Formation Python
Le traitement du langage naturel (PNL) est un domaine qui vise à rendre le langage humain naturel utilisable par des programmes informatiques. NLTK, ou Natural Language Toolkit, est un package Python que vous pouvez utiliser pour la PNL.
Une grande partie des données que vous pourriez analyser sont des données non structurées et contiennent du texte lisible par l'homme. Avant de pouvoir analyser ces données par programme, vous devez d'abord les prétraiter. Dans ce didacticiel, vous allez examiner pour la première fois les types de prétraitement de texte tâches que vous pouvez effectuer avec NLTK pour être prêt à les appliquer dans de futurs projets. Vous verrez également comment effectuer quelques opérations de base analyse de texte et créer visualisations.
Si vous connaissez les bases de l’utilisation de Python et que vous souhaitez vous mouiller les pieds avec de la PNL, vous êtes au bon endroit.
À la fin de ce didacticiel, vous saurez comment:
- Rechercher du texte analyser
- Prétraiter votre texte pour analyse
- Analyser ton texte
- Créer visualisations basé sur votre analyse
Faisons le Python!
Premiers pas avec NLTK de Python
La première chose à faire est de vous assurer que Python est installé. Pour ce didacticiel, vous utiliserez Python 3.9. Si vous n'avez pas encore installé Python, consultez le Guide d'installation et de configuration de Python 3 pour commencer.
Une fois que vous avez réglé ce problème, votre prochaine étape consiste à installer NLTK avec pépin. Il est recommandé de l’installer dans un environnement virtuel. Pour en savoir plus sur les environnements virtuels, consultez Environnements virtuels Python: une introduction.
Pour ce didacticiel, vous allez installer la version 3.5:
$ python -m pip installer nltk==3.5
Afin de créer des visualisations pour la reconnaissance d'entités nommées, vous devez également installer NumPy et Matplotlib:
$ python -m pip installer numpy matplotlib
Si vous souhaitez en savoir plus sur la façon pépin fonctionne, alors vous pouvez consulter Qu'est-ce que Pip? Un guide pour les nouveaux pythonistes. Vous pouvez également consulter la page officielle sur l'installation des données NLTK.
Tokenisation
Par tokenisation, vous pouvez facilement diviser le texte par mot ou par phrase. Cela vous permettra de travailler avec des morceaux de texte plus petits qui sont encore relativement cohérents et significatifs, même en dehors du contexte du reste du texte. Il s'agit de votre première étape pour transformer des données non structurées en données structurées, qui sont plus faciles à analyser.
Lorsque vous analysez du texte, vous effectuez un jeton par mot et un jeton par phrase. Voici ce que les deux types de tokenisation apportent à la table:
-
Tokenisation par mot: Les mots sont comme les atomes du langage naturel. C’est la plus petite unité de sens qui ait encore du sens en soi. Tokeniser votre texte par mot vous permet d'identifier les mots qui reviennent particulièrement souvent. Par exemple, si vous analysez un groupe d'offres d'emploi, vous constaterez peut-être que le mot «Python» revient souvent. Cela pourrait suggérer une forte demande de connaissances Python, mais vous devez approfondir votre recherche pour en savoir plus.
-
Tokenisation par phrase: Lorsque vous tokenisez par phrase, vous pouvez analyser comment ces mots se rapportent les uns aux autres et voir plus de contexte. Y a-t-il beaucoup de mots négatifs autour du mot «Python» parce que le responsable du recrutement n’aime pas Python? Y a-t-il plus de termes du domaine de l'herpétologie que du domaine du développement de logiciels, ce qui suggère que vous avez peut-être affaire à un type de python entièrement différent de celui auquel vous vous attendiez?
Voici comment importer les parties pertinentes de NLTK afin de pouvoir les tokeniser par mot et par phrase:
>>> de nltk.tokenize importer sent_tokenize, word_tokenize
Maintenant que vous avez importé ce dont vous avez besoin, vous pouvez créer une chaîne à tokeniser. Voici une citation de Dune que vous pouvez utiliser:
>>> example_string = "" "
... Muad'Dib a appris rapidement car sa première formation était d'apprendre.
... Et la première leçon de toutes était la confiance fondamentale qu'il pouvait apprendre.
... C'est choquant de constater combien de personnes ne croient pas pouvoir apprendre,
... et combien d'autres pensent qu'apprendre est difficile. "" "
Vous pouvez utiliser sent_tokenize () se separer example_string en phrases:
>>> sent_tokenize(example_string)
["Muad'Diblearnedrapidlycarhisfirsttrainingwasinhowtolearn"["Muad'Diblearnedrapidlycarhisfirsttrainingwasinhowtolearn"["Muad'Diblearnedrapidlybecausehisfirsttrainingwasinhowtolearn"["Muad'Diblearnedrapidlybecausehisfirsttrainingwasinhowtolearn"
'Et la première leçon de toutes était la confiance fondamentale qu'il pouvait apprendre.',
"Il est choquant de constater combien de personnes ne croient pas pouvoir apprendre et combien d'autres pensent qu'apprendre est difficile."]
Tokenisation example_string par phrase vous donne une liste de trois chaînes qui sont des phrases:
"Muad'Dib a appris rapidement car sa première formation était d'apprendre à apprendre."«Et la première leçon de toutes était la confiance fondamentale qu'il pouvait apprendre."Il est choquant de constater combien de personnes ne croient pas pouvoir apprendre et combien d'autres pensent qu'apprendre est difficile."
Maintenant, essayez de tokeniser example_string par mot:
>>> word_tokenize(example_string)
["Muad'Dib"["Muad'Dib"["Muad'Dib"["Muad'Dib"
'appris',
'rapidement',
'car',
'le sien',
'premier',
'formation',
'a été',
'dans',
'comment',
'à',
'apprendre',
'.',
'Et',
'les',
'premier',
'leçon',
'de',
'tout',
'a été',
'les',
'de base',
'confiance',
'cette',
'il',
'pourrait',
'apprendre',
'.',
'Il',
"'s",
'choquant',
'à',
'trouve',
'comment',
'beaucoup',
'gens',
'fais',
'ne pas',
'croyez',
'elles ou ils',
'pouvez',
'apprendre',
',',
'et',
'comment',
'beaucoup',
'Suite',
'croyez',
'apprentissage',
'à',
'être',
'difficile',
'.']
Vous avez une liste de chaînes que NLTK considère comme des mots, telles que:
"Muad'Dib"'formation''comment'
Mais les chaînes suivantes étaient également considérées comme des mots:
Regarde comment "Son" a été divisé à l'apostrophe pour vous donner 'Il' et "'s", mais "Muad'Dib" a été laissé entier? Cela s'est produit parce que NLTK sait que 'Il' et "'s" (une contraction de «est») sont deux mots distincts, il les a donc comptés séparément. Mais "Muad'Dib" n'est pas une contraction acceptée comme "Son", donc il n’a pas été lu comme deux mots séparés et a été laissé intact.
Filtrer les mots vides
Arrêter les mots sont des mots que vous souhaitez ignorer. Vous les filtrez donc hors de votre texte lorsque vous le traitez. Des mots très courants comme 'dans', 'est', et 'un' sont souvent utilisés comme mots vides car ils n’ajoutent pas beaucoup de sens à un texte en eux-mêmes.
Voici comment importer les parties pertinentes de NLTK afin de filtrer les mots vides:
>>> nltk.Télécharger("mots vides")
>>> de nltk.corpus importer mots vides
>>> de nltk.tokenize importer word_tokenize
Voici une citation de Worf que vous pouvez filtrer:
>>> worf_quote = "Monsieur, je proteste. Je ne suis pas un homme joyeux!"
Maintenant tokenize worf_quote par mot et stockez la liste résultante dans words_in_quote:
>>> words_in_quote = word_tokenize(worf_quote)
>>> words_in_quote
['Sir', ',', 'protest', '.', 'merry', 'man', '!']
Vous avez une liste des mots dans worf_quote, la prochaine étape consiste donc à créer un ensemble de mots vides pour filtrer words_in_quote. Pour cet exemple, vous devrez vous concentrer sur les mots vides dans "Anglais":
>>> stop_words = ensemble(mots vides.mots("Anglais"))
Ensuite, créez une liste vide pour contenir les mots qui dépassent le filtre:
>>> filtered_list = []
Vous avez créé une liste vide, filtered_list, pour contenir tous les mots words_in_quote ce ne sont pas des mots d'arrêt. Maintenant, vous pouvez utiliser stop_words à filtrer words_in_quote:
>>> pour mot dans words_in_quote:
... si mot.casefold() ne pas dans stop_words:
... filtered_list.ajouter(mot)
Vous avez répété words_in_quote avec un pour boucle et a ajouté tous les mots qui n'étaient pas des mots d'arrêt à filtered_list. Vous avez utilisé .casefold () au mot afin que vous puissiez ignorer si les lettres mot étaient en majuscules ou en minuscules. Cela vaut la peine de le faire car stopwords.words ('anglais') inclut uniquement les versions minuscules des mots vides.
Vous pouvez également utiliser une compréhension de liste pour dresser une liste de tous les mots de votre texte qui ne sont pas des mots vides:
>>> filtered_list = [[[[
... mot pour mot dans words_in_quote si mot.casefold() ne pas dans stop_words
... ]
Lorsque vous utilisez une compréhension de liste, vous ne créez pas de liste vide, puis n’ajoutez pas d’éléments à la fin de celle-ci. Au lieu de cela, vous définissez la liste et son contenu en même temps. L'utilisation d'une compréhension de liste est souvent considérée comme plus pythonique.
Jetez un œil aux mots qui ont fini par filtered_list:
>>> filtered_list
['Sir', ',', 'protest', '.', 'merry', 'man', '!']
Vous avez filtré quelques mots comme 'un m' et 'une', mais vous avez également filtré 'ne pas', ce qui affecte le sens général de la phrase. (Worf n'en sera pas content.)
Des mots comme 'JE' et 'ne pas' peuvent sembler trop importants pour être filtrés et, selon le type d'analyse que vous souhaitez faire, ils peuvent l'être. Voici pourquoi:
-
'JE'est un pronom, qui sont des mots de contexte plutôt que des mots de contenu:-
Mots de contenu vous donner des informations sur les sujets abordés dans le texte ou le sentiment de l'auteur à propos de ces sujets.
-
Mots de contexte vous donner des informations sur le style d'écriture. Vous pouvez observer des modèles dans la façon dont les auteurs utilisent les mots de contexte afin de quantifier leur style d'écriture. Une fois que vous avez quantifié leur style d'écriture, vous pouvez analyser un texte écrit par un auteur inconnu pour voir dans quelle mesure il suit un style d'écriture particulier afin que vous puissiez essayer d'identifier qui est l'auteur.
-
-
'ne pas'est techniquement un adverbe mais a toujours été inclus dans la liste des mots vides de NLTK pour l'anglais. Si vous souhaitez modifier la liste des mots vides à exclure'ne pas'ou apporter d'autres modifications, vous pouvez le télécharger.
Donc, 'JE' et 'ne pas' peuvent être des parties importantes d’une phrase, mais cela dépend de ce que vous essayez d’apprendre de cette phrase.
Tige
Tige est une tâche de traitement de texte dans laquelle vous réduisez les mots à leur racine, qui est la partie centrale d'un mot. Par exemple, les mots «aider» et «aider» partagent la racine «aide». La racine vous permet de vous concentrer sur la signification de base d'un mot plutôt que sur tous les détails de son utilisation. NLTK a plus d'une tige, mais vous utiliserez la tige Porter.
Voici comment importer les parties pertinentes de NLTK afin de commencer à dériver:
>>> de nltk.stem importer PorterStemmer
>>> de nltk.tokenize importer word_tokenize
Maintenant que vous avez terminé l'importation, vous pouvez créer une racine avec PorterStemmer ():
>>> égrappoir = PorterStemmer()
L'étape suivante consiste à créer une chaîne à soulever. En voici une que vous pouvez utiliser:
>>> string_for_stemming = "" "
... L'équipage de l'USS Discovery a découvert de nombreuses découvertes.
... Découvrir, c'est ce que font les explorateurs. "" "
Avant de pouvoir extraire les mots de cette chaîne, vous devez séparer tous les mots qu'elle contient:
>>> mots = word_tokenize(string_for_stemming)
Maintenant que vous avez une liste de tous les mots tokenisés de la chaîne, jetez un œil à ce qu'il y a dans mots:
>>> mots
['Le'['Le'['The'['The'
'équipage',
'de',
'les',
«USS»,
'Découverte',
'découvert',
'beaucoup',
'découvertes',
'.',
'Découvrir',
'est',
'quelle',
'explorateurs',
'fais',
'.']
Créez une liste des versions radicales des mots dans mots en utilisant tige.stem () dans une liste de compréhension:
>>> souches_mots = [[[[égrappoir.tige(mot) pour mot dans mots]
Jetez un œil à ce qu'il y a dans souches_mots:
>>> souches_mots
['les'['les'['the'['the'
'équipage',
'de',
'les',
«nous»,
'découvrir',
'découvrir',
«mani»,
'découvrir',
'.',
'découvrir',
'est',
'quelle',
'explor',
'fais',
'.']
Voici ce qui est arrivé à tous les mots qui ont commencé par 'découvrir' ou alors «Découverte»:
| Mot original | Version à tige |
|---|---|
'Découverte' |
'découvrir' |
'découvert' |
'découvrir' |
'découvertes' |
'découvrir' |
'Découvrir' |
'découvrir' |
Ces résultats semblent un peu incohérents. Pourquoi serait 'Découverte' te donner 'découvrir' lorsque 'Découvrir' vous donne 'découvrir'?
Comprendre et surestimer sont deux façons dont le dénigrement peut mal tourner:
- Comprendre se produit lorsque deux mots liés doivent être réduits au même radical mais ne le sont pas. C'est un faux négatif.
- Surmenage se produit lorsque deux mots non liés sont réduits au même radical alors qu'ils ne devraient pas l'être. C'est un faux positif.
L’algorithme issu de Porter date de 1979, il est donc un peu plus ancien. le Tige boule de neige, qui est également appelé Porter2, est une amélioration par rapport à l'original et est également disponible via NLTK, vous pouvez donc l'utiliser dans vos propres projets. Il convient également de noter que l’objectif de l’objectif de Porter n’est pas de produire des mots complets, mais de trouver des variantes de formes d’un mot.
Heureusement, vous avez d’autres moyens de réduire les mots à leur signification fondamentale, comme la lemmatisation, que vous verrez plus loin dans ce didacticiel. Mais d'abord, nous devons couvrir des parties du discours.
Marquer des parties du discours
Partie du discours est un terme grammatical qui traite des rôles que jouent les mots lorsque vous les utilisez ensemble dans des phrases. Marquer des parties du discours, ou Marquage de point de vente, est la tâche d'étiqueter les mots de votre texte en fonction de leur partie du discours.
En anglais, il y a huit parties de discours:
| Partie du discours | Rôle | Exemples |
|---|---|---|
| Nom | Est une personne, un lieu ou une chose | montagne, bagel, Pologne |
| Pronom | Remplace un nom | toi, elle, nous |
| Adjectif | Donne des informations sur ce à quoi ressemble un nom | efficace, venteux, coloré |
| Verbe | Est une action ou un état d'être | apprendre, c'est, aller |
| Adverbe | Donne des informations sur un verbe, un adjectif ou un autre adverbe | efficacement, toujours, très |
| Préposition | Donne des informations sur la manière dont un nom ou un pronom est connecté à un autre mot | à partir de, environ, à |
| Conjonction | Relie deux autres mots ou phrases | alors, parce que, et |
| Interjection | Est une exclamation | yay, ow, wow |
Certaines sources incluent également la catégorie des articles (comme «un» ou «le») dans la liste des parties du discours, mais d'autres sources les considèrent comme des adjectifs. NLTK utilise le mot déterminant se référer aux articles.
Voici comment importer les parties pertinentes de NLTK afin de baliser des parties de discours:
>>> de nltk.tokenize importer word_tokenize
Créez maintenant du texte à baliser. Vous pouvez utiliser cette citation de Carl Sagan:
>>> citation_sagan = "" "
... Si vous souhaitez faire une tarte aux pommes à partir de zéro,
... vous devez d'abord inventer l'univers. "" "
Utiliser word_tokenize pour séparer les mots de cette chaîne et les stocker dans une liste:
>>> words_in_sagan_quote = word_tokenize(citation_sagan)
Appelez maintenant nltk.pos_tag () sur votre nouvelle liste de mots:
>>> importer nltk
>>> nltk.pos_tag(words_in_sagan_quote)
[('Si''IN')[('Si''IN')[('If''IN')[('If''IN')
('vous', 'PRP'),
('souhait', 'VBP'),
('à', 'TO'),
('faire', 'VB'),
('et T'),
('pomme', 'NN'),
('tarte', 'NN'),
('de', 'IN'),
('scratch', 'NN'),
(',', ','),
('vous', 'PRP'),
('doit', 'MD'),
('premier', 'VB'),
('inventer', 'VB'),
(«le», «DT»),
('univers', 'NN'),
('.', '.')]
Tous les mots de la citation sont maintenant dans un tuple séparé, avec une balise qui représente leur partie du discours. Mais que signifient les balises? Voici comment obtenir une liste de balises et leur signification:
>>> nltk.aider.upenn_tagset()
La liste est assez longue, mais n'hésitez pas à développer la case ci-dessous pour la voir.
Voici la liste des balises de point de vente et leur signification:
>>> nltk.aider.upenn_tagset()
$: dollar
$ - $ - $ A $ C $ HK $ M $ NZ $ S $ États-Unis $ US $
'': guillemet fermant
'' '
(: parenthèse ouvrante
([{[{[[
): parenthèse fermante
)]
,: virgule
,
--: tiret
-
.: terminateur de phrase
. ! ?
:: deux points ou points de suspension
:; ...
CC: conjonction, coordination
& 'n et les deux mais soit et pour moins moins ni ni ni plus donc
donc fois v. versus vs si encore
CD: chiffre, cardinal
mi-1890 neuf heures trente quarante-deux un dixième dix millions 0,5 un quarante-deux
sept 1987 vingt '79 zéro deux 78 degrés quatre-vingt-quatre IX '60s 0,025
quinze 271,124 douzaines de quintillions de DM2 000 ...
DT: déterminant
tous un autre tous les deux de chacun soit tous les moitié la beaucoup beaucoup plus nary
ni aucun tel que le eux ces ce ces
EX: existentiel là-bas
là
FW: mot étranger
gemeinschaft hund ich jeux habeas Haementeria Herr K'ang-si vous
lutihaw alai je jour objets salutaris fille quibusdam pas trop Monte
terram fiche oui corporis ...
IN: préposition ou conjonction, subordonnant
à califourchon entre les montées, que ce soit à l'intérieur des pro malgré tout
ci-dessous à l'intérieur pour vers près derrière au sommet autour si comme jusqu'à ci-dessous
suivant dans si à côté ...
JJ: adjectif ou chiffre, ordinal
troisième mal élevé d'avant-guerre regrettable huilé calamiteux premier séparable
ectoplasmic batterie participative quatrième encore à nommer
multilingue multidisciplinaire ...
JJR: adjectif, comparatif
plus sombre braver breezier briefer plus brillant plus large pare-chocs plus occupé
plus calme moins cher plus sélectif nettoyant plus proche plus froid roturier plus cher
plus douillet crémeux plus croustillant plus mignon ...
JJS: adjectif, superlatif
le plus calme le moins cher le plus classe le plus propre le plus clair le plus proche le plus commun
corniest costliest crassest creepiest crudest cute plus darkest deadliest
le plus cher le plus profond le plus dense le plus dinkiest ...
LS: marqueur d'élément de liste
A A. B B. C C. D E F Premier G H I J K Un SP-44001 SP-44002 SP-44005
SP-44007 Deuxième Troisième Trois Deux * a b c d cinq premiers quatre un six trois
deux
MD: auxiliaire modal
peut ne peut pas pourrait ne pas oser peut doit avoir besoin devrait devrait
ne devrait pas vouloir
NN: nom, commun, singulier ou masse
Thermostat de hangar afghan
investissement diapositive humour chute lisse hyène du vent remplacer la sous-humanité
machiniste ...
NNP: nom, propre, singulier
Motown Venneboerger Czestochwa Ranzer Conchita Trumplane Christos
Oceanside Escobar Kreisler Sawyer Cougar Yvette Ervin ODI Darryl CTCA
Shannon A.K.C. Meltex Liverpool ...
NNPS: nom, propre, pluriel
Américains Amériques Amharas Amityvilles Amusements Anarcho-syndicalistes
Andalousie Andes Andruses Anges Animaux Anthony Antilles Antiquités
Apache Apaches Apocryphes ...
NNS: nom, commun, pluriel
étudiants de premier cycle scotches produits bric-à-brac gardes du corps facettes côtes
dessaisissements entrepôts conçoit des clubs fragrances moyennes
les appréhensions subjectivistes muses les emplois-usines ...
PDT: pré-déterminant
tous les deux la moitié tellement sûrs que
POS: marqueur génitif
'' s
PRP: pronom, personnel
elle-même lui-même lui-même elle-même moi-même
nous-mêmes nous-mêmes elle vous les leurs eux-mêmes
PRP $: pronom, possessif
son son mien mon notre nôtre leur votre votre
RB: adverbe
occasionnellement sans relâche de manière exaspérante et aventureuse
techniquement en grande partie de façon émouvante et magistériquement majoritairement
rapidement impitoyablement financièrement ...
RBR: adverbe, comparatif
plus sombre plus grand plus grave plus grimmer plus dur plus dur
plus sain plus lourd plus haut mais plus gros plus tard plus maigre plus long moins-
parfaitement moins solitaire plus fort plus bas plus ...
RBS: adverbe, superlatif
meilleur le plus gros le plus tôt le plus éloigné le plus éloigné le plus dur
le plus fort le plus élevé le moins le moins le plus proche le deuxième le plus serré
RP: particule
à bord à peu près à travers le long de l'écart autour de côté à l'arrière avant derrière
par recadrage toujours rapide pour aller de haut c'est-à-dire dans juste plus tard
faible plus sur ouvert sur par tarte levant les dents de départ qui traversent
sous jusqu'à up-pp sur tout avec toi
SYM: symbole
% & '' '' '. )). * +,. < = > @ UNE[fj] U.S U.R.S.S. * ** ***
TO: "to" comme préposition ou marqueur infinitif
à
UH: interjection
Au revoir Goody Gosh Wow Jeepers Jee-sus Hubba Hey Kee-reist Oops amen
hein howdy euh dammit whammo shucks diable de toute façon whodunnit honey golly
homme bébé diddle chut sonuvabitch ...
VB: verbe, forme de base
demander assembler évaluer attribuer assumer une attention particulière éviter de cuire balkaniser
banque commencez voir croire plier avantage biseau méfiez-vous bénir faire bouillir la bombe
boost brace break apporter la construction de la brosse de gril ...
VBD: verbe, passé
immergé plaidé balayé regommé trempé rangé convoqué arrêté enregistré
amorti exigé snobé enjambée visé adopté démenti figé
spéculé portait apprécié contemplé ...
VBG: verbe, participe présent ou gérondif
télégraphier remuer focaliser colère juger caler allaiter
hankerin 'alléguant virer le plafonnement approchant un assiégeant itinérant
crypter interrompre effacer grimacer ...
VBN: verbe, participe passé
multicoque délabré aérosol chaired languished panelized usagé
expérimenté épanoui imité réunifié factorisé condensé cisaillé
non réglé apprêté doublé désiré ...
VBP: verbe, présent, pas 3ème personne du singulier
prédominent wrap resort sue twist spill cure allonger brosse terminer
semblent avoir tendance à s'égarer briller obtenir comprendre détester taquiner attirer
mettre l'accent sur la moisissure retarder le retour du wag ...
VBZ: verbe, présent, 3e personne du singulier
les bases reconstruisent les marques les mélanges déplaisent aux phoques carpes tisse les bribes
les affaissements s'étendent autorise les smolders images émerge des stocks
séduit pétillante utilise traversins claques parle plaide ...
WDT: déterminant WH
que quoi que ce soit qui quel que soit
WP: pronom WH
que quoi quoi que ce soit qui qui qui que quiconque
WP $: pronom WH, possessif
à qui
WRB: Wh-adverbe
comment cependant d'où chaque fois où où où où et pourquoi pourquoi
``: guillemet ouvrant
C’est beaucoup à comprendre, mais heureusement, il existe des modèles pour vous aider à vous souvenir de quoi.
Voici un résumé que vous pouvez utiliser pour commencer à utiliser les balises de point de vente de NLTK:
| Balises commençant par | Traiter avec |
|---|---|
JJ |
Adjectifs |
NN |
Noms |
RB |
Les adverbes |
PRP |
Pronoms |
VB |
Verbes |
Maintenant que vous savez ce que signifient les balises POS, vous pouvez voir que votre marquage a été assez réussi:
'tarte'a été marquéNNparce que c’est un nom au singulier.'toi'a été marquéPRPparce que c’est un pronom personnel.'inventer'a été marquéVBcar c'est la forme de base d'un verbe.
Mais comment NLTK gérerait-il le marquage des parties du discours dans un texte qui est fondamentalement charabia? Jabberwocky est un poème absurde qui ne signifie pas grand-chose techniquement, mais qui est toujours écrit d’une manière qui peut transmettre une sorte de sens aux anglophones.
Faites une ficelle pour contenir un extrait de ce poème:
>>> jabberwocky_excerpt = "" "
... C'était génial, et les slithy toves ont fait gyre et gimble dans le wabe:
... tous les mimsy étaient les borogoves, et les mome raths outgrabe. "" "
Utiliser word_tokenize pour séparer les mots de l'extrait et les stocker dans une liste:
>>> words_in_excerpt = word_tokenize(jabberwocky_excerpt)
Appel nltk.pos_tag () sur votre nouvelle liste de mots:
>>> nltk.pos_tag(words_in_excerpt)
[("'T"'NN')[("'T"'NN')[("'T"'NN')[("'T"'NN')
('était', 'VBD'),
('brillig', 'VBN'),
(',', ','),
('et', 'CC'),
(«le», «DT»),
('slithy', 'JJ'),
('toves', 'NNS'),
('fait', 'VBD'),
('gyre', 'NN'),
('et', 'CC'),
('gimble', 'JJ'),
('dans', 'IN'),
(«le», «DT»),
('wabe', 'NN'),
(':', ':'),
('tous', 'DT'),
('mimsy', 'NNS'),
('étaient', 'VBD'),
(«le», «DT»),
('borogoves', 'NNS'),
(',', ','),
('et', 'CC'),
(«le», «DT»),
('mome', 'JJ'),
('raths', 'NNS'),
('outgrabe', 'RB'),
('.', '.')]
Mots anglais acceptés comme 'et' et 'les' ont été correctement étiquetés en tant que conjonction et déterminant, respectivement. Le mot charabia 'slithy' a été étiqueté comme un adjectif, ce qu'un anglophone humain supposerait probablement dans le contexte du poème également. Bravo, NLTK!
Lemmatisation
Maintenant que vous êtes au courant des parties du discours, vous pouvez revenir à la lemmatisation. Comme la tige, lemmatisant réduit les mots à leur signification fondamentale, mais cela vous donnera un mot anglais complet qui a du sens en soi au lieu d'un simple fragment d'un mot comme 'découvrir'.
Noter: UNE lemme est un mot qui représente tout un groupe de mots, et ce groupe de mots est appelé un lexème.
Par exemple, si vous recherchez le mot "mélange" dans un dictionnaire, vous devez alors consulter l'entrée "mélange", mais vous trouverez "fusion" dans cette entrée.
Dans cet exemple, «mélange» est le lemme, et le «mélange» fait partie de la lexème. Ainsi, lorsque vous lemmatisez un mot, vous le réduisez à son lemme.
Voici comment importer les parties pertinentes de NLTK afin de commencer la lemmatisation:
>>> de nltk.stem importer WordNetLemmatizer
Créez un lemmatiseur à utiliser:
>>> lemmatiseur = WordNetLemmatizer()
Commençons par lemmatiser un nom pluriel:
>>> lemmatiseur.lemmatiser("écharpes")
'écharpe'
"écharpes" vous a donné 'écharpe', donc c'est déjà un peu plus sophistiqué que ce que vous auriez obtenu avec la tige Porter, qui est 'scarv'. Ensuite, créez une chaîne avec plus d'un mot à lemmatiser:
>>> string_for_lemmatizing = "Les amis de DeSoto adorent les foulards."
Maintenant, tokenize cette chaîne par mot:
>>> mots = word_tokenize(string_for_lemmatizing)
Voici votre liste de mots:
>>> mots
['Le'['Le'['The'['The'
'copains',
'de',
«DeSoto»,
'l'amour'
'écharpes',
'.']
Créez une liste contenant tous les mots de mots après avoir été lemmatisées:
>>> mots_lemmatisés = [[[[lemmatiseur.lemmatiser(mot) pour mot dans mots]
Voici la liste que vous avez:
>>> mots_lemmatisés
['Le'['Le'['The'['The'
'ami',
'de',
«DeSoto»,
'l'amour',
'écharpe',
'.'
Cela semble juste. Les pluriels 'copains' et 'écharpes' sont devenus les singuliers 'ami' et 'écharpe'.
Mais que se passerait-il si vous lemmatisiez un mot qui avait l'air très différent de son lemme? Essayez la lemmatisation "pire":
>>> lemmatiseur.lemmatiser("pire")
'pire'
Vous avez le résultat 'pire' car lemmatizer.lemmatize () supposé que "pire" était un substantif. Vous pouvez indiquer clairement que vous voulez "pire" être un adjectif:
>>> lemmatiseur.lemmatiser("pire", pos="une")
'mal'
Le paramètre par défaut pour pos est 'n' pour nom, mais vous vous êtes assuré que "pire" a été traité comme un adjectif en ajoutant le paramètre pos = "a". En conséquence, vous avez 'mal', qui est très différent de votre mot d'origine et ne ressemble en rien à ce que vous obtiendriez si vous étiez issu. Ceci est dû au fait "pire" est la forme superlative de l'adjectif 'mal', et la lemmatisation réduit les superlatifs aussi bien que les comparatifs à leurs lemmes.
Maintenant que vous savez comment utiliser NLTK pour baliser des parties du discours, vous pouvez essayer de baliser vos mots avant de les lemmatiser pour éviter de mélanger des homographes, ou des mots qui sont épelés de la même manière mais qui ont des significations différentes et peuvent être des parties différentes du discours.
Regrouper
Alors que la création de jetons vous permet d'identifier des mots et des phrases, Regrouper vous permet d'identifier phrases.
Noter: UNE phrase est un mot ou un groupe de mots qui fonctionne comme une seule unité pour exécuter une fonction grammaticale. Phrases nominales sont construits autour d'un nom.
Voici quelques exemples:
- "Une planète"
- «Une planète qui s'incline»
- "Une planète qui s'incline rapidement"
Le chunking utilise des balises POS pour regrouper des mots et appliquer des balises chunk à ces groupes. Les blocs ne se chevauchent pas, donc une instance d'un mot ne peut être que dans un seul bloc à la fois.
Voici comment importer les parties pertinentes de NLTK afin de les découper:
>>> de nltk.tokenize importer word_tokenize
Avant de pouvoir segmenter, vous devez vous assurer que les parties du discours de votre texte sont balisées, créez donc une chaîne pour le balisage POS. Vous pouvez utiliser cette citation de Le Seigneur des Anneaux:
>>> lotr_quote = «C'est une affaire dangereuse, Frodon, sortir de chez vous.
Maintenant, tokenize cette chaîne par mot:
>>> words_in_lotr_quote = word_tokenize(lotr_quote)
>>> words_in_lotr_quote
['Il'['Il'['It'['It'
"'s",
'une',
'dangereux',
'affaires',
',',
«Frodon»,
',',
'Aller',
'en dehors',
'votre',
'porte',
'.']
Vous avez maintenant une liste de tous les mots de lotr_quote.
L'étape suivante consiste à marquer ces mots par partie du discours:
>>> nltk.Télécharger("average_perceptron_tagger")
>>> lotr_pos_tags = nltk.pos_tag(words_in_lotr_quote)
>>> lotr_pos_tags
[('It''PRP')[('It''PRP')[('It''PRP')[('It''PRP')
("'s",' VBZ '),
('a', 'DT'),
('dangereux', 'JJ'),
('entreprise', 'NN'),
(',', ','),
('Frodon', 'NNP'),
(',', ','),
('va', 'VBG'),
('out', 'RP'),
('votre', 'PRP $'),
('porte', 'NN'),
('.', '.')]
You’ve got a list of tuples of all the words in the quote, along with their POS tag. In order to chunk, you first need to define a chunk grammar.
Noter: UNE chunk grammar is a combination of rules on how sentences should be chunked. It often uses regular expressions, or regexes.
For this tutorial, you don’t need to know how regular expressions work, but they will definitely come in handy for you in the future if you want to process text.
Create a chunk grammar with one regular expression rule:
>>> grammar = "NP: ?*"
NP stands for noun phrase. You can learn more about noun phrase chunking in Chapter 7 of Natural Language Processing with Python—Analyzing Text with the Natural Language Toolkit.
According to the rule you created, your chunks:
- Start with an optional (
?) determiner ('DT') - Can have any number (
*) of adjectives (JJ) - End with a noun (
Create a chunk parser with this grammar:
>>> chunk_parser = nltk.RegexpParser(grammar)
Now try it out with your quote:
>>> tree = chunk_parser.parse(lotr_pos_tags)
Here’s how you can see a visual representation of this tree:
This is what the visual representation looks like:

You got two noun phrases:
'a dangerous business'has a determiner, an adjective, and a noun.'door'has just a noun.
Now that you know about chunking, it’s time to look at chinking.
Chinking
Chinking is used together with chunking, but while chunking is used to include a pattern, chinking is used to exclude a pattern.
Let’s reuse the quote you used in the section on chunking. You already have a list of tuples containing each of the words in the quote along with its part of speech tag:
>>> lotr_pos_tags
[('It''PRP')[('It''PRP')[('It''PRP')[('It''PRP')
("'s", 'VBZ'),
('a', 'DT'),
('dangerous', 'JJ'),
('business', 'NN'),
(',', ','),
('Frodo', 'NNP'),
(',', ','),
('going', 'VBG'),
('out', 'RP'),
('your', 'PRP$'),
('door', 'NN'),
('.', '.')]
The next step is to create a grammar to determine what you want to include and exclude in your chunks. This time, you’re going to use more than one line because you’re going to have more than one rule. Because you’re using more than one line for the grammar, you’ll be using triple quotes ("""):
>>> grammar = """
... Chunk: <.*>+
... """
The first rule of your grammar is <.*>+. This rule has curly braces that face inward () because it’s used to determine what patterns you want to include in you chunks. In this case, you want to include everything: <.*>+.
The second rule of your grammar is {) because it’s used to determine what patterns you want to exclude in your chunks. In this case, you want to exclude adjectives:
Create a chunk parser with this grammar:
>>> chunk_parser = nltk.RegexpParser(grammar)
Now chunk your sentence with the chink you specified:
>>> tree = chunk_parser.parse(lotr_pos_tags)
You get this tree as a result:
>>> tree
Tree('S', [Tree('Chunk', [('It', 'PRP'), ("'s", 'VBZ'), ('a', 'DT')]), ('dangerous', 'JJ'), Tree('Chunk', [('business', 'NN'), (',', ','), ('Frodo', 'NNP'), (',', ','), ('going', 'VBG'), ('out', 'RP'), ('your', 'PRP$'), ('door', 'NN'), ('.', '.')])])
In this case, ('dangerous', 'JJ') was excluded from the chunks because it’s an adjective (JJ). But that will be easier to see if you get a graphic representation again:
You get this visual representation of the tree:

Here, you’ve excluded the adjective 'dangerous' from your chunks and are left with two chunks containing everything else. The first chunk has all the text that appeared before the adjective that was excluded. The second chunk contains everything after the adjective that was excluded.
Now that you know how to exclude patterns from your chunks, it’s time to look into named entity recognition (NER).
Using Named Entity Recognition (NER)
Named entities are noun phrases that refer to specific locations, people, organizations, and so on. With named entity recognition, you can find the named entities in your texts and also determine what kind of named entity they are.
Here’s the list of named entity types from the NLTK book:
| NE type | Examples |
|---|---|
| ORGANIZATION | Georgia-Pacific Corp., WHO |
| PERSON | Eddy Bonte, President Obama |
| LOCATION | Murray River, Mount Everest |
| DATE | June, 2008-06-29 |
| TIME | two fifty a m, 1:30 p.m. |
| MONEY | 175 million Canadian dollars, GBP 10.40 |
| PERCENT | twenty pct, 18.75 % |
| FACILITY | Washington Monument, Stonehenge |
| GPE | South East Asia, Midlothian |
You can use nltk.ne_chunk() to recognize named entities. Let’s use lotr_pos_tags again to test it out:
>>> nltk.download("maxent_ne_chunker")
>>> nltk.download("words")
>>> tree = nltk.ne_chunk(lotr_pos_tags)
Now take a look at the visual representation:
Here’s what you get:

See how Frodo has been tagged as a PERSON? You also have the option to use the parameter binary=True if you just want to know what the named entities are but not what kind of named entity they are:
>>> tree = nltk.ne_chunk(lotr_pos_tags, binary=True)
>>> tree.draw()
Now all you see is that Frodo is an NE:

That’s how you can identify named entities! But you can take this one step further and extract named entities directly from your text. Create a string from which to extract named entities. You can use this quote from The War of the Worlds:
>>> quote = """
... Men like Schiaparelli watched the red planet—it is odd, by-the-bye, that
... for countless centuries Mars has been the star of war—but failed to
... interpret the fluctuating appearances of the markings they mapped so well.
... All that time the Martians must have been getting ready.
...
... During the opposition of 1894 a great light was seen on the illuminated
... part of the disk, first at the Lick Observatory, then by Perrotin of Nice,
... and then by other observers. English readers heard of it first in the
... issue of Nature dated August 2."""
Now create a function to extract named entities:
>>> def extract_ne(quote):
... words = word_tokenize(quote, language=language)
... tags = nltk.pos_tag(words)
... tree = nltk.ne_chunk(tags, binary=True)
... revenir ensemble(
... " ".join(je[[[[0] pour je in t)
... pour t in tree
... if hasattr(t, "label") et t.label() == "NE"
... )
With this function, you gather all named entities, with no repeats. In order to do that, you tokenize by word, apply part of speech tags to those words, and then extract named entities based on those tags. Because you included binary=True, the named entities you’ll get won’t be labeled more specifically. You’ll just know that they’re named entities.
Take a look at the information you extracted:
>>> extract_ne(quote)
'Lick Observatory', 'Mars', 'Nature', 'Perrotin', 'Schiaparelli'
You missed the city of Nice, possibly because NLTK interpreted it as a regular English adjective, but you still got the following:
- An institution:
'Lick Observatory' - A planet:
'Mars' - A publication:
'Nature' - People:
'Perrotin','Schiaparelli'
That’s some pretty decent variety!
Getting Text to Analyze
Now that you’ve done some text processing tasks with small example texts, you’re ready to analyze a bunch of texts at once. A group of texts is called a corpus. NLTK provides several corpora covering everything from novels hosted by Project Gutenberg to inaugural speeches by presidents of the United States.
In order to analyze texts in NLTK, you first need to import them. This requires nltk.download("book"), which is a pretty big download:
>>> nltk.download("book")
>>> de nltk.book import *
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908
You now have access to a few linear texts (such as Sense and Sensibility et Monty Python and the Holy Grail) as well as a few groups of texts (such as a chat corpus and a personals corpus). Human nature is fascinating, so let’s see what we can find out by taking a closer look at the personals corpus!
This corpus is a collection of personals ads, which were an early version of online dating. If you wanted to meet someone, then you could place an ad in a newspaper and wait for other readers to respond to you.
If you’d like to learn how to get other texts to analyze, then you can check out Chapter 3 of Natural Language Processing with Python – Analyzing Text with the Natural Language Toolkit.
Using a Concordance
When you use a concordance, you can see each time a word is used, along with its immediate context. This can give you a peek into how a word is being used at the sentence level and what words are used with it.
Let’s see what these good people looking for love have to say! The personals corpus is called text8, so we’re going to call .concordance() on it with the parameter "man":
>>> text8.concordance("man")
Displaying 14 of 14 matches:
to hearing from you all . ABLE young man seeks , sexy older women . Phone for
ble relationship . GENUINE ATTRACTIVE MAN 40 y . o ., no ties , secure , 5 ft .
ship , and quality times . VIETNAMESE MAN Single , never married , financially
ip . WELL DRESSED emotionally healthy man 37 like to meet full figured woman fo
nth subs LIKE TO BE MISTRESS of YOUR MAN like to be treated well . Bold DTE no
eeks lady in similar position MARRIED MAN 50 , attrac . fit , seeks lady 40 - 5
eks nice girl 25 - 30 serious rship . Man 46 attractive fit , assertive , and k
40 - 50 sought by Aussie mid 40s b / man f / ship r / ship LOVE to meet widowe
discreet times . Sth E Subs . MARRIED MAN 42yo 6ft , fit , seeks Lady for discr
woman , seeks professional , employed man , with interests in theatre , dining
tall and of large build seeks a good man . I am a nonsmoker , social drinker ,
lead to relationship . SEEKING HONEST MAN I am 41 y . o ., 5 ft . 4 , med . bui
quiet times . Seeks 35 - 45 , honest man with good SOH & similar interests , f
genuine , caring , honest and normal man for fship , poss rship . S / S , S /
Interestingly, the last three of those fourteen matches have to do with seeking an honest man, specifically:
SEEKING HONEST MANSeeks 35 - 45 , honest man with good SOH & similar interestsgenuine , caring , honest and normal man for fship , poss rship
Let’s see if there’s a similar pattern with the word "woman":
>>> text8.concordance("woman")
Displaying 11 of 11 matches:
at home . Seeking an honest , caring woman , slim or med . build , who enjoys t
thy man 37 like to meet full figured woman for relationship . 48 slim , shy , S
rry . MALE 58 years old . Is there a Woman who would like to spend 1 weekend a
other interests . Seeking Christian Woman for fship , view to rship . SWM 45 D
ALE 60 - burly beared seeks intimate woman for outings n / s s / d F / ston / P
ington . SCORPIO 47 seeks passionate woman for discreet intimate encounters SEX
le dad . 42 , East sub . 5 " 9 seeks woman 30 + for f / ship relationship TALL
personal trainer looking for married woman age open for fun MARRIED Dark guy 37
rinker , seeking slim - medium build woman who is happy in life , age open . AC
. O . TERTIARY Educated professional woman , seeks professional , employed man
real romantic , age 50 - 65 y . o . WOMAN OF SUBSTANCE 56 , 59 kg ., 50 , fit
The issue of honesty came up in the first match only:
Seeking an honest , caring woman , slim or med . build
Dipping into a corpus with a concordance won’t give you the full picture, but it can still be interesting to take a peek and see if anything stands out.
Making a Dispersion Plot
You can use a dispersion plot to see how much a particular word appears and where it appears. So far, we’ve looked for "man" et "woman", but it would be interesting to see how much those words are used compared to their synonyms:
>>> text8.dispersion_plot(
... [[[["woman", "lady", "girl", "gal", "man", "gentleman", "boy", "guy"]
... )
Here’s the dispersion plot you get:
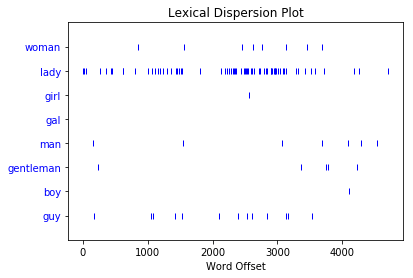
Each vertical blue line represents one instance of a word. Each horizontal row of blue lines represents the corpus as a whole. This plot shows that:
"lady"was used a lot more than"woman"ou alors"girl". There were no instances of"gal"."man"et"guy"were used a similar number of times and were more common than"gentleman"ou alors"boy".
You use a dispersion plot when you want to see where words show up in a text or corpus. If you’re analyzing a single text, this can help you see which words show up near each other. If you’re analyzing a corpus of texts that is organized chronologically, it can help you see which words were being used more or less over a period of time.
Staying on the theme of romance, see what you can find out by making a dispersion plot for Sense and Sensibility, which is text2. Jane Austen novels talk a lot about people’s homes, so make a dispersion plot with the names of a few homes:
>>> text2.dispersion_plot([[[["Allenham", "Whitwell", "Cleveland", "Combe"])
Here’s the plot you get:

Apparently Allenham is mentioned a lot in the first third of the novel and then doesn’t come up much again. Cleveland, on the other hand, barely comes up in the first two thirds but shows up a fair bit in the last third. This distribution reflects changes in the relationship between Marianne and Willoughby:
- Allenham is the home of Willoughby’s benefactress and comes up a lot when Marianne is first interested in him.
- Cleveland is a home that Marianne stays at after she goes to see Willoughby in London and things go wrong.
Dispersion plots are just one type of visualization you can make for textual data. The next one you’ll take a look at is frequency distributions.
Making a Frequency Distribution
With a frequency distribution, you can check which words show up most frequently in your text. You’ll need to get started with an import:
>>> de nltk import FreqDist
FreqDist is a subclass of collections.Counter. Here’s how to create a frequency distribution of the entire corpus of personals ads:
>>> frequency_distribution = FreqDist(text8)
>>> imprimer(frequency_distribution)
Since 1108 samples and 4867 outcomes is a lot of information, start by narrowing that down. Here’s how to see the 20 most common words in the corpus:
>>> frequency_distribution.most_common(20)
[(''539)[(''539)[(''539)[(''539)
('.', 353),
('/', 110),
('for', 99),
('and', 74),
('to', 74),
('lady', 68),
('-', 66),
('seeks', 60),
('a', 52),
('with', 44),
('S', 36),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('in', 27),
('slim', 27),
('build', 27),
('o', 26)]
You have a lot of stop words in your frequency distribution, but you can remove them just as you did earlier. Create a list of all of the words in text8 that aren’t stop words:
>>> meaningful_words = [[[[
... word pour word in text8 if word.casefold() ne pas in stop_words
... ]
Now that you have a list of all of the words in your corpus that aren’t stop words, make a frequency distribution:
>>> frequency_distribution = FreqDist(meaningful_words)
Take a look at the 20 most common words:
>>> frequency_distribution.most_common(20)
[(''539)[(''539)[(''539)[(''539)
('.', 353),
('/', 110),
('lady', 68),
('-', 66),
('seeks', 60),
('ship', 33),
('&', 30),
('relationship', 29),
('fun', 28),
('slim', 27),
('build', 27),
('smoker', 23),
('50', 23),
('non', 22),
('movies', 22),
('good', 21),
('honest', 20),
('dining', 19),
('rship', 18)]
You can turn this list into a graph:
>>> frequency_distribution.plot(20, cumulative=True)
Here’s the graph you get:

Some of the most common words are:
'lady''seeks''ship''relationship''fun''slim''build''smoker''50''non''movies''good''honest'
From what you’ve already learned about the people writing these personals ads, they did seem interested in honesty and used the word 'lady' beaucoup. In addition, 'slim' et 'build' both show up the same number of times. You saw slim et build used near each other when you were learning about concordances, so maybe those two words are commonly used together in this corpus. That brings us to collocations!
Finding Collocations
UNE collocation is a sequence of words that shows up often. If you’re interested in common collocations in English, then you can check out The BBI Dictionary of English Word Combinations. It’s a handy reference you can use to help you make sure your writing is idiomatic. Here are some examples of collocations that use the word “tree”:
- Syntax tree
- Family tree
- Decision tree
To see pairs of words that come up often in your corpus, you need to call .collocations() on it:
>>> text8.collocations()
would like; medium build; social drinker; quiet nights; non smoker;
long term; age open; Would like; easy going; financially secure; fun
times; similar interests; Age open; weekends away; poss rship; bien
presented; never married; single mum; permanent relationship; slim
build
slim build did show up, as did medium build and several other word combinations. No long walks on the beach though!
But what would happen if you looked for collocations after lemmatizing the words in your corpus? Would you find some word combinations that you missed the first time around because they came up in slightly varied versions?
If you followed the instructions earlier, then you’ll already have a lemmatizer, but you can’t call collocations() on just any data type, so you’re going to need to do some prep work. Start by creating a list of the lemmatized versions of all the words in text8:
>>> lemmatized_words = [[[[lemmatizer.lemmatize(word) pour word in text8]
But in order for you to be able to do the linguistic processing tasks you’ve seen so far, you need to make an NLTK text with this list:
>>> new_text = nltk.Text(lemmatized_words)
Here’s how to see the collocations in your new_text:
>>> new_text.collocations()
medium build; social drinker; non smoker; long term; would like; age
open; easy going; financially secure; Would like; quiet night; Âge
open; well presented; never married; single mum; permanent
relationship; slim build; year old; similar interest; fun time; photo
pls
Compared to your previous list of collocations, this new one is missing a few:
The idea of quiet nights still shows up in the lemmatized version, quiet night. Your latest search for collocations also brought up a few news ones:
year oldsuggests that users often mention ages.photo plssuggests that users often request one or more photos.
That’s how you can find common word combinations to see what people are talking about and how they’re talking about it!
Conclusion
Congratulations on taking your first steps with NLP! A whole new world of unstructured data is now open for you to explore. Now that you’ve covered the basics of text analytics tasks, you can get out there are find some texts to analyze and see what you can learn about the texts themselves as well as the people who wrote them and the topics they’re about.
Now you know how to:
- Find text to analyze
- Preprocess your text for analysis
- Analyze your text
- Create visualizations based on your analysis
For your next step, you can use NLTK to analyze a text to see whether the sentiments expressed in it are positive or negative. To learn more about sentiment analysis, check out Sentiment Analysis: First Steps With Python’s NLTK Library. If you’d like to dive deeper into the nuts and bolts of NLTK, then you can work your way through Natural Language Processing with Python—Analyzing Text with the Natural Language Toolkit.
Now get out there and find yourself some text to analyze!
[ad_2]