trouver un expert Python
Que vous appreniez à connaître un ensemble de données ou que vous vous prépariez à publier vos résultats, visualisation est un outil essentiel. La bibliothèque d'analyse de données populaire de Python, pandas, offre plusieurs options différentes pour visualiser vos données avec .terrain(). Même si vous êtes au début de votre voyage avec les pandas, vous allez bientôt créer des graphiques de base qui vous donneront des informations précieuses sur vos données.
Dans ce didacticiel, vous apprendrez:
- Quels sont les différents types de parcelles de pandas sont et quand les utiliser
- Comment obtenir une vue d'ensemble de votre ensemble de données avec un histogramme
- Comment découvrir la corrélation avec un nuage de points
- Comment analyser différents catégories et leur ratios
Configurez votre environnement
Vous pouvez mieux suivre le code de ce didacticiel dans un bloc-notes Jupyter. De cette façon, vous verrez immédiatement vos tracés et pourrez jouer avec eux.
Vous aurez également besoin d'un environnement Python fonctionnel comprenant des pandas. Si vous n'en avez pas encore, vous avez plusieurs options:
-
Si vous avez des projets plus ambitieux, téléchargez la distribution Anaconda. C'est énorme (environ 500 Mo), mais vous serez équipé pour la plupart des travaux de science des données.
-
Si vous préférez une configuration minimaliste, consultez la section sur l'installation de Miniconda dans Configuration de Python pour l'apprentissage automatique sur Windows.
-
Si vous voulez vous en tenir à
pépin, puis installez les bibliothèques décrites dans ce tutoriel avecpip installer pandas matplotlib. Vous pouvez également récupérer Jupyter Notebook avecpip installer jupyterlab. -
Si vous ne souhaitez effectuer aucune configuration, suivez un essai en ligne de Jupyter Notebook.
Une fois votre environnement configuré, vous êtes prêt à télécharger un ensemble de données. Dans ce didacticiel, vous allez analyser des données sur les majors universitaires provenant de l’échantillon de microdonnées à grande diffusion de l’American Community Survey 2010-2012. Il a servi de base au guide économique pour choisir un collège majeur présenté sur le site Web FiveThirtyEight.
Tout d'abord, téléchargez les données en transmettant l'URL de téléchargement à pandas.read_csv ():
Dans [1]: importer pandas comme pd
Dans [2]: download_url = (
...: "https://raw.githubusercontent.com/fivethirtyeight/"
...: "data / master / college-majors / recent-grads.csv"
...: )
Dans [3]: df = pd.read_csv(download_url)
Dans [4]: type(df)
En dehors[4]: pandas.core.frame.DataFrame
En appelant read_csv (), vous créez un DataFrame, qui est la principale structure de données utilisée dans les pandas.
Maintenant que vous avez un DataFrame, vous pouvez jeter un œil aux données. Tout d'abord, vous devez configurer le display.max.colonnes option pour s'assurer que les pandas ne masquent aucune colonne. Ensuite, vous pouvez afficher les premières lignes de données avec .tête():
Dans [5]: pd.set_option("display.max.columns", Aucun)
Dans [6]: df.tête()
Vous venez d'afficher les cinq premières lignes du DataFrame df en utilisant .tête(). Votre sortie devrait ressembler à ceci:

Le nombre de lignes par défaut affiché par .tête() est cinq, mais vous pouvez spécifier n'importe quel nombre de lignes comme argument. Par exemple, pour afficher les dix premières lignes, vous utiliseriez tête df (10).
Créez votre premier tracé de pandas
Votre ensemble de données contient des colonnes liées aux revenus des diplômés dans chaque majeure:
"Médian"est le salaire médian des travailleurs à temps plein toute l'année."P25th"est le 25e centile des gains.«P75e»est le 75e centile des gains."Rang"est le rang de la major en termes de gains médians.
Commençons par un tracé affichant ces colonnes. Tout d'abord, vous devez configurer votre bloc-notes Jupyter pour afficher les tracés avec le % matplotlib commande magique:
Dans [7]: %matplotlib
Utilisation du backend matplotlib: MacOSX
le % matplotlib La commande magic configure votre Jupyter Notebook pour afficher les graphiques avec Matplotlib. Le backend graphique standard de Matplotlib est utilisé par défaut, et vos tracés seront affichés dans une fenêtre séparée.
Remarque: Vous pouvez modifier le backend Matplotlib en passant un argument au % matplotlib commande magique.
Par exemple, le en ligne Le backend est populaire pour Jupyter Notebooks car il affiche le tracé dans le notebook lui-même, juste en dessous de la cellule qui crée le tracé:
Dans [7]: %matplotlib en ligne
Il existe un certain nombre d'autres backends disponibles. Pour plus d'informations, consultez le didacticiel Rich Outputs dans la documentation IPython.
Vous êtes maintenant prêt à créer votre première intrigue! Vous pouvez le faire avec .terrain():
Dans [8]: df.terrain(X="Rang", y=[[[["P25th", "Médian", «P75e»])
En dehors[8]: .terrain() renvoie un graphique linéaire contenant les données de chaque ligne du DataFrame. Les valeurs de l'axe des abscisses représentent le rang de chaque institution et le "P25th", "Médian", et «P75e» les valeurs sont tracées sur l'axe des y.
Remarque: Si vous ne suivez pas dans un bloc-notes Jupyter ou dans un shell IPython, vous devrez utiliser le pyplot interface de matplotlib pour afficher le tracé.
Voici comment afficher la figure dans un shell Python standard:
>>> importer matplotlib.pyplot comme plt
>>> df.terrain(X="Rang", y=[[[["P25th", "Médian", «P75e»])
>>> plt.spectacle()
Notez que vous devez d'abord importer le pyplot module de Matplotlib avant d'appeler plt.show () pour afficher le tracé.
La figure produite par .terrain() est affiché dans une fenêtre séparée par défaut et ressemble à ceci:
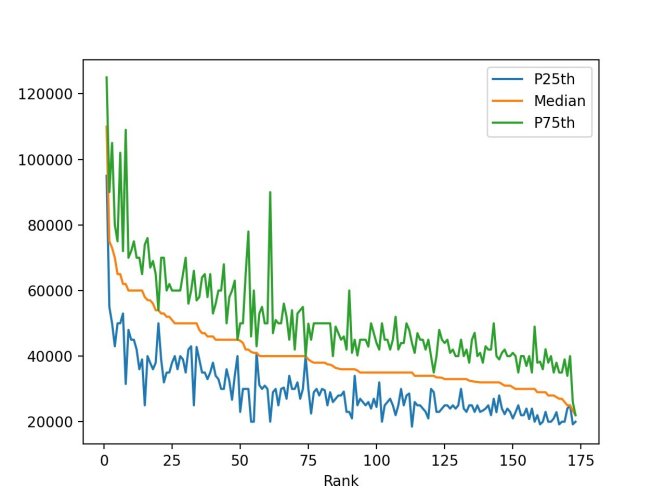
En regardant le graphique, vous pouvez faire les observations suivantes:
-
Le revenu médian diminue à mesure que le rang diminue. Ceci est attendu car le rang est déterminé par le revenu médian.
-
Certaines majors ont de grands écarts entre les 25e et 75e centiles. Les personnes titulaires de ces diplômes peuvent gagner beaucoup moins ou beaucoup plus que le revenu médian.
-
D'autres majors ont de très petits écarts entre les 25e et 75e centiles. Les personnes titulaires de ces diplômes gagnent des salaires très proches du revenu médian.
Votre premier tracé indique déjà qu'il y a beaucoup plus à découvrir dans les données! Certaines majors ont une large gamme de revenus, et d'autres une fourchette plutôt étroite. Pour découvrir ces différences, vous utiliserez plusieurs autres types de tracés.
.terrain() a plusieurs paramètres facultatifs. Plus particulièrement, le gentil Le paramètre accepte onze valeurs de chaîne différentes et détermine le type de tracé que vous allez créer:
"zone"est pour les parcelles de surface."bar"est pour les graphiques à barres verticales."barh"est pour les graphiques à barres horizontales."boîte"est pour les box plots."hexbin"est pour les tracés hexbin."hist"est pour les histogrammes."kde"est pour les graphiques d'estimation de la densité du noyau."densité"est un alias pour"kde"."ligne"est pour les graphiques linéaires."tarte"est pour les graphiques à secteurs."dispersion"est pour les nuages de points.
La valeur par défaut est "ligne". Les graphiques linéaires, comme celui que vous avez créé ci-dessus, offrent un bon aperçu de vos données. Vous pouvez les utiliser pour détecter les tendances générales. Ils fournissent rarement des informations sophistiquées, mais ils peuvent vous donner des indices sur l'endroit où effectuer un zoom avant.
Si vous ne fournissez pas de paramètre à .terrain(), puis il crée un tracé linéaire avec l'index sur l'axe des x et toutes les colonnes numériques sur l'axe des y. Bien que ce soit une valeur par défaut utile pour les ensembles de données avec seulement quelques colonnes, pour l'ensemble de données des majors du collège et ses plusieurs colonnes numériques, cela ressemble à un gâchis.
Remarque: Au lieu de passer des chaînes au gentil paramètre de .terrain(), Trame de données objets ont plusieurs méthodes que vous pouvez utiliser pour créer les différents types de tracés décrits ci-dessus:
.zone().bar().barh ().boîte().hexbin ().hist ().kde ().densité().ligne().tarte().dispersion()
Dans ce didacticiel, vous utiliserez le .terrain() interface et transmettez les chaînes au gentil paramètre. Nous vous encourageons également à essayer les méthodes mentionnées ci-dessus.
Maintenant que vous avez créé votre premier complot de pandas, voyons de plus près comment .terrain() travaux.
Regardez sous le capot: Matplotlib
Quand vous appelez .terrain() sur un Trame de données objet, Matplotlib crée le tracé sous le capot.
Pour vérifier cela, essayez deux extraits de code. Tout d'abord, créez un tracé avec Matplotlib en utilisant deux colonnes de votre DataFrame:
Dans [9]: importer matplotlib.pyplot comme plt
Dans [10]: plt.terrain(df[[[["Rang"], df[[[[«P75e»])
En dehors[10]: [[[[]
Tout d'abord, vous importez le matplotlib.pyplot module et renommez-le en plt. Alors tu appelles terrain() et passer le Trame de données objets "Rang" colonne comme premier argument et le «P75e» colonne comme deuxième argument.
Le résultat est un graphique linéaire qui trace le 75e centile sur l'axe des y par rapport au rang sur l'axe des x:

Vous pouvez créer exactement le même graphique en utilisant le Trame de données objets .terrain() méthode:
Dans [11]: df.terrain(X="Rang", y=«P75e»)
En dehors[11]: .terrain() est un emballage pour pyplot.plot (), et le résultat est un graphique identique à celui que vous avez produit avec Matplotlib:
Vous pouvez utiliser les deux pyplot.plot () et df.plot () pour produire le même graphique à partir des colonnes d'un Trame de données objet. Cependant, si vous avez déjà un Trame de données exemple, alors df.plot () offre une syntaxe plus claire que pyplot.plot ().
Remarque: Si vous connaissez déjà Matplotlib, vous serez peut-être intéressé par le kwargs paramètre à .terrain(). Vous pouvez lui passer un dictionnaire contenant des arguments de mots-clés qui seront ensuite transmis au backend de traçage Matplotlib.
Pour plus d'informations sur Matplotlib, consultez Python Plotting With Matplotlib.
Maintenant que vous savez que le Trame de données objets .terrain() method est un wrapper pour Matplotlib pyplot.plot (), plongons dans les différents types de tracés que vous pouvez créer et comment les créer.
Sondez vos données
Les graphiques suivants vous donneront un aperçu général d'une colonne spécifique de votre ensemble de données. Tout d'abord, vous allez examiner la distribution d'une propriété avec un histogramme. Ensuite, vous apprendrez à connaître certains outils pour examiner les valeurs aberrantes.
Distributions et histogrammes
Trame de données n'est pas la seule classe de pandas avec un .terrain() méthode. Comme cela arrive souvent chez les pandas, le Séries objet fournit des fonctionnalités similaires.
Vous pouvez obtenir chaque colonne d'un DataFrame en tant que Séries objet. Voici un exemple utilisant le "Médian" colonne du DataFrame que vous avez créé à partir des principales données du collège:
Dans [12]: median_column = df[[[["Médian"]
Dans [13]: type(median_column)
En dehors[13]: pandas.core.series.Series
Maintenant que vous avez un Séries objet, vous pouvez créer un tracé pour celui-ci. Un histogramme est un bon moyen de visualiser la répartition des valeurs dans un ensemble de données. Les histogrammes regroupent les valeurs en bacs et afficher un décompte des points de données dont les valeurs se trouvent dans une case particulière.
Créons un histogramme pour le "Médian" colonne:
Dans [14]: median_column.terrain(gentil="hist")
En dehors[14]: Tu appelles .terrain() sur le median_column Série et passer la chaîne "hist" à la gentil paramètre. C'est tout ce qu'on peut en dire!
Quand vous appelez .terrain(), vous verrez la figure suivante:

L'histogramme montre les données regroupées en dix catégories allant de 20000 USD à 120000 USD, et chaque zone a un largeur de 10 000 $. L'histogramme a une forme différente de la distribution normale, qui a une forme de cloche symétrique avec un pic au milieu.
L'histogramme des données médianes, cependant, culmine à gauche en dessous de 40 000 $. le queue s'étend loin vers la droite et suggère qu'il existe effectivement des domaines dont les majors peuvent s'attendre à des revenus nettement plus élevés.
Valeurs aberrantes
Avez-vous repéré ce petit bac solitaire sur le bord droit de la distribution? Il semble qu'un point de données ait sa propre catégorie. Les majors dans ce domaine obtiennent un excellent salaire par rapport non seulement à la moyenne mais aussi au finaliste. Bien que ce ne soit pas son objectif principal, un histogramme peut vous aider à détecter une telle valeur aberrante. Examinons un peu plus la valeur aberrante:
- Quelles majeures représentent cette valeur aberrante?
- Quelle est sa largeur?
Contrairement au premier aperçu, vous ne voulez comparer que quelques points de données, mais vous voulez voir plus de détails à leur sujet. Pour cela, un graphique à barres est un excellent outil. Tout d'abord, sélectionnez les cinq majors ayant les gains médians les plus élevés. Vous aurez besoin de deux étapes:
- Pour trier par
"Médian"colonne, utiliser.sort_values ()et indiquez le nom de la colonne que vous souhaitez trier ainsi que la directioncroissant = Faux. - Pour obtenir les cinq premiers éléments de votre liste, utilisez
.tête().
Créons un nouveau DataFrame appelé Top 5:
Dans [15]: Top 5 = df.sort_values(par="Médian", Ascendant=Faux).tête()
Vous avez maintenant un DataFrame plus petit contenant uniquement les cinq majors les plus lucratives. À l'étape suivante, vous pouvez créer un diagramme à barres qui montre uniquement les majors avec ces cinq premiers salaires médians:
Dans [16]: Top 5.terrain(X="Majeur", y="Médian", gentil="bar", pourrir=5, taille de police=4)
En dehors[16]: Notez que vous utilisez le pourrir et taille de police paramètres pour faire pivoter et dimensionner les étiquettes de l'axe des x afin qu'elles soient visibles. Vous verrez un graphique avec 5 barres:

Ce graphique montre que le salaire médian des majors du génie pétrolier est plus de 20 000 $ plus élevé que le reste. Les gains des majors de la deuxième à la quatrième place sont relativement proches les uns des autres.
Si vous avez un point de données avec une valeur beaucoup plus élevée ou plus basse que le reste, vous voudrez probablement approfondir vos recherches. Par exemple, vous pouvez consulter les colonnes contenant des données associées.
Examinons toutes les majors dont le salaire médian est supérieur à 60 000 USD. Tout d'abord, vous devez filtrer ces majors avec le masque df[df["Median"] > 60000]. Ensuite, vous pouvez créer un autre diagramme à barres affichant les trois colonnes de revenus:
Dans [17]: top_medians = df[[[[df[[[["Médian"] > 60000].sort_values("Médian")
Dans [18]: top_medians.terrain(X="Majeur", y=[[[["P25th", "Médian", «P75e»], gentil="bar")
En dehors[18]: Vous devriez voir un graphique avec trois mesures par majeure, comme ceci:

Les 25e et 75e centiles confirment ce que vous avez vu ci-dessus: les majors en génie pétrolier étaient de loin les nouveaux diplômés les mieux payés.
Pourquoi devriez-vous être si intéressé par les valeurs aberrantes dans cet ensemble de données? Si vous êtes étudiant et que vous vous demandez quelle majeure choisir, vous avez au moins une raison assez évidente. Mais les valeurs aberrantes sont également très intéressantes du point de vue de l'analyse. Ils peuvent indiquer non seulement les industries avec une abondance d'argent, mais aussi des données invalides.
Des données non valides peuvent être causées par un certain nombre d'erreurs ou d'oublis, y compris une panne de capteur, une erreur lors de la saisie manuelle des données ou un enfant de cinq ans participant à un groupe de discussion destiné aux enfants de dix ans et plus. L'étude des valeurs aberrantes est une étape importante du nettoyage des données.
Même si les données sont correctes, vous pouvez décider qu'elles sont tellement différentes des autres qu'elles produisent plus de bruit que d'avantages. Supposons que vous analysiez les données de vente d'un petit éditeur. Vous regroupez les revenus par région et vous les comparez au même mois de l'année précédente. Puis à l'improviste, l'éditeur décroche un best-seller national.
Cet événement agréable rend votre rapport inutile. Avec les données du best-seller incluses, les ventes augmentent partout. Effectuer la même analyse sans la valeur aberrante fournirait des informations plus précieuses, vous permettant de voir qu'à New York, vos chiffres de vente se sont considérablement améliorés, mais à Miami, ils ont empiré.
Vérifier la corrélation
Vous voulez souvent voir si deux colonnes d'un ensemble de données sont connectées. Si vous choisissez une majeure avec des gains médians plus élevés, avez-vous également moins de risques de chômage? Dans un premier temps, créez un nuage de points avec ces deux colonnes:
Dans [19]: df.terrain(X="Médian", y="Taux de chômage", gentil="dispersion")
En dehors[19]: Vous devriez voir un graphique assez aléatoire, comme celui-ci:

Un rapide coup d'œil à ce chiffre montre qu'il n'y a pas de corrélation significative entre les revenus et le taux de chômage.
Bien qu'un nuage de points soit un excellent outil pour avoir une première impression sur une corrélation possible, ce n'est certainement pas une preuve définitive d'une connexion. Pour un aperçu des corrélations entre les différentes colonnes, vous pouvez utiliser .corr (). Si vous suspectez une corrélation entre deux valeurs, vous disposez de plusieurs outils pour vérifier votre intuition et mesurer la force de la corrélation.
Gardez à l'esprit, cependant, que même s'il existe une corrélation entre deux valeurs, cela ne signifie toujours pas qu'une modification de l'une entraînerait une modification de l'autre. En d'autres termes, la corrélation n'implique pas de causalité.
Analyser les données catégoriques
Pour traiter de plus gros morceaux d'informations, l'esprit humain trie consciemment et inconsciemment les données en catégories. Cette technique est souvent utile, mais elle est loin d’être parfaite.
Parfois, nous classons les choses dans une catégorie qui, après un examen plus approfondi, ne sont pas si similaires. Dans cette section, vous découvrirez certains outils permettant d'examiner les catégories et de vérifier si une catégorisation donnée a du sens.
De nombreux ensembles de données contiennent déjà une catégorisation explicite ou implicite. Dans l'exemple actuel, les 173 majors sont divisées en 16 catégories.
Regroupement
Une utilisation de base des catégories est le regroupement et l'agrégation. Vous pouvez utiliser .par groupe() pour déterminer la popularité de chacune des catégories de l'ensemble de données principal du collège:
Dans [20]: cat_totals = df.par groupe("Major_category")[[[["Total"].somme().sort_values()
Dans [21]: cat_totals
En dehors[21]:
Major_category
Interdisciplinaire 12296.0
Agriculture et ressources naturelles 75620,0
Droit et politique publique 179107.0
Sciences physiques 185479.0
Arts industriels et services aux consommateurs 229792,0
Informatique et mathématiques 299008.0
Arts 357130.0
Communications et journalisme 392601.0
Biologie et sciences de la vie 453862.0
Santé 463230.0
Psychologie et travail social 481007.0
Sciences sociales 529966.0
Ingénierie 537583.0
Éducation 559129,0
Sciences humaines et arts libéraux 713468.0
Affaires 1302376.0
Nom: Total, dtype: float64
Avec .par groupe(), vous créez un DataFrameGroupBy objet. Avec .somme(), vous créez une série.
Trouvons un graphique à barres horizontales montrant tous les totaux des catégories dans cat_totals:
Dans [22]: cat_totals.terrain(gentil="barh", taille de police=4)
En dehors[22]: Vous devriez voir un graphique avec une barre horizontale pour chaque catégorie:

Comme le montre votre intrigue, les affaires sont de loin la principale catégorie la plus populaire. Alors que les sciences humaines et les arts libéraux sont clairement les seconds, les autres domaines sont plus similaires en popularité.
Remarque: Une colonne contenant des données catégorielles fournit non seulement des informations précieuses pour l'analyse et la visualisation, mais elle offre également la possibilité d'améliorer les performances de votre code.
Déterminer les ratios
Les graphiques à barres verticales et horizontales sont souvent un bon choix si vous souhaitez voir la différence entre vos catégories. Si vous êtes intéressé par les ratios, les graphiques à secteurs sont un excellent outil. Cependant, depuis cat_totals contient quelques catégories plus petites, créant un diagramme à secteurs avec cat_totals.plot (genre = "tarte") produira plusieurs minuscules tranches avec des étiquettes qui se chevauchent.
Pour résoudre ce problème, vous pouvez regrouper les catégories plus petites dans un seul groupe. Fusionner toutes les catégories avec un total inférieur à 100 000 dans une catégorie appelée "Autre", puis créez un diagramme à secteurs:
Dans [23]: small_cat_totals = cat_totals[[[[cat_totals < 100_000]
Dans [24]: big_cat_totals = cat_totals[[[[cat_totals > 100_000]
Dans [25]: # Ajout d'un nouvel élément "Autre" avec la somme des petites catégories
Dans [26]: small_sums = pd.Séries([[[[small_cat_totals.somme()], indice=[[[["Autre"])
Dans [27]: big_cat_totals = big_cat_totals.ajouter(small_sums)
Dans [28]: big_cat_totals.terrain(gentil="tarte", étiquette="")
En dehors[28]: Notez que vous incluez l'argument label = "". Par défaut, pandas ajoute une étiquette avec le nom de la colonne. Cela a souvent du sens, mais dans ce cas, cela ne ferait qu'ajouter du bruit.
Vous devriez maintenant voir un diagramme à secteurs comme celui-ci:

le "Autre" la catégorie ne représente encore qu’une très petite part du gâteau. C’est un bon signe que la fusion de ces petites catégories était le bon choix.
Zoom avant sur les catégories
Parfois, vous souhaitez également vérifier si une certaine catégorisation a du sens. Les membres d'une catégorie sont-ils plus similaires les uns aux autres qu'ils ne le sont au reste de l'ensemble de données? Encore une fois, une distribution est un bon outil pour avoir un premier aperçu. En général, nous nous attendons à ce que la distribution d'une catégorie soit similaire à la distribution normale mais qu'elle ait une gamme plus petite.
Créez un histogramme montrant la distribution des gains médians des majors d'ingénierie:
Dans [29]: df[[[[df[[[["Major_category"] == "Ingénierie"][[[["Médian"].terrain(gentil="hist")
En dehors[29]: Vous obtiendrez un histogramme que vous pourrez comparer à l'histogramme de toutes les disciplines majeures depuis le début:

La fourchette des principaux gains médians est un peu plus petite, à partir de 40 000 $. La distribution est plus proche de la normale, bien que son pic soit toujours à gauche. Ainsi, même si vous avez décidé de choisir une majeure dans la catégorie ingénierie, il serait sage de plonger plus profondément et d'analyser vos options plus en profondeur.
Conclusion
Dans ce didacticiel, vous avez appris comment démarrer visualiser votre jeu de données en utilisant Python et la bibliothèque pandas. Vous avez vu comment certains graphiques de base peuvent vous donner un aperçu de vos données et guider votre analyse.
Dans ce didacticiel, vous avez appris à:
- Obtenez un aperçu de la distribution de votre ensemble de données avec un histogramme
- Découvrez la corrélation avec un nuage de points
- Analysez les catégories avec parcelles à barres et leurs ratios avec parcelles à secteurs
- Déterminez quel tracé est le plus adapté à votre tâche actuelle
En utilisant .terrain() et un petit DataFrame, vous avez découvert de nombreuses possibilités pour fournir une image de vos données. Vous êtes maintenant prêt à tirer parti de ces connaissances et à découvrir des visualisations encore plus sophistiquées.
Si vous avez des questions ou des commentaires, veuillez les mettre dans la section commentaires ci-dessous.
Lectures complémentaires
Bien que les pandas et Matplotlib facilitent la visualisation de vos données, il existe des possibilités infinies pour créer des graphiques plus sophistiqués, plus beaux ou plus attrayants.
Un bon point de départ est la section de traçage de la documentation de pandas DataFrame. Il contient à la fois un excellent aperçu et des descriptions détaillées des nombreux paramètres que vous pouvez utiliser avec vos DataFrames.
Si vous souhaitez mieux comprendre les fondements du traçage avec des pandas, familiarisez-vous davantage avec Matplotlib. Bien que la documentation puisse parfois être écrasante, Anatomy of Matplotlib fait un excellent travail en introduisant certaines fonctionnalités avancées.
Si vous souhaitez impressionner votre public avec des visualisations interactives et l'encourager à explorer les données par lui-même, faites de Bokeh votre prochain arrêt. Vous pouvez trouver un aperçu des fonctionnalités de Bokeh dans la visualisation interactive des données en Python avec Bokeh. Vous pouvez également configurer les pandas pour utiliser Bokeh au lieu de Matplotlib avec le pandas-bokeh bibliothèque
Si vous souhaitez créer des visualisations pour une analyse statistique ou pour un article scientifique, consultez Seaborn. Vous pouvez trouver une courte leçon sur Seaborn dans le traçage d'histogramme Python.
[ad_2]