aucun et (nœud.suivant ! = point de départ):
rendement nœud
nœud = nœud.suivant
rendement nœud
def liste_impression(soi, point de départ=Aucun):
noeuds = []
pour nœud dans soi.traverser(point de départ):
noeuds.ajouter(str(nœud))
impression("->".joindre(noeuds))
Traverser la liste reçoit désormais un argument supplémentaire, point de départ, qui est utilisé pour définir le début et (parce que la liste est circulaire) la fin du processus d'itération. En dehors de cela, une grande partie du code est le même que celui que nous avions dans notre LinkedList classe.
Pour conclure avec un dernier exemple, regardez comment ce nouveau type de liste se comporte lorsque vous lui donnez des données:
>>> circulaire_lliste = CircularLinkedList()
>>> circulaire_lliste.liste_impression()
Aucun
>>> une = Nœud("une")
>>> b = Nœud("b")
>>> c = Nœud("c")
>>> ré = Nœud("ré")
>>> une.suivant = b
>>> b.suivant = c
>>> c.suivant = ré
>>> ré.suivant = une
>>> circulaire_lliste.tête = une
>>> circulaire_lliste.liste_impression()
a -> b -> c -> d
>>> circulaire_lliste.liste_impression(b)
b -> c -> d -> a
>>> circulaire_lliste.liste_impression(ré)
d -> a -> b -> c
Voilà! Vous remarquerez que vous n'avez plus Aucun tout en parcourant la liste. That’s because there is no specific end to a circular list. You can also see that choosing different starting nodes will render slightly different representations of the same list.
Conclusion
In this article, you learned quite a few things! The most important are:
- What linked lists are and when you should use them
- How to use
collections.dequeto implement queues and stacks - How to implement your own linked list and node classes, plus relevant methods
- What the other types of linked lists are and what they can be used for
If you want to learn more about linked lists, then check out Vaidehi Joshi’s Medium post for a nice visual explanation. If you’re interested in a more in-depth guide, then the Wikipedia article is quite thorough. Finally, if you’re curious about the reasoning behind the current implementation of collections.deque, then check out Raymond Hettinger’s thread.
You can download the source code used throughout this tutorial by clicking on the following link:
Feel free to leave any questions or comments below. Happy Pythoning!
[ad_2]