python pour débutant
- Le meilleur des tutoriels de test python, maintenant en epub, mobi et pdf
- Questions d'entretiens pour le poste de Data Engineer avec Python – Real Python
- Transcription pour Epsiode 23: Leçons sur les tests et le TDD de Kent Beck
- Épisode n ° 13: cadre web Flask et bien plus encore
- Développement Python dans le code Visual Studio (Guide d'installation) – Real Python
spaCy est une bibliothèque gratuite et open-source pour Traitement du langage naturel (PNL) en Python avec de nombreuses fonctionnalités intégrées. Il devient de plus en plus populaire pour le traitement et l’analyse de données en PNL. Les données textuelles non structurées sont produites à grande échelle et il est important de traiter et de tirer des conclusions des données non structurées. Pour ce faire, vous devez représenter les données dans un format compréhensible par les ordinateurs. La PNL peut vous aider à le faire.
Dans ce tutoriel, vous apprendrez:
- Quels sont les termes et concepts fondamentaux de la PNL?
- Comment implémenter ces concepts dans spaCy
- Comment personnaliser et étendre les fonctionnalités intégrées de spaCy
- Comment effectuer une analyse statistique de base sur un texte
- Comment créer un pipeline pour traiter du texte non structuré
- Comment analyser une phrase et en extraire des informations significatives
Que sont la PNL et SpaCy?
PNL est un sous-champ de Intelligence artificielle et concerne les interactions entre les ordinateurs et les langages humains. La PNL est le processus d'analyse, de compréhension et de dérivation de la signification des langages humains pour les ordinateurs.
La PNL vous aide à extraire des informations d'un texte non structuré et a plusieurs cas d'utilisation, tels que:
spaCy est une bibliothèque gratuite à code source ouvert pour la PNL en Python. Il est écrit en Cython et est conçu pour construire des systèmes d’extraction d’information ou de compréhension en langage naturel. Il est conçu pour une utilisation en production et fournit une API concise et conviviale.
Installation
Dans cette section, vous allez installer spaCy puis télécharger des données et des modèles pour la langue anglaise.
Comment installer spaCy
spaCy peut être installé en utilisant pépin, un gestionnaire de paquets Python. Vous pouvez utiliser un environnement virtuel à éviter en fonction des packages à l'échelle du système. Pour en savoir plus sur les environnements virtuels et pépin, découvrez What Is Pip? Un guide pour les nouveaux environnements pythonistes et virtuels Python: Guide d'introduction.
Créez un nouvel environnement virtuel:
Activez cet environnement virtuel et installez spaCy:
$ la source ./env/bin/activate
$ pip installer spacy
Comment télécharger des modèles et des données
SpaCy a différents types de modèles. Le modèle par défaut pour la langue anglaise est en_core_web_sm.
Activez l'environnement virtuel créé à l'étape précédente et téléchargez des modèles et des données pour la langue anglaise:
$ python -m spacy télécharger en_core_web_sm
Vérifiez si le téléchargement a réussi ou non en le chargeant:
>>> importation spacy
>>> nlp = spacy.charge('en_core_web_sm')
Si la nlp Lorsque l'objet est créé, cela signifie que spaCy a été installé et que les modèles et les données ont été téléchargés avec succès.
Utilisation de SpaCy
Dans cette section, vous utiliserez spaCy pour une chaîne de saisie donnée et un fichier texte. Chargez l'instance de modèle de langue dans spaCy:
>>> importation spacy
>>> nlp = spacy.charge('en_core_web_sm')
Ici le nlp objet est une instance de modèle de langage. Vous pouvez supposer que, tout au long de ce tutoriel, nlp fait référence au modèle de langage chargé par en_core_web_sm. Vous pouvez maintenant utiliser spaCy pour lire une chaîne ou un fichier texte.
Comment lire une chaîne
Vous pouvez utiliser spaCy pour créer un objet Doc traité, qui est un conteneur permettant d'accéder aux annotations linguistiques, pour une chaîne d'entrée donnée:
>>> introduction_text = ('Ce tutoriel concerne Natural'
... 'Traitement du langage dans Spacy.')
>>> introduction_doc = nlp(introduction_text)
>>> # Extraire les jetons pour le doc donné
>>> impression ([[[[jeton.texte pour jeton dans introduction_doc])
['This'Tutorial''''''about''Naturel''Langue'['This'Tutorial''''''about''Naturel''Langue'['This''tutorial''is''about''Natural''Language'['This''tutorial''is''about''Natural''Language'
'Traitement', 'dans', 'Spacy', '.']
Dans l'exemple ci-dessus, notez comment le texte est converti en un objet compris par spaCy. Vous pouvez utiliser cette méthode pour convertir n’importe quel texte en fichier traité. Doc objet et en déduire les attributs, qui seront abordés dans les prochaines sections.
Comment lire un fichier texte
Dans cette section, vous allez créer un objet Doc traité pour un fichier texte:
>>> nom de fichier = 'introduction.txt'
>>> introduction_file_text = ouvrir(nom de fichier).lis()
>>> introduction_file_doc = nlp(introduction_file_text)
>>> # Extraire les jetons pour le doc donné
>>> impression ([[[[jeton.texte pour jeton dans introduction_file_doc])
['This'Tutorial''''''about''Naturel''Langue'['This'Tutorial''''''about''Naturel''Langue'['This''tutorial''is''about''Natural''Language'['This''tutorial''is''about''Natural''Language'
'Traitement', 'dans', 'Spacy', '.', ' N']
Voici comment convertir un fichier texte en fichier traité. Doc objet.
Remarque:
Vous pouvez supposer que:
- Noms de variables se terminant par le suffixe
_textesont Objets chaîne Unicode. - Nom de variable se terminant par le suffixe
_docsont Objets modèles de langage de spaCy.
Détection de phrases
Détection de phrases est le processus de localisation du début et de la fin des phrases dans un texte donné. Cela vous permet de diviser un texte en unités significatives sur le plan linguistique. Vous utiliserez ces unités lors du traitement de votre texte pour effectuer des tâches telles que partie du balisage vocal et extraction d'entité.
Dans SpaCy, le senteurs propriété est utilisée pour extraire des phrases. Voici comment extraire le nombre total de phrases et les phrases pour un texte d’entrée donné:
>>> about_text = ("Gus Proto est un développeur Python actuellement"
... "Travailler pour une fintech basée à Londres"
... ' entreprise. Il s'intéresse à l'apprentissage '
... 'Traitement du langage naturel.')
>>> about_doc = nlp(about_text)
>>> Phrases = liste(about_doc.senteurs)
>>> len(Phrases)
2
>>> pour phrase dans Phrases:
... impression (phrase)
...
'Gus Proto est un développeur Python qui travaille actuellement pour un
Société Fintech basée à Londres.
"Il s'intéresse à l'apprentissage du traitement automatique du langage."
Dans l’exemple ci-dessus, SpaCy est correctement en mesure d’identifier des phrases en anglais, en utilisant un point final (.) comme délimiteur de phrase. Vous pouvez également personnaliser la détection de phrases pour détecter les phrases sur des délimiteurs personnalisés.
Voici un exemple où des points de suspension (...) est utilisé comme délimiteur:
>>> def set_custom_boundaries(doc):
... # Ajout du support pour utiliser `...` comme séparateur pour la détection de phrases
... pour jeton dans doc[:[:[:[:-1]:
... si jeton.texte == '...':
... doc[[[[jeton.je+1].is_sent_start = Vrai
... revenir doc
...
>>> ellipsis_text = ('Gus, peux-tu,… laisse tomber, j'ai oublié'
... 'ce que je disais. Alors, tu penses '
... ' nous devrions ...')
>>> # Charger une nouvelle instance de modèle
>>> custom_nlp = spacy.charge('en_core_web_sm')
>>> custom_nlp.add_pipe(set_custom_boundaries, avant='analyseur')
>>> custom_ellipsis_doc = custom_nlp(ellipsis_text)
>>> custom_ellipsis_sentences = liste(custom_ellipsis_doc.senteurs)
>>> pour phrase dans custom_ellipsis_sentences:
... impression(phrase)
...
Gus, peux-tu, ...
ça ne fait rien, j'ai oublié ce que je disais.
Alors, pensez-vous que nous devrions ...
>>> # Détection de phrases sans personnalisation
>>> points de suspension = nlp(ellipsis_text)
>>> ellipsis_sentences = liste(points de suspension.senteurs)
>>> pour phrase dans ellipsis_sentences:
... impression(phrase)
...
Gus, peux-tu, ... peu importe, j'ai oublié ce que je disais.
Alors, pensez-vous que nous devrions ...
Notez que custom_ellipsis_sentences contient trois phrases, alors que ellipsis_sentences contient deux phrases. Ces phrases sont toujours obtenues via le senteurs attribuer, comme vous avez vu auparavant.
Tokenization dans SpaCy
Tokenization est la prochaine étape après la détection de la phrase. Cela vous permet d'identifier les unités de base dans votre texte. Ces unités de base sont appelées jetons. La tokénisation est utile car elle divise un texte en unités significatives. Ces unités sont utilisées pour une analyse plus poussée, comme une partie du marquage de la parole.
Dans spaCy, vous pouvez imprimer des jetons en itérant sur le Doc objet:
>>> pour jeton dans about_doc:
... impression (jeton, jeton.idx)
...
Gus 0
Proto 4
est 10
un 13
Python 15
développeur 22
actuellement 32
travaillant 42
pour 50
un 54
Londres 56
- 62
basé 63
Fintech 69
entreprise 77
. 84
Il 86
est 89
intéressé 92
dans 103
apprentissage 106
Naturel 115
Langue 123
Traitement 132
. 142
Notez comment spaCy préserve la index de départ des jetons. C’est utile pour le remplacement de mots sur place. spaCy fournit divers attributs pour la Jeton classe:
>>> pour jeton dans about_doc:
... impression (jeton, jeton.idx, jeton.text_with_ws,
... jeton.is_alpha, jeton.is_punct, jeton.is_space,
... jeton.forme_, jeton.is_stop)
...
Gus 0 Gus Vrai Faux Faux Xxx Faux
Proto 4 Proto True False False Xxxxx False
est 10 est vrai faux faux faux xx vrai
a 13 a Vrai Faux Faux x Vrai
Python 15 Python True False False Xxxxx False
développeur 22 développeur True False False xxxx False
actuellement 32 actuellement vrai faux faux faux xxxx faux
travaillant 42 travaillant Vrai Faux Faux xxxx Faux
pour 50 pour True False False xxx True
a 54 a Vrai Faux Faux x Vrai
London 56 London True False False Xxxxx False
- 62 - Faux Vrai Faux - Faux
based 63 based True False False xxxx False
Fintech 69 Fintech Vrai Faux Faux Xxxxx Faux
société 77 société True False False xxxx False
. 84. Faux Vrai Faux. Faux
Il 86 Vrai Faux Faux Xx Vrai
est 89 est vrai faux faux faux xx vrai
intéressé 92 intéressé vrai faux faux xxxx faux
dans 103 dans True False False xx True
learning 106 learning True False False xxxx False
Naturel 115 Naturel Vrai Faux Faux Xxxxx Faux
Langage 123 Langage True False False Xxxxx False
Traitement 132 Traitement True False False Xxxxx False
. 142. Faux Vrai Faux. Faux
Dans cet exemple, certains des attributs généralement requis sont accessibles:
text_with_wsimprime le texte du jeton avec un espace de fin (si présent).is_alphadétecte si le jeton est constitué de caractères alphabétiques ou non.is_punctdétecte si le jeton est un symbole de ponctuation ou non.is_spacedétecte si le jeton est un espace ou non.forme_imprime la forme du mot.is_stopdétecte si le jeton est un mot vide ou non.
Remarque: Vous en apprendrez plus sur mots d'arrêt dans la section suivante.
Vous pouvez également personnaliser le processus de création de jetons pour détecter les jetons sur des caractères personnalisés. Ceci est souvent utilisé pour les mots avec trait d'union, qui sont des mots joints par un trait d'union. Par exemple, «basé à Londres» est un mot composé.
spaCy vous permet de personnaliser la tokenisation en mettant à jour le tokenizer propriété sur le nlp objet:
>>> importation ré
>>> importation spacy
>>> de spacy.tokenizer importation Tokenizer
>>> custom_nlp = spacy.charge('en_core_web_sm')
>>> prefix_re = spacy.util.compile_prefix_regex(custom_nlp.Défauts.préfixes)
>>> suffixe = spacy.util.compile_suffix_regex(custom_nlp.Défauts.suffixes)
>>> infix_re = ré.compiler(r'' '[-~]'' ')
>>> def personnaliser_tokenizer(nlp):
... # Ajoute le support pour utiliser `-` en tant que délimiteur pour la création de jetons
... revenir Tokenizer(nlp.vocab, prefix_search=prefix_re.chercher,
... suffix_search=suffixe.chercher,
... infix_finditer=infix_re.chercheur,
... token_match=Aucun
... )
...
>>> custom_nlp.tokenizer = personnaliser_tokenizer(custom_nlp)
>>> custom_tokenizer_about_doc = custom_nlp(about_text)
>>> impression([[[[jeton.texte pour jeton dans custom_tokenizer_about_doc])
['Gus''Proto''is''a''Python''developer''actuellement'['Gus''Proto''is''a''Python''developer''actuellement'['Gus''Proto''is''a''Python''developer''currently'['Gus''Proto''is''a''Python''developer''currently'
'travail', 'pour', 'a', 'Londres', '-', 'basé', 'Fintech',
'entreprise', '.', 'Il', 'est', 'intéressé', 'à', 'apprentissage',
'Naturel', 'Langue', 'Traitement', '.']
Pour que vous puissiez personnaliser, vous pouvez transmettre divers paramètres à la Tokenizer classe:
nlp.vocabest un conteneur de stockage pour les cas particuliers et est utilisé pour traiter des cas tels que les contractions et les émoticônes.prefix_searchest la fonction utilisée pour gérer la ponctuation précédente, telle que l'ouverture des parenthèses.infix_finditerest la fonction utilisée pour gérer les séparateurs non blancs, tels que les traits d'union.suffix_searchest la fonction utilisée pour gérer la ponctuation suivante, telle que la fermeture des parenthèses.token_matchest une fonction booléenne facultative utilisée pour faire correspondre les chaînes qui ne doivent jamais être scindées. Il remplace les règles précédentes et est utile pour les entités telles que les URL ou les nombres.
Remarque: SpaCy détecte déjà les mots coupés comme des jetons individuels. Le code ci-dessus est juste un exemple pour montrer comment la tokenization peut être personnalisée. Il peut être utilisé pour tout autre personnage.
Mots d'arrêt
Mots d'arrêt sont les mots les plus courants dans une langue. En anglais, quelques exemples de mots vides sont le, sont, mais, et ils. La plupart des phrases doivent contenir des mots vides pour être des phrases complètes qui ont un sens.
En règle générale, les mots vides sont supprimés car ils ne sont pas significatifs et faussent l’analyse de la fréquence des mots. spaCy a une liste de mots vides pour la langue anglaise:
>>> importation spacy
>>> spacy_stopwords = spacy.lang.en.mots d'arrêt.STOP_WORDS
>>> len(spacy_stopwords)
326
>>> pour stop_word dans liste(spacy_stopwords)[:[:[:[:dix]:
... impression(stop_word)
...
en utilisant
devient
eu
lui-même
une fois que
souvent
est
ici
qui
aussi
Vous pouvez supprimer les mots vides du texte saisi:
>>> pour jeton dans about_doc:
... si ne pas jeton.is_stop:
... impression (jeton)
...
Gus
Proto
Python
développeur
actuellement
travail
Londres
-
basé
Fintech
entreprise
.
intéressé
apprentissage
Naturel
La langue
En traitement
.
Des mots comme: est, une, pour, le, et dans ne sont pas imprimés dans la sortie ci-dessus. Vous pouvez également créer une liste de jetons ne contenant pas de mots vides:
>>> about_no_stopword_doc = [[[[jeton pour jeton dans about_doc si ne pas jeton.is_stop]
>>> impression (about_no_stopword_doc)
[GusProtoPythondevelopercercurrentlyingingLondon[GusProtoPythondevelopercercurrentlyingingLondon[GusProtoPythondevelopercurrentlyworkingLondon[GusProtoPythondevelopercurrentlyworkingLondon
-, basé, Fintech, société,., intéressé, en apprentissage, naturel,
Langue, traitement,]
about_no_stopword_doc peut être associé à des espaces pour former une phrase sans mots vides.
Lemmatisation
Lemmatisation est le processus de réduction des formes infléchies d’un mot tout en veillant à ce que la forme réduite appartienne à la langue. Cette forme réduite ou mot racine s'appelle un lemme.
Par exemple, organise, organisé et organiser sont toutes les formes de organiser. Ici, organiser est le lemma. L'inflexion d'un mot vous permet d'exprimer différentes catégories grammaticales comme le temps (organisé contre organiser), nombre (les trains contre train), etc. La lemmatisation est nécessaire car elle vous aide à réduire les formes infléchies d’un mot afin qu’elles puissent être analysées comme un élément unique. Cela peut aussi vous aider normaliser le texte.
spaCy a l'attribut lemme_ sur le Jeton classe. Cet attribut a la forme lemmatisée d'un jeton:
>>> conference_help_text = ("Gus aide à organiser un développeur"
... 'conférence sur les applications du langage naturel'
... ' En traitement. Il continue d'organiser des rencontres locales Python '
... 'et plusieurs entretiens internes sur son lieu de travail.')
>>> conference_help_doc = nlp(conference_help_text)
>>> pour jeton dans conference_help_doc:
... impression (jeton, jeton.lemme_)
...
Gus Gus
est être
aider à aider
organiser organiser
un a
développeur développeur
conférence conférence
sur sur
Applications Applications
de de
Naturel naturel
Langue langue
Traitement traitement
. .
Il -PRON-
garde garde
organiser organiser
local local
Python Python
rencontres rencontres
et et
plusieurs plusieurs
interne interne
parle parle
à
son -PRON-
lieu de travail lieu de travail
. .
Dans cet exemple, organiser réduit à sa forme de lemme organiser. Si vous ne lemmatisez pas le texte, alors organiser et organiser seront comptés comme des jetons différents, même s'ils ont une signification similaire. La lemmatisation vous aide à éviter les mots en double ayant une signification similaire.
Fréquence de mot
Vous pouvez maintenant convertir un texte donné en jetons et y effectuer une analyse statistique. Cette analyse peut vous donner diverses indications sur les modèles de mots, tels que des mots courants ou des mots uniques dans le texte:
>>> de collections importation Compteur
>>> complete_text = ("Gus Proto est un développeur Python actuellement"
... 'travaillant pour une société londonienne de Fintech. Il est'
... 'intéressé à apprendre le traitement automatique du langage.'
... "Une conférence de développeurs aura lieu le 21 juillet"
... 2019 à Londres. Il est intitulé "Applications of Natural '
... 'Traitement du langage ". Il y a un numéro d'assistance téléphonique'
... 'disponible au + 1-1234567891. Gus aide à l'organiser.
... "Il continue d'organiser des rencontres locales en Python et plusieurs"
... 'entretiens internes sur son lieu de travail. Gus présente aussi '
... ' une conversation. La présentation présentera au lecteur "Use '
... 'cas de traitement automatique du langage en Fintech ".
... "En dehors de son travail, il est très passionné de musique."
... «Gus apprend à jouer du piano. Il s'est inscrit
... "lui-même dans le lot de week-end de la Grande Académie de piano."
... «La grande académie de piano est située à Mayfair ou dans la ville»
... "de Londres et a des professeurs de piano de classe mondiale.")
...
>>> complete_doc = nlp(complete_text)
>>> # Supprimer les mots vides et les signes de ponctuation
>>> mots = [[[[jeton.texte pour jeton dans complete_doc
... si ne pas jeton.is_stop et ne pas jeton.is_punct]
>>> word_freq = Compteur(mots)
>>> # 5 mots courants avec leurs fréquences
>>> Mots communs = word_freq.Le plus commun(5)
>>> impression (Mots communs)
[('Gus', 4), ('London', 3), ('Natural', 3), ('Language', 3), ('Processing', 3)]
>>> # Mots uniques
>>> unique_words = [[[[mot pour (mot, fréq) dans word_freq.articles() si fréq == 1]
>>> impression (unique_words)
['Proto''actuellement''ouvrent''entreprise'['Proto''actuellement''ouvrent''entreprise'['Proto''currently''working''based''company'['Proto''currently''working''based''company'
'intéressé', 'conférence', 'passe', '21', 'juillet',
"2019", "intitulé", "Applications", "assistance téléphonique", "numéro",
'disponible', '+1', '1234567891', 'aider', 'organiser',
'garde', 'organise', 'local', 'meetingups', 'interne',
'discussions', 'lieu de travail', 'présentation', 'introduction', 'lecteur',
'Use', 'cases', 'Apart', 'work', 'passionné', 'music', 'play',
'inscrits', 'week-end', 'lot', 'situé', 'Mayfair', 'Ville',
'monde', 'classe', 'piano', 'instructors']
En regardant les mots courants, vous pouvez voir que le texte dans son ensemble parle probablement de Gus, Londres, ou Traitement du langage naturel. De cette façon, vous pouvez prendre n’importe quel texte non structuré et effectuer une analyse statistique pour savoir de quoi il s’agit.
Voici un autre exemple du même texte avec des mots vides:
>>> mots_tous = [[[[jeton.texte pour jeton dans complete_doc si ne pas jeton.is_punct]
>>> word_freq_all = Compteur(mots_tous)
>>> # 5 mots courants avec leurs fréquences
>>> common_words_all = word_freq_all.Le plus commun(5)
>>> impression (common_words_all)
[('is', 10), ('a', 5), ('in', 5), ('Gus', 4), ('of', 4)]
Quatre des cinq mots les plus courants sont des mots vides, qui ne vous en disent pas beaucoup sur le texte. Si vous considérez des mots vides lors de l'analyse de la fréquence des mots, vous ne pourrez pas obtenir d'informations pertinentes à partir du texte saisi. C'est pourquoi il est si important de supprimer les mots vides.
Une partie du marquage de la parole
Partie du discours ou POS est un rôle grammatical qui explique comment un mot particulier est utilisé dans une phrase. Il y a huit parties du discours:
- Nom
- Pronom
- Adjectif
- Verbe
- Adverbe
- Préposition
- Conjonction
- Interjection
Une partie du marquage vocal est le processus d'attribution d'un Étiquette de point de vente à chaque jeton en fonction de son utilisation dans la phrase. Les balises POS sont utiles pour attribuer une catégorie syntaxique comme nom ou verbe à chaque mot.
Dans spaCy, les balises POS sont disponibles en tant qu’attribut sur le Jeton objet:
>>> pour jeton dans about_doc:
... impression (jeton, jeton.étiquette_, jeton.pos_, spacy.Explique(jeton.étiquette_))
...
Gus NNP PROPN nom, singulier propre
Proto NNP PROPN nom, singulier propre
est le verbe VBZ VERB, 3ème personne du singulier présent
un déterminant DT DET
Python NNP PROPN nom, singulier propre
développeur NN NOUN nom, singulier ou masse
actuellement l'adverbe RB ADV
participe actif verbe, gérondif ou présent VBG VERB
pour une connexion, un subordonnement ou une préposition IN ADP
un déterminant DT DET
London NNP PROPN nom, singulier propre
- ponctuation HYPH PUNCT, trait d'union
verbe VBN VERB basé, participe passé
Fintech NNP PROPN nom, singulier propre
company NN NOUN nom, singulier ou masse
. . Ponctuation PUNCT, phrase plus proche
PRP PRON pronom personnel
est le verbe VBZ VERB, 3ème personne du singulier présent
adjectif JJ ADJ intéressé
en conjonction, subordination ou préposition IN ADP
apprentissage du verbe VBG VERB, du gérondif ou du participe présent
Natural NNP PROPN nom, singulier propre
Langue NNP PROPN nom, singulier propre
Processing NNP PROPN nom, singulier propre
. . Ponctuation PUNCT, phrase plus proche
Ici, deux attributs de la Jeton les classes sont accessibles:
étiquette_liste la partie fine du discours.pos_répertorie la partie à grain grossier du discours.
spacy.explain donne des détails descriptifs sur une étiquette de point de vente particulière. spaCy fournit une liste complète de balises ainsi qu'une explication pour chaque balise.
À l’aide des balises POS, vous pouvez extraire une catégorie de mots particulière:
>>> les noms = []
>>> adjectifs = []
>>> pour jeton dans about_doc:
... si jeton.pos_ == 'NOM':
... les noms.ajouter(jeton)
... si jeton.pos_ == 'ADJ':
... adjectifs.ajouter(jeton)
...
>>> les noms
[developer, company]
>>> adjectifs
[interested]
Vous pouvez vous en servir pour obtenir des informations, supprimer les noms les plus courants ou voir quels adjectifs sont utilisés pour un nom particulier.
Visualisation: utilisation de l'affichage
SpaCy est livré avec un visualiseur intégré appelé le malheur. Vous pouvez l'utiliser pour visualiser un analyse de dépendance ou entités nommées dans un navigateur ou un ordinateur portable Jupyter.
Vous pouvez utiliser display pour trouver les tags POS pour les jetons:
>>> de spacy importation déplacement
>>> about_interest_text = ("Il s'intéresse à l'apprentissage"
... 'Traitement du langage naturel.')
>>> about_interest_doc = nlp(about_interest_text)
>>> déplacement.servir(about_interest_doc, style='dep')
Le code ci-dessus fera tourner un serveur Web simple. Vous pouvez voir la visualisation en ouvrant http://127.0.0.1:5000 dans votre navigateur:

Dans l'image ci-dessus, chaque jeton se voit attribuer une étiquette de point de vente écrite juste en dessous du jeton.
Remarque: Voici comment utiliser l'affichage dans un cahier Jupyter:
>>> déplacement.rendre(about_interest_doc, style='dep', Jupyter=Vrai)
Fonctions de prétraitement
Vous pouvez créer un fonction de prétraitement qui prend du texte en entrée et applique les opérations suivantes:
- Minuscules le texte
- Lemmatise chaque jeton
- Supprime les symboles de ponctuation
- Supprime les mots vides
Une fonction de prétraitement convertit le texte en un format analysable. C’est nécessaire pour la plupart des tâches de la PNL. Voici un exemple:
>>> def is_token_allowed(jeton):
... '' '
... Autorise uniquement les jetons valides qui ne sont pas des mots vides
... et symboles de ponctuation.
... '' '
... si (ne pas jeton ou ne pas jeton.chaîne.bande() ou
... jeton.is_stop ou jeton.is_punct):
... revenir Faux
... revenir Vrai
...
>>> def preprocess_token(jeton):
... # Réduit le jeton à sa forme de lemme minuscule
... revenir jeton.lemme_.bande().inférieur()
...
>>> complete_filtered_tokens = [[[[preprocess_token(jeton)
... pour jeton dans complete_doc si is_token_allowed(jeton)]
>>> complete_filtered_tokens
['gus''proto''python''developer''Currently''work'['gus''proto''python''developer''Currently''work'['gus''proto''python''developer''currently''work'['gus''proto''python''developer''currently''work'
«londres», «base», «fintech», «entreprise», «intéressé», «apprendre»,
'naturel', 'langage', 'traitement', 'développeur', 'conférence',
'arrive', '21', 'juillet', '2019', 'londres', 'titre',
'applications', 'naturel', 'langage', 'traitement', 'ligne d'assistance',
'numéro', 'disponible', '+1', '1234567891', 'gus', 'aide',
'organiser', 'garder', 'organiser', 'local', 'python', 'meetup',
'interne', 'parler', 'lieu de travail', 'gus', 'présent', 'parler', 'parler',
'introduire', 'lecteur', 'utiliser', 'cas', 'naturel', 'langue',
"traitement", "fintech", "apart", "travail", "passionné", "musique",
'gus', 'apprendre', 'jouer', 'piano', 'inscrire', 'weekend', 'batch',
'grand', 'piano', 'académie', 'grand', 'piano', 'académie',
'situate', 'mayfair', 'city', 'london', 'world', 'class',
'piano', 'instructeur']
Notez que le complete_filtered_tokens ne contient aucun mot d’arrêt ni symbole de ponctuation et consiste en jetons minuscules lemmatisés.
Correspondance basée sur des règles Utilisation de spaCy
Correspondance basée sur des règles est l'une des étapes à suivre pour extraire des informations d'un texte non structuré. Il est utilisé pour identifier et extraire des jetons et des phrases en fonction de modèles (tels que des minuscules) et de caractéristiques grammaticales (telles qu'une partie du discours).
La correspondance basée sur des règles peut utiliser des expressions régulières pour extraire des entités (telles que des numéros de téléphone) d'un texte non structuré. Cela diffère de l'extraction de texte à l'aide d'expressions régulières uniquement dans le sens où elles ne prennent pas en compte les attributs lexicaux et grammaticaux du texte.
Avec la correspondance basée sur des règles, vous pouvez extraire un prénom et un nom de famille, qui sont toujours noms propres:
>>> de spacy.matcher importation Matcher
>>> matcher = Matcher(nlp.vocab)
>>> def extract_full_name(nlp_doc):
... modèle = [{[{[{['POS': 'PROPN', 'POS': 'PROPN']
... matcher.ajouter('NOM COMPLET', Aucun, modèle)
... allumettes = matcher(nlp_doc)
... pour match_id, début, fin dans allumettes:
... envergure = nlp_doc[[[[début:fin]
... revenir envergure.texte
...
>>> extract_full_name(about_doc)
'Gus Proto'
Dans cet exemple, modèle est une liste d'objets qui définit la combinaison de jetons à faire correspondre. Les deux étiquettes de point de vente sont PROPN (nom propre). Alors le modèle se compose de deux objets dans lesquels les balises POS pour les deux jetons doivent être PROPN. Ce motif est ensuite ajouté à Matcher en utilisant NOM COMPLET et le la match_id. Enfin, les correspondances sont obtenues avec leurs index de début et de fin.
Vous pouvez également utiliser la correspondance basée sur des règles pour extraire les numéros de téléphone:
>>> de spacy.matcher importation Matcher
>>> matcher = Matcher(nlp.vocab)
>>> conference_org_text = ("Il y a une conférence de développeurs"
... qui se passe le 21 juillet 2019 à Londres. Il est intitulé '
... "" Applications du traitement automatique du langage "."
... "Il y a un numéro d'assistance téléphonique disponible"
... 'au (123) 456-789')
...
>>> def extract_phone_number(nlp_doc):
... modèle = [{[{[{['ORTH': '(', 'FORME': 'ddd',
... 'ORTH': ')', 'FORME': 'ddd',
... 'ORTH': '-', 'OP': '?',
... 'FORME': 'ddd']
... matcher.ajouter('NUMÉRO DE TÉLÉPHONE', Aucun, modèle)
... allumettes = matcher(nlp_doc)
... pour match_id, début, fin dans allumettes:
... envergure = nlp_doc[[[[début:fin]
... revenir envergure.texte
...
>>> conference_org_doc = nlp(conference_org_text)
>>> extract_phone_number(conference_org_doc)
'(123) 456-789'
Dans cet exemple, seul le modèle est mis à jour afin de correspondre aux numéros de téléphone de l'exemple précédent. Ici, certains attributs du jeton sont également utilisés:
ORTHdonne le texte exact du jeton.FORMEtransforme la chaîne de jeton pour afficher les caractéristiques orthographiques.OPdéfinit les opérateurs. En utilisant?en tant que valeur signifie que le motif est facultatif, ce qui signifie qu'il peut correspondre à 0 ou 1 fois.
Remarque: Pour simplifier, les numéros de téléphone sont supposés être d'un format particulier: (123) 456-789. Vous pouvez modifier cela en fonction de votre cas d'utilisation.
La correspondance basée sur des règles vous aide à identifier et à extraire des jetons et des phrases en fonction de modèles lexicaux (tels que des minuscules) et de caractéristiques grammaticales (telles qu'une partie du discours).
Analyse de dépendance à l'aide de spaCy
Analyse de dépendance est le processus d'extraction de l'analyse de dépendance d'une phrase pour représenter sa structure grammaticale. Il définit la relation de dépendance entre mots-clés et leur personnes à charge. La tête d'une phrase n'a pas de dépendance et s'appelle le racine de la phrase. le verbe est généralement la tête de la phrase. Tous les autres mots sont liés au mot-clé.
Les dépendances peuvent être mappées dans une représentation graphique dirigée:
- Les mots sont les nœuds.
- Les relations grammaticales sont les bords.
L'analyse des dépendances vous aide à savoir le rôle joué par un mot dans le texte et la relation entre différents mots. Il est également utilisé dans analyse superficielle et reconnaissance d'entité nommée.
Voici comment utiliser l'analyse de dépendance pour voir les relations entre les mots:
>>> piano_text = 'Gus apprend le piano'
>>> piano_doc = nlp(piano_text)
>>> pour jeton dans piano_doc:
... impression (jeton.texte, jeton.étiquette_, jeton.tête.texte, jeton.dep_)
...
Gus NNP learning nsubj
est-ce que VBZ apprend aux
apprendre VBG apprendre ROOT
piano NN apprentissage dobj
Dans cet exemple, la phrase contient trois relations:
nsubjest le sujet de la parole. Son mot-clé est un verbe.auxest un mot auxiliaire. Son mot-clé est un verbe.Dobjest l'objet direct du verbe. Son mot-clé est un verbe.
Il existe une liste détaillée des relations avec les descriptions. Vous pouvez utiliser display pour visualiser l’arbre de dépendance:
>>> déplacement.servir(piano_doc, style='dep')
Ce code produira une visualisation accessible en ouvrant http://127.0.0.1.1000 dans votre navigateur:
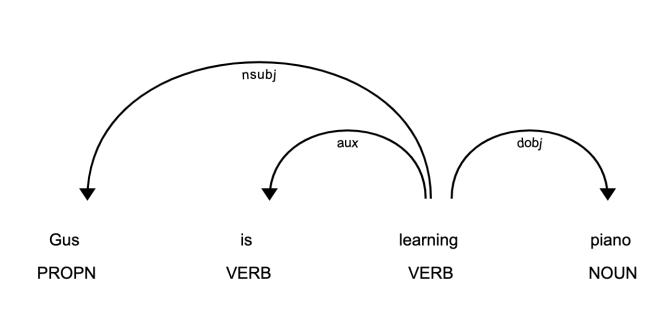
Cette image vous montre que le sujet de la phrase est le nom propre Gus et qu'il a apprendre relation avec piano.
Navigation dans l'arbre et le sous-arbre
L'arbre d'analyse de dépendance a toutes les propriétés d'un arbre. Cet arbre contient des informations sur la structure de la phrase et la grammaire et peut être parcouru de différentes manières pour extraire des relations.
spaCy fournit des attributs tels que les enfants, gauches, droits, et sous-arbre pour naviguer dans l'arbre d'analyse:
>>> one_line_about_text = ("Gus Proto est un développeur Python"
... "travaille actuellement pour une société londonienne Fintech")
>>> one_line_about_doc = nlp(one_line_about_text)
>>> # Extraire les enfants de `developer`
>>> impression([[[[jeton.texte pour jeton dans one_line_about_doc[[[[5].les enfants])
['a', 'Python', 'working']
>>> # Extrait le noeud voisin précédent de `developer`
>>> impression (one_line_about_doc[[[[5].nbor(-1))
Python
>>> # Extrait le prochain noeud voisin de `developer`
>>> impression (one_line_about_doc[[[[5].nbor())
actuellement
>>> # Extrait tous les jetons à gauche de `developer`
>>> impression([[[[jeton.texte pour jeton dans one_line_about_doc[[[[5].gauches])
['a', 'Python']
>>> # Extraire les jetons à droite de `developer`
>>> impression([[[[jeton.texte pour jeton dans one_line_about_doc[[[[5].droits])
['working']
>>> # Imprimer la sous-arborescence de `developer`
>>> impression (liste(one_line_about_doc[[[[5].subtree))
[aPythondevelopercurrentlyworkingforaLondon-[aPythondevelopercurrentlyworkingforaLondon-[aPythondevelopercurrentlyworkingforaLondon-[aPythondevelopercurrentlyworkingforaLondon-
based, Fintech, company]
You can construct a function that takes a subtree as an argument and returns a string by merging words in it:
>>> def flatten_tree(arbre):
... revenir ''.joindre([[[[jeton.text_with_ws pour jeton dans liste(arbre)]).bande()
...
>>> # Print flattened subtree of `developer`
>>> impression (flatten_tree(one_line_about_doc[[[[5].subtree))
a Python developer currently working for a London-based Fintech company
You can use this function to print all the tokens in a subtree.
Shallow Parsing
Shallow parsing, ou chunking, is the process of extracting phrases from unstructured text. Chunking groups adjacent tokens into phrases on the basis of their POS tags. There are some standard well-known chunks such as noun phrases, verb phrases, and prepositional phrases.
Noun Phrase Detection
A noun phrase is a phrase that has a noun as its head. It could also include other kinds of words, such as adjectives, ordinals, determiners. Noun phrases are useful for explaining the context of the sentence. They help you infer quoi is being talked about in the sentence.
spaCy has the property noun_chunks sur Doc object. You can use it to extract noun phrases:
>>> conference_text = ('There is a developer conference'
... ' happening on 21 July 2019 in London.')
>>> conference_doc = nlp(conference_text)
>>> # Extract Noun Phrases
>>> pour tronçon dans conference_doc.noun_chunks:
... impression (tronçon)
...
a developer conference
21 July
Londres
By looking at noun phrases, you can get information about your text. Par exemple, a developer conference indicates that the text mentions a conference, while the date 21 July lets you know that conference is scheduled for 21 July. You can figure out whether the conference is in the past or the future. Londres tells you that the conference is in Londres.
Verb Phrase Detection
UNE phrase verbale is a syntactic unit composed of at least one verb. This verb can be followed by other chunks, such as noun phrases. Verb phrases are useful for understanding the actions that nouns are involved in.
spaCy has no built-in functionality to extract verb phrases, so you’ll need a library called textacy:
Remarque:
You can use pépin à installer textacy:
Now that you have textacy installed, you can use it to extract verb phrases based on grammar rules:
>>> importation textacy
>>> about_talk_text = ('The talk will introduce reader about Use'
... ' cases of Natural Language Processing in'
... ' Fintech')
>>> modèle = r'(?*+)'
>>> about_talk_doc = textacy.make_spacy_doc(about_talk_text,
... lang='en_core_web_sm')
>>> verb_phrases = textacy.extrait.pos_regex_matches(about_talk_doc, modèle)
>>> # Print all Verb Phrase
>>> pour tronçon dans verb_phrases:
... impression(tronçon.texte)
...
will introduce
>>> # Extract Noun Phrase to explain what nouns are involved
>>> pour tronçon dans about_talk_doc.noun_chunks:
... impression (tronçon)
...
The talk
lecteur
Use cases
Natural Language Processing
Fintech
In this example, the verb phrase présenter indicates that something will be introduced. By looking at noun phrases, you can see that there is a parler ça va présenter le lecteur à cas d'utilisation de Natural Language Processing ou Fintech.
The above code extracts all the verb phrases using a regular expression pattern of POS tags. You can tweak the pattern for verb phrases depending upon your use case.
Remarque: In the previous example, you could have also done dependency parsing to see what the relationships between the words were.
Named Entity Recognition
Named Entity Recognition (NER) is the process of locating named entities in unstructured text and then classifying them into pre-defined categories, such as person names, organizations, locations, monetary values, percentages, time expressions, and so on.
You can use NER to know more about the meaning of your text. For example, you could use it to populate tags for a set of documents in order to improve the keyword search. You could also use it to categorize customer support tickets into relevant categories.
spaCy has the property ents sur Doc objects. You can use it to extract named entities:
>>> piano_class_text = ('Great Piano Academy is situated'
... ' in Mayfair or the City of London and has'
... ' world-class piano instructors.')
>>> piano_class_doc = nlp(piano_class_text)
>>> pour ent dans piano_class_doc.ents:
... impression(ent.texte, ent.start_char, ent.end_char,
... ent.label_, spacy.Explique(ent.label_))
...
Great Piano Academy 0 19 ORG Companies, agencies, institutions, etc.
Mayfair 35 42 GPE Countries, cities, states
the City of London 46 64 GPE Countries, cities, states
In the above example, ent est un Envergure object with various attributes:
textegives the Unicode text representation of the entity.start_chardenotes the character offset for the start of the entity.end_chardenotes the character offset for the end of the entity.label_gives the label of the entity.
spacy.explain gives descriptive details about an entity label. The spaCy model has a pre-trained list of entity classes. You can use displaCy to visualize these entities:
>>> displacy.servir(piano_class_doc, style='ent')
If you open http://127.0.0.1:5000 in your browser, then you can see the visualization:

You can use NER to redact people’s names from a text. For example, you might want to do this in order to hide personal information collected in a survey. You can use spaCy to do that:
>>> survey_text = ('Out of 5 people surveyed, James Robert,'
... ' Julie Fuller and Benjamin Brooks like'
... ' apples. Kelly Cox and Matthew Evans'
... ' like oranges.')
...
>>> def replace_person_names(jeton):
... si jeton.ent_iob != 0 et jeton.ent_type_ == 'PERSON':
... revenir '[REDACTED] '
... revenir jeton.chaîne
...
>>> def redact_names(nlp_doc):
... pour ent dans nlp_doc.ents:
... ent.fusionner()
... jetons = carte(replace_person_names, nlp_doc)
... revenir ''.joindre(jetons)
...
>>> survey_doc = nlp(survey_text)
>>> redact_names(survey_doc)
'Out of 5 people surveyed, [REDACTED] , [REDACTED] and'
' [REDACTED] like apples. [REDACTED] et [REDACTED]'
' like oranges.'
In this example, replace_person_names() les usages ent_iob. It gives the IOB code of the named entity tag using inside-outside-beginning (IOB) tagging. Here, it can assume a value other than zero, because zero means that no entity tag is set.
Conclusion
spaCy is a powerful and advanced library that is gaining huge popularity for NLP applications due to its speed, ease of use, accuracy, and extensibility. Toutes nos félicitations! You now know:
- What the foundational terms and concepts in NLP are
- How to implement those concepts in spaCy
- How to customize and extend built-in functionalities in spaCy
- How to perform basic statistical analysis on a text
- How to create a pipeline to process unstructured text
- How to parse a sentence and extract meaningful insights from it
[ad_2]