Formation Python
Pourquoi voudriez-vous en savoir plus sur les différentes manières de stocker et d’accéder aux images en Python? Si vous segmentez une poignée d’images par couleur ou si vous détectez des visages l’une après l’autre à l’aide d’OpenCV, vous n’avez pas à vous en préoccuper. Même si vous utilisez la PIL (Python Imaging Library) pour dessiner sur quelques centaines de photos, vous n’avez toujours pas besoin de le faire. Stockage des images sur le disque, comme .png ou .jpg fichiers, est à la fois approprié et approprié.
Cependant, le nombre d'images nécessaires pour une tâche donnée devient de plus en plus grand. Des algorithmes tels que les réseaux de neurones de convolution, également appelés convnets ou CNN, peuvent gérer d’énormes jeux de données d’images et même en tirer des enseignements. Si vous êtes intéressé, vous pouvez en savoir plus sur la façon dont convnets peut être utilisé pour le classement des selfies ou pour l’analyse des sentiments.
ImageNet est une base de données d'images publique bien établie, constituée pour la formation de modèles d'apprentissage sur des tâches telles que la classification, la détection et la segmentation d'objets. plus de 14 millions d'images.
Pensez au temps qu'il faudrait pour les mémoriser pour l'entraînement, par lots, peut-être des centaines ou des milliers de fois. Continuez à lire, et vous serez convaincu que cela prendrait un certain temps, du moins suffisamment de temps pour quitter votre ordinateur et faire beaucoup d'autres choses pendant que vous souhaiteriez travailler chez Google ou NVIDIA.
Dans ce tutoriel, vous apprendrez:
- Stocker des images sur le disque en tant que
.pngdes dossiers - Stockage d'images dans des bases de données Lightning Memory Mapped (LMDB)
- Stockage d'images au format de données hiérarchique (HDF5)
Vous explorerez également les éléments suivants:
- Pourquoi des méthodes de stockage alternatives méritent-elles d'être envisagées?
- Quelles sont les différences de performances lorsque vous lisez et écrivez des images uniques
- Quelles sont les différences de performance lorsque vous lisez et écrivez beaucoup images
- Comment les trois méthodes se comparent en termes d'utilisation du disque
Si aucune des méthodes de stockage ne vous dit rien, ne vous inquiétez pas: pour cet article, vous avez uniquement besoin d’une base relativement solide en Python et d’une compréhension de base des images (qu’elles sont réellement composées de tableaux de nombres multidimensionnels) et mémoire relative, telle que la différence entre 10 Mo et 10 Go.
Commençons!
Installer
Vous aurez besoin d’un jeu de données d’image avec lequel expérimenter, ainsi que de quelques packages Python.
Un jeu de données à jouer
Nous utiliserons l'ensemble de données d'images de l'Institut canadien de recherches avancées, mieux connu sous le nom de CIFAR-10, qui consiste en 60 000 images couleur de 32 x 32 pixels appartenant à différentes classes d'objets, telles que les chiens, les chats et les avions. Relativement, l'ICRA n'est pas un jeu de données très volumineux, mais si nous utilisions le jeu de données TinyImages complet, vous auriez besoin d'environ 400 Go d'espace disque disponible, ce qui constituerait probablement un facteur limitant.
Les crédits pour l'ensemble de données décrit au chapitre 3 de ce rapport technique vont à Alex Krizhevsky, Vinod Nair et Geoffrey Hinton.
Si vous souhaitez suivre les exemples de code présentés dans cet article, vous pouvez télécharger CIFAR-10 ici, en sélectionnant la version Python. Vous allez sacrifier 163 Mo d’espace disque:

Lorsque vous téléchargez et décompressez le dossier, vous découvrez que les fichiers ne sont pas des fichiers image lisibles par l'homme. Ils ont été sérialisés et enregistrés par lots à l’aide de cPickle.
Bien que nous n’envisageons pas cornichon ou cPickle Dans cet article, mis à part l'extraction du jeu de données ICRA, il convient de mentionner que le cornichon Le module a le principal avantage de pouvoir sérialiser n'importe quel objet Python sans aucun code ni transformation supplémentaire de votre part. Cela présente également un inconvénient potentiellement grave, qui est de poser un risque pour la sécurité et de ne pas gérer correctement le traitement de très grandes quantités de données.
Le code suivant désélectionne chacun des cinq fichiers de commandes et charge toutes les images dans un tableau NumPy:
importation numpy comme np
importation cornichon
de pathlib importation Chemin
# Chemin d'accès aux données ICRA décompressées
data_dir = Chemin("data / cifar-10-batchs-py /")
# Fonction Unpickle fournie par les hôtes ICRA
def décoller(fichier):
avec ouvrir(fichier, "rb") comme fo:
dict = cornichon.charge(fo, codage="octets")
revenir dict
images, Étiquettes = [], []
pour lot dans data_dir.glob("data_batch_ *"):
batch_data = décoller(lot)
pour je, flat_im dans énumérer(batch_data[[[[b"Les données"]):
im_channels = []
# Chaque image est aplatie, avec les canaux dans l’ordre R, V, B
pour j dans intervalle(3):
im_channels.ajouter(
flat_im[[[[j * 1024 : (j + 1) * 1024].remodeler((32, 32))
)
# Reconstruire l'image originale
images.ajouter(np.dstack((im_channels)))
# Sauvegarder l'étiquette
Étiquettes.ajouter(batch_data[[[[b"Étiquettes"][[[[je])
impression("Kit de formation CIFAR-10 chargé:")
impression(F"- np.shape (images) np.shape (images)")
impression(F"- np.shape (labels) np.shape (labels)")
Toutes les images sont maintenant en RAM dans le images variable, avec leurs métadonnées correspondantes dans Étiquetteset sont prêts à être manipulés. Ensuite, vous pouvez installer les packages Python que vous utiliserez pour les trois méthodes.
Configuration pour stocker des images sur le disque
Vous devrez configurer votre environnement pour la méthode par défaut d’enregistrement et d’accès à ces images à partir du disque. Cet article supposera que Python 3.x est installé sur votre système et utilisera Oreiller pour la manipulation d'image:
Alternativement, si vous préférez, vous pouvez l'installer en utilisant Anaconda:
$ conda install -c oreiller conda-forge
Remarque: PIL est la version originale de la bibliothèque d'imagerie Python, qui n'est plus maintenue et n'est pas compatible avec Python 3.x. Si vous avez déjà installé PIL, assurez-vous de le désinstaller avant d'installer Oreiller, car ils ne peuvent pas exister ensemble.
Vous êtes maintenant prêt à stocker et à lire des images à partir du disque.
Débuter avec LMDB
LMDB, parfois appelée «base de données Lightning», signifie base de données Lightning Memory-Mapped, car elle est rapide et utilise des fichiers mappés en mémoire. C’est un magasin clé-valeur, pas une base de données relationnelle.
En termes de mise en œuvre, LMDB est une arborescence B +, ce qui signifie qu’il s’agit d’une structure de graphe de type arborescence stockée en mémoire, où chaque élément clé-valeur est un nœud, les nœuds pouvant avoir de nombreux enfants. Les nœuds du même niveau sont liés les uns aux autres pour une traversée rapide.
De manière critique, les composants clés de l'arborescence B + sont définis pour correspondre à la taille de la page du système d'exploitation hôte, optimisant ainsi l'efficacité lors de l'accès à une paire clé-valeur de la base de données. Comme la haute performance de la LMDB repose largement sur ce point particulier, il a été démontré que l’efficacité de la LMDB dépendait du système de fichiers sous-jacent et de son implémentation.
Une autre raison essentielle de l’efficacité de la LMDB est qu’elle est mappée en mémoire. Cela signifie que il renvoie des pointeurs directs aux adresses de mémoire des clés et des valeurs, sans rien copier en mémoire comme le font la plupart des bases de données.
Ceux qui souhaitent se plonger un peu plus dans les détails d'implémentation interne des arbres B + peuvent consulter cet article sur les arbres B +, puis jouer avec cette visualisation de l'insertion de nœud.
Si les arbres B + ne vous intéressent pas, ne vous inquiétez pas. Vous n’avez pas besoin d’en savoir beaucoup sur leur implémentation interne pour utiliser LMDB. Nous allons utiliser la liaison Python pour la bibliothèque LMDB C, qui peut être installée via le pip:
Vous avez également la possibilité d'installer via Anaconda:
$ conda install -c conda-forge python-lmdb
Vérifiez que vous pouvez importer lmdb depuis un shell Python, et vous êtes prêt à partir.
Débuter avec HDF5
HDF5 signifie Hierarchical Data Format, un format de fichier appelé HDF4 ou HDF5. Nous n’avons pas à nous préoccuper de HDF4, HDF5 étant la version actuellement maintenue.
Fait intéressant, HDF tire ses origines du Centre national des applications de superinformatique, en tant que format de données scientifiques compact et portable. Si vous vous demandez s’il est largement utilisé, consultez le texte de présentation de la NASA sur HDF5 dans son projet Earth Data.
Les fichiers HDF se composent de deux types d’objets:
- Ensembles de données
- Groupes
Les jeux de données sont des tableaux multidimensionnels et les groupes sont constitués de jeux de données ou d'autres groupes. Les tableaux multidimensionnels de toute taille et de tout type peuvent être stockés en tant que jeu de données, mais les dimensions et le type doivent être uniformes dans un jeu de données. Chaque jeu de données doit contenir un tableau N-dimensionnel homogène. Cela dit, étant donné que les groupes et les jeux de données peuvent être imbriqués, vous pouvez toujours obtenir l'hétérogénéité dont vous pourriez avoir besoin:
Comme avec les autres bibliothèques, vous pouvez également installer via Anaconda:
$ conda install -c conda-forge python-lmdb
Si tu peux importer h5py depuis un shell Python, tout est configuré correctement.
Stocker une seule image
Maintenant que vous avez une vue d’ensemble des méthodes, passons directement à la comparaison quantitative des tâches de base qui nous intéressent: combien de temps il faut pour lire et écrire des fichiers et combien de mémoire disque sera utilisée. Cela servira également d’introduction de base au fonctionnement des méthodes, avec des exemples de code pour les utiliser.
Quand je parle de «fichiers», je parle généralement de beaucoup d’entre eux. Cependant, il est important de faire la distinction car certaines méthodes peuvent être optimisées pour différentes opérations et quantités de fichiers.
Aux fins d'expérimentation, nous pouvons comparer les performances entre différentes quantités de fichiers, par des facteurs de 10 d'une image unique à 100 000 images. Comme nos cinq lots de CIFAR-10 totalisent 50 000 images, nous pouvons utiliser chaque image deux fois pour obtenir 100 000 images.
Pour préparer les expériences, vous voudrez créer un dossier pour chaque méthode, qui contiendra tous les fichiers de base de données ou images, et enregistrer les chemins d'accès à ces répertoires dans des variables:
de pathlib importation Chemin
disk_dir = Chemin("data / disk /")
lmdb_dir = Chemin("data / lmdb /")
hdf5_dir = Chemin("data / hdf5 /")
Chemin ne crée pas automatiquement les dossiers pour vous sauf si vous le demandez spécifiquement à:
disk_dir.mkdir(Parents=Vrai, exist_ok=Vrai)
lmdb_dir.mkdir(Parents=Vrai, exist_ok=Vrai)
hdf5_dir.mkdir(Parents=Vrai, exist_ok=Vrai)
Vous pouvez maintenant passer aux expériences réelles, avec des exemples de code expliquant comment effectuer des tâches de base avec les trois méthodes différentes. Nous pouvons utiliser le temps module, qui est inclus dans la bibliothèque standard Python, pour aider à chronométrer les expériences.
Bien que l'objectif principal de cet article ne soit pas d'apprendre à connaître les API des différents packages Python, il est utile de comprendre comment les implémenter. Nous allons passer en revue les principes généraux ainsi que tout le code utilisé pour mener les expériences de stockage.
Stockage sur disque
Notre entrée pour cette expérience est une seule image image, actuellement en mémoire sous forme de tableau NumPy. Vous voulez d'abord l'enregistrer sur le disque en tant que .png image et nommez-la à l'aide d'un identifiant d'image unique image_id. Cela peut être fait en utilisant le Oreiller paquet que vous avez installé plus tôt:
de PIL importation Image
importation CSV
def store_single_disk(image, image_id, étiquette):
"" "Stocke une seule image en tant que fichier .png sur le disque.
Paramètres:
---------------
matrice d'images, (32, 32, 3) à stocker
image_id entier unique identifiant pour image
label image label
"" "
Image.fromarray(image).enregistrer(disk_dir / F"image_id.png ")
avec ouvrir(disk_dir / F"image_id.csv ", "wt") comme csvfile:
écrivain = CSV.écrivain(
csvfile, délimiteur="", quotechar="|", citant=CSV.QUOTE_MINIMAL
)
écrivain.écrivain([[[[étiquette])
Cela enregistre l'image. Dans toutes les applications réalistes, vous vous souciez également des métadonnées attachées à l'image, qui dans notre exemple de données est l'étiquette de l'image. Lorsque vous stockez des images sur un disque, vous disposez de plusieurs options pour enregistrer les métadonnées.
Une solution consiste à encoder les étiquettes dans le nom de l'image. Cela a l'avantage de ne pas nécessiter de fichiers supplémentaires.
Cependant, cela présente également le gros inconvénient de vous obliger à traiter tous les fichiers chaque fois que vous manipulez des étiquettes. Le stockage des étiquettes dans un fichier séparé vous permet de jouer avec les étiquettes seules, sans avoir à charger les images. Ci-dessus, j'ai rangé les étiquettes dans un dossier séparé. .csv fichiers pour cette expérience.
Passons maintenant à la même tâche avec LMDB.
Stockage sur LMDB
Premièrement, LMDB est un système de stockage clé-valeur dans lequel chaque entrée est sauvegardée sous forme de tableau d'octets. Dans notre cas, les clés constitueront un identifiant unique pour chaque image et la valeur sera l'image elle-même. Les clés et les valeurs doivent être des chaînesAinsi, l’usage habituel est de sérialiser la valeur en tant que chaîne, puis de la désérialiser lors de la relecture.
Vous pouvez utiliser cornichon pour la sérialisation. Tout objet Python peut être sérialisé, vous pouvez donc également inclure les métadonnées de l'image dans la base de données. Cela vous évite d'avoir à relier les métadonnées aux données d'image lorsque nous chargeons le jeu de données à partir du disque.
Vous pouvez créer une classe Python de base pour l'image et ses métadonnées:
classe CIFAR_Image:
def __init__(soi, image, étiquette):
# Dimensions de l'image pour la reconstruction - pas vraiment nécessaire
# pour cet ensemble de données, mais certains ensembles de données peuvent inclure des images de
# tailles variables
soi.canaux = image.forme[[[[2]
soi.Taille = image.forme[:[:[:[:2]
soi.image = image.tobytes()
soi.étiquette = étiquette
def get_image(soi):
"" "Renvoie l'image sous forme de tableau numpy." ""
image = np.depuis le tampon(soi.image, type=np.uint8)
revenir image.remodeler(*soi.Taille, soi.canaux)
Deuxièmement, LMDB étant mappée en mémoire, les nouvelles bases de données doivent savoir combien de mémoire elles sont censées utiliser. C'est relativement simple dans notre cas, mais cela peut être une douleur énorme dans d'autres cas, que vous verrez plus en profondeur dans une section ultérieure. LMDB appelle cette variable la taille de la carte.
Enfin, les opérations de lecture et d’écriture avec LMDB sont effectuées transactions. Vous pouvez les considérer comme similaires à ceux d'une base de données traditionnelle, consistant en un groupe d'opérations sur la base de données. Cela peut paraître déjà beaucoup plus compliqué que la version sur disque, mais attendez et continuez à lire!
En gardant ces trois points à l’esprit, examinons le code pour enregistrer une seule image sur une LMDB:
importation lmdb
importation cornichon
def store_single_lmdb(image, image_id, étiquette):
"" "Stocke une seule image dans une LMDB.
Paramètres:
---------------
matrice d'images, (32, 32, 3) à stocker
image_id entier unique identifiant pour image
label image label
"" "
taille de la carte = image.nbytes * dix
# Créer un nouvel environnement LMDB
env = lmdb.ouvrir(str(lmdb_dir / F"single_lmdb"), taille de la carte=taille de la carte)
# Commencer une nouvelle transaction d'écriture
avec env.commencer(écrire=Vrai) comme txn:
# Toutes les paires clé-valeur doivent être des chaînes
valeur = CIFAR_Image(image, étiquette)
clé = F"image_id: 08"
txn.mettre(clé.encoder("ascii"), cornichon.décharges(valeur))
env.Fermer()
Remarque: C’est une bonne idée de calculer le nombre exact d’octets que chaque paire clé-valeur utilisera.
Avec un jeu de données d’images de taille variable, ce sera une approximation, mais vous pouvez utiliser sys.getsizeof () pour obtenir une approximation raisonnable. Garde en tête que sys.getsizeof (CIFAR_Image) ne renverra que la taille d'une définition de classe, qui est 1056, ne pas la taille d'un objet instancié.
La fonction ne pourra pas non plus calculer complètement les éléments, les listes ou les objets imbriqués contenant des références à d'autres objets.
Alternativement, vous pouvez utiliser pympler pour vous sauver des calculs en déterminant la taille exacte d'un objet.
Vous êtes maintenant prêt à enregistrer une image au format LMDB. Enfin, regardons la dernière méthode, HDF5.
Stockage avec HDF5
N'oubliez pas qu'un fichier HDF5 peut contenir plusieurs ensembles de données. Dans ce cas plutôt trivial, vous pouvez créer deux jeux de données, un pour l'image et un pour ses métadonnées:
importation h5py
def store_single_hdf5(image, image_id, étiquette):
"" "Stocke une seule image dans un fichier HDF5.
Paramètres:
---------------
matrice d'images, (32, 32, 3) à stocker
image_id entier unique identifiant pour image
label image label
"" "
# Créer un nouveau fichier HDF5
fichier = h5py.Fichier(hdf5_dir / F"image_id.h5 ", "w")
# Créer un jeu de données dans le fichier
ensemble de données = fichier.create_dataset(
"image", np.forme(image), h5py.h5t.STD_U8BE, Les données=image
)
meta_set = fichier.create_dataset(
"méta", np.forme(étiquette), h5py.h5t.STD_U8BE, Les données=étiquette
)
fichier.Fermer()
h5py.h5t.STD_U8BE spécifie le type de données qui sera stocké dans l'ensemble de données, qui dans ce cas est un entier non signé de 8 bits. Vous pouvez voir une liste complète des types de données prédéfinis de HDF ici.
Remarque: Le choix du type de données affectera fortement les exigences en termes d’exécution et de stockage de HDF5; il est donc préférable de choisir votre configuration minimale.
Maintenant que nous avons examiné les trois méthodes de sauvegarde d’une seule image, passons à l’étape suivante.
Expériences pour stocker une seule image
Vous pouvez maintenant mettre les trois fonctions pour enregistrer une seule image dans un dictionnaire, qui pourra être appelé ultérieurement lors des expériences de minutage:
_store_single_funcs = dict(
disque=store_single_disk, lmdb=store_single_lmdb, hdf5=store_single_hdf5
)
Enfin, tout est prêt pour mener l'expérience chronométrée. Essayons d’enregistrer la première image de CIFAR et son étiquette correspondante et de la stocker de trois manières différentes:
de temps importation temps
store_single_timings = dict()
pour méthode dans ("disque", "lmdb", "hdf5"):
t = temps(
"_store_single_funcs[method](image, 0, étiquette) ",
installer="image = images[0]; label = étiquettes[0]",
nombre=1,
globals=globals(),
)
store_single_timings[[[[méthode] = t
impression(F"Méthode: méthode, Utilisation du temps: t")
Remarque: Pendant que vous jouez avec LMDB, vous pouvez voir un MapFullError: mdb_txn_commit: MDB_MAP_FULL: limite de la taille de la cartographie de l'environnement atteinte Erreur. Il est important de noter que la LMDB ne ne pas écraser les valeurs préexistantes, même si elles ont la même clé.
Cela contribue au temps d’écriture rapide, mais cela signifie également que si vous stockez une image plusieurs fois dans le même fichier LMDB, vous utiliserez la taille de la carte. Si vous exécutez une fonction de stockage, veillez à supprimer tout fichier LMDB préexistant.
N'oubliez pas que nous sommes intéressés par l'exécution, affichée ici en quelques secondes, ainsi que par l'utilisation de la mémoire:
| Méthode | Enregistrer l'image unique + méta | Mémoire |
|---|---|---|
| Disque | 1,915 ms | 8 K |
| LMDB | 1,203 ms | 32 K |
| HDF5 | 8,243 ms | 8 K |
Il y a deux plats à emporter ici:
- Toutes les méthodes sont trivialement rapides.
- En termes d'utilisation du disque, LMDB utilise plus.
Il est clair que malgré le léger avantage des performances de la bande LMDB, nous n’avons convaincu personne de ne pas simplement stocker des images sur disque. Après tout, il s’agit d’un format lisible par l’homme que vous pouvez ouvrir et visualiser à partir de n’importe quel navigateur de système de fichiers! Eh bien, il est temps de regarder beaucoup plus d'images…
Stockage de nombreuses images
Vous avez vu le code d'utilisation des différentes méthodes de stockage pour enregistrer une seule image. Nous devons donc maintenant l'ajuster pour enregistrer de nombreuses images, puis exécuter le test chronométré.
Ajustement du code pour plusieurs images
Économie plusieurs images comme .png fichiers est aussi simple que d'appeler store_single_method () plusieurs fois. Mais ce n’est pas vrai pour LMDB ou HDF5, car vous ne voulez pas de fichier de base de données différent pour chaque image. Vous souhaitez plutôt placer toutes les images dans un ou plusieurs fichiers.
Vous devrez modifier légèrement le code et créer trois nouvelles fonctions acceptant plusieurs images. store_many_disk (), store_many_lmdb (), et store_many_hdf5:
store_many_disk(images, Étiquettes):
"" "Stocke un tableau d'images sur le disque
Paramètres:
---------------
images images array, (N, 32, 32, 3) à stocker
étiquettes étiquettes tableau, (N, 1) à stocker
"" "
num_images = len(images)
# Sauvegarder toutes les images une par une
pour je, image dans énumérer(images):
Image.fromarray(image).enregistrer(disk_dir / F"je.png ")
# Sauvegarder toutes les étiquettes dans le fichier csv
avec ouvrir(disk_dir / F"num_images.csv ", "w") comme csvfile:
écrivain = CSV.écrivain(
csvfile, délimiteur="", quotechar="|", citant=CSV.QUOTE_MINIMAL
)
pour étiquette dans Étiquettes:
# Cela correspond généralement à plus d'une valeur par ligne
écrivain.écrivain([[[[étiquette])
def store_many_lmdb(images, Étiquettes):
"" "Stocke un tableau d’images sur LMDB.
Paramètres:
---------------
images images array, (N, 32, 32, 3) à stocker
étiquettes étiquettes tableau, (N, 1) à stocker
"" "
num_images = len(images)
taille de la carte = num_images * images[[[[0].nbytes * dix
# Créer une nouvelle base de données LMDB pour toutes les images
env = lmdb.ouvrir(str(lmdb_dir / F"num_images_lmdb "), taille de la carte=taille de la carte)
# Identique à précédemment - mais écrivons toutes les images en une seule transaction
avec env.commencer(écrire=Vrai) comme txn:
pour je dans intervalle(num_images):
# Toutes les paires clé-valeur doivent être des chaînes
valeur = CIFAR_Image(images[[[[je], Étiquettes[[[[je])
clé = F"i: 08"
txn.mettre(clé.encoder("ascii"), cornichon.décharges(valeur))
env.Fermer()
def store_many_hdf5(images, Étiquettes):
"" "Stocke un tableau d'images en HDF5.
Paramètres:
---------------
images images array, (N, 32, 32, 3) à stocker
étiquettes étiquettes tableau, (N, 1) à stocker
"" "
num_images = len(images)
# Créer un nouveau fichier HDF5
fichier = h5py.Fichier(hdf5_dir / F"num_images_many.h5 ", "w")
# Créer un jeu de données dans le fichier
ensemble de données = fichier.create_dataset(
"images", np.forme(images), h5py.h5t.STD_U8BE, Les données=images
)
meta_set = fichier.create_dataset(
"méta", np.forme(Étiquettes), h5py.h5t.STD_U8BE, Les données=Étiquettes
)
fichier.Fermer()
Afin que vous puissiez stocker plus d'un fichier sur le disque, la méthode des fichiers d'image a été modifiée pour passer en boucle sur chaque image de la liste. Pour LMDB, une boucle est également nécessaire car nous créons un CIFAR_Image objet pour chaque image et ses métadonnées.
Le plus petit ajustement est avec la méthode HDF5. En fait, il n’ya pratiquement aucun ajustement! Les fichiers HFD5 ne sont soumis à aucune limitation de taille, hormis les restrictions externes ou la taille du jeu de données. Toutes les images ont donc été regroupées dans un seul jeu de données, comme auparavant.
Ensuite, vous devrez préparer le jeu de données pour les expériences en augmentant sa taille.
Préparation du jeu de données
Avant de relancer les expériences, doublons d’abord la taille de notre jeu de données afin de pouvoir tester jusqu’à 100 000 images:
coupures = [[[[dix, 100, 1000, 10000, 100000]
# Doublons nos images pour en avoir 100 000
images = np.enchaîner((images, images), axe=0)
Étiquettes = np.enchaîner((Étiquettes, Étiquettes), axe=0)
# Assurez-vous que vous avez réellement 100 000 images et étiquettes
impression(np.forme(images))
impression(np.forme(Étiquettes))
Maintenant qu’il ya assez d’images, c’est le moment de faire l’essai.
Expérience pour stocker de nombreuses images
Comme vous l’avez fait pour la lecture de nombreuses images, vous pouvez créer un dictionnaire contenant toutes les fonctions avec store_many_ et lancez les expériences:
_store_many_funcs = dict(
disque=store_many_disk, lmdb=store_many_lmdb, hdf5=store_many_hdf5
)
de temps importation temps
store_many_timings = "disque": [], "lmdb": [], "hdf5": []
pour couper dans coupures:
pour méthode dans ("disque", "lmdb", "hdf5"):
t = temps(
"_store_many_funcs[method](images_, étiquettes_) ",
installer="images_ = images[:cutoff]; labels_ = labels[:cutoff]",
nombre=1,
globals=globals(),
)
store_many_timings[[[[méthode].ajouter(t)
# Imprimer la méthode, le temps limite et le temps écoulé
impression(F"Méthode: méthode, Utilisation du temps: t")
Si vous suivez et exécutez le code vous-même, vous devrez attendre un instant et attendre que 111 110 images soient stockées trois fois chacune sur votre disque, dans trois formats différents. Vous devrez également dire au revoir à environ 2 Go d’espace disque.
Maintenant pour le moment de vérité! Combien de temps a duré tout ce stockage? Une image vaut mieux que mille mots:


Le premier graphique montre la durée de stockage normale non ajustée, soulignant la différence radicale entre le stockage dans .png fichiers et LMDB ou HDF5.
Le deuxième graphique montre la bûche des temps, soulignant que HDF5 commence plus lentement que LMDB mais, avec de plus grandes quantités d’images, vient légèrement en avance.
Les résultats exacts peuvent varier en fonction de votre machine, C’est pourquoi LMDB et HDF5 méritent d’être examinés. Voici le code qui a généré le graphique ci-dessus:
importation matplotlib.pyplot comme plt
def plot_with_legend(
x_range, y_data, légende_étiquettes, x_label, y_label, Titre, bûche=Faux
):
"" "Affiche un seul tracé avec plusieurs jeux de données et légendes correspondantes.
Paramètres:
--------------
x_range liste de listes contenant x données
y_data liste de listes contenant les valeurs y
legend_labels liste d'étiquettes de légende
x_label étiquette d'axe x
y_label étiquette d'axe y
"" "
plt.style.utilisation("seaborn-whitegrid")
plt.figure(figsize=(dix, 7))
si len(y_data) ! = len(légende_étiquettes):
élever Erreur-type(
"Erreur: le nombre de jeux de données ne correspond pas au nombre d'étiquettes."
)
all_plots = []
pour Les données, étiquette dans Zip *: français(y_data, légende_étiquettes):
si bûche:
temp, = plt.journal(x_range, Les données, étiquette=étiquette)
autre:
temp, = plt.terrain(x_range, Les données, étiquette=étiquette)
all_plots.ajouter(temp)
plt.Titre(Titre)
plt.xlabel(x_label)
plt.ylabel(y_label)
plt.Légende(poignées=all_plots)
plt.spectacle()
# Obtention des données de minutage du magasin à afficher
disk_x = store_many_timings[[[["disque"]
lmdb_x = store_many_timings[[[["lmdb"]
hdf5_x = store_many_timings[[[["hdf5"]
plot_with_legend(
coupures,
[[[[disk_x, lmdb_x, hdf5_x],
[[[["Fichiers PNG", "LMDB", "HDF5"],
"Nombre d'images",
"Des secondes pour stocker",
"Temps de stockage",
bûche=Faux,
)
plot_with_legend(
coupures,
[[[[disk_x, lmdb_x, hdf5_x],
[[[["Fichiers PNG", "LMDB", "HDF5"],
"Nombre d'images",
"Des secondes pour stocker",
"Durée de stockage du journal",
bûche=Vrai,
)
Passons maintenant à la lecture des images.
Lecture d'une seule image
Tout d’abord, considérons le cas de la lecture d’une image unique dans un tableau pour chacune des trois méthodes.
Lecture à partir du disque
Parmi les trois méthodes, la base de données LMDB requiert le plus de lourdeur de travail lors de la lecture de fichiers image sans mémoire, en raison de l'étape de sérialisation. Parcourons ces fonctions qui lisent une seule image pour chacun des trois formats de stockage.
Tout d'abord, lisez une seule image et sa méta à partir d'un .png et .csv fichier:
def read_single_disk(image_id):
"" "Stocke une seule image sur le disque.
Paramètres:
---------------
image_id entier unique identifiant pour image
Résultats:
----------
matrice d'images, (32, 32, 3) à stocker
étiquette associée aux métadonnées, int label
"" "
image = np.tableau(Image.ouvrir(disk_dir / F"image_id.png "))
avec ouvrir(disk_dir / F"image_id.csv ", "r") comme csvfile:
lecteur = CSV.lecteur(
csvfile, délimiteur="", quotechar="|", citant=CSV.QUOTE_MINIMAL
)
étiquette = int(suivant(lecteur)[[[[0])
revenir image, étiquette
Lecture à partir de LMDB
Ensuite, lisez la même image et les mêmes méta depuis une LMDB en ouvrant l’environnement et en lançant une transaction en lecture:
1 def read_single_lmdb(image_id):
2 "" "Stocke une seule image sur LMDB.
3 Paramètres:
4 ---------------
5 image_id entier unique identifiant pour image
6
7 Résultats:
8 ----------
9 matrice d'images, (32, 32, 3) à stocker
dix étiquette associée aux métadonnées, int label
11 "" "
12 # Ouvrez l'environnement LMDB
13 env = lmdb.ouvrir(str(lmdb_dir / F"single_lmdb"), lecture seulement=Vrai)
14
15 # Commencer une nouvelle transaction de lecture
16 avec env.commencer() comme txn:
17 # Encode la clé de la même manière que nous l'avons stockée
18 Les données = txn.obtenir(F"image_id: 08".encoder("ascii"))
19 # Rappelez-vous que c'est un objet CIFAR_Image qui est chargé
20 cifar_image = cornichon.charges(Les données)
21 # Récupérer les bits pertinents
22 image = cifar_image.get_image()
23 étiquette = cifar_image.étiquette
24 env.Fermer()
25
26 revenir image, étiquette
Voici quelques points pour ne pas parler de l'extrait de code ci-dessus:
- Ligne 13: le
readonly = Trueflag spécifie qu'aucune écriture ne sera autorisée sur le fichier LMDB tant que la transaction n'est pas terminée. Dans le langage de base de données, cela équivaut à prendre un verrou en lecture. - Ligne 20: Pour récupérer l'objet CIFAR_Image, vous devez inverser les étapes que nous avons suivies pour le conserver au vinaigre lorsque nous l'écrivions. C'est là que le
get_image ()de l'objet est utile.
Ceci termine la lecture de l'image à partir de LMDB. Enfin, vous voudrez faire la même chose avec HDF5.
Lecture de HDF5
Lire à partir de HDF5 ressemble beaucoup au processus d’écriture. Voici le code pour ouvrir et lire le fichier HDF5 et analyser la même image et la même méta:
def read_single_hdf5(image_id):
"" "Stocke une seule image sur HDF5.
Paramètres:
---------------
image_id entier unique identifiant pour image
Résultats:
----------
matrice d'images, (32, 32, 3) à stocker
étiquette associée aux métadonnées, int label
"" "
# Ouvrir le fichier HDF5
fichier = h5py.Fichier(hdf5_dir / F"image_id.h5 ", "r +")
image = np.tableau(fichier[[[["/image"]).type("uint8")
étiquette = int(np.tableau(fichier[[[["/ meta"]).type("uint8"))
revenir image, étiquette
Notez que vous accédez aux différents jeux de données du fichier en indexant le fichier objet utilisant le nom du jeu de données précédé d'une barre oblique /. Comme auparavant, vous pouvez créer un dictionnaire contenant toutes les fonctions de lecture:
_read_single_funcs = dict(
disque=read_single_disk, lmdb=read_single_lmdb, hdf5=read_single_hdf5
)
Avec ce dictionnaire préparé, vous êtes prêt à exécuter le test.
Expérience de lecture d'une seule image
Vous pouvez vous attendre à ce que l’expérience de lecture d’une seule image produise des résultats quelque peu triviaux, mais voici le code de l’expérience:
de temps importation temps
read_single_timings = dict()
pour méthode dans ("disque", "lmdb", "hdf5"):
t = temps(
"_read_single_funcs[method](0) ",
installer="image = images[0]; label = étiquettes[0]",
nombre=1,
globals=globals(),
)
read_single_timings[[[[méthode] = t
impression(F"Méthode: méthode, Utilisation du temps: t")
Voici les résultats de l'expérience de lecture d'une seule image:
| Méthode | Lire une seule image + méta |
|---|---|
| Disque | 1,61970 ms |
| LMDB | 4,52063 ms |
| HDF5 | 1,98036 ms |
C’est un peu plus rapide de lire le .png et .csv fichiers directement à partir du disque, mais les trois méthodes fonctionnent de manière triviale rapidement. Les expériences que nous ferons ensuite sont beaucoup plus intéressantes.
Lecture de nombreuses images
Vous pouvez maintenant ajuster le code pour lire plusieurs images à la fois. Il s’agit probablement de l’action que vous effectuerez le plus souvent. Les performances d’exécution sont donc essentielles.
Ajustement du code pour plusieurs images
En étendant les fonctions ci-dessus, vous pouvez créer des fonctions avec read_many_, qui peut être utilisé pour les prochaines expériences. Comme auparavant, il est intéressant de comparer les performances lors de la lecture de différentes quantités d'images, qui sont répétées dans le code ci-dessous à titre de référence:
def read_many_disk(num_images):
"" "Lit l'image du disque.
Paramètres:
---------------
num_images nombre d'images à lire
Résultats:
----------
images images array, (N, 32, 32, 3) à stocker
étiquettes associées aux métadonnées, int label (N, 1)
"" "
images, Étiquettes = [], []
# Boucle sur tous les identifiants et lit chaque image une par une
pour image_id dans intervalle(num_images):
images.ajouter(np.tableau(Image.ouvrir(disk_dir / F"image_id.png ")))
avec ouvrir(disk_dir / F"num_images.csv ", "r") comme csvfile:
lecteur = CSV.lecteur(
csvfile, délimiteur="", quotechar="|", citant=CSV.QUOTE_MINIMAL
)
pour rangée dans lecteur:
Étiquettes.ajouter(int(rangée[[[[0]))
revenir images, Étiquettes
def read_many_lmdb(num_images):
"" "Lit l'image depuis la LMDB.
Paramètres:
---------------
num_images nombre d'images à lire
Résultats:
----------
images images array, (N, 32, 32, 3) à stocker
étiquettes associées aux métadonnées, int label (N, 1)
"" "
images, Étiquettes = [], []
env = lmdb.ouvrir(str(lmdb_dir / F"num_images_lmdb "), lecture seulement=Vrai)
# Commencer une nouvelle transaction de lecture
avec env.commencer() comme txn:
# Lire toutes les images en une seule transaction, avec un verrou
# Nous pourrions diviser cela en plusieurs transactions si nécessaire
pour image_id dans intervalle(num_images):
Les données = txn.obtenir(F"image_id: 08".encoder("ascii"))
# Rappelez-vous qu'il s'agit d'un objet CIFAR_Image
# qui est stocké comme valeur
cifar_image = cornichon.charges(Les données)
# Récupérer les bits pertinents
images.ajouter(cifar_image.get_image())
Étiquettes.ajouter(cifar_image.étiquette)
env.Fermer()
revenir images, Étiquettes
def read_many_hdf5(num_images):
"" "Lit l’image de HDF5.
Paramètres:
---------------
num_images nombre d'images à lire
Résultats:
----------
images images array, (N, 32, 32, 3) à stocker
étiquettes associées aux métadonnées, int label (N, 1)
"" "
images, Étiquettes = [], []
# Ouvrir le fichier HDF5
fichier = h5py.Fichier(hdf5_dir / F"num_images_many.h5 ", "r +")
images = np.tableau(fichier[[[["/images"]).type("uint8")
Étiquettes = np.tableau(fichier[[[["/ meta"]).type("uint8")
revenir images, Étiquettes
_read_many_funcs = dict(
disque=read_many_disk, lmdb=read_many_lmdb, hdf5=read_many_hdf5
)
Avec les fonctions de lecture stockées dans un dictionnaire comme avec les fonctions d’écriture, vous êtes tous prêts pour l’expérimentation.
Expérience de lecture de nombreuses images
Vous pouvez maintenant lancer l'expérience pour lire de nombreuses images:
de temps importation temps
read_many_timings = "disque": [], "lmdb": [], "hdf5": []
pour couper dans coupures:
pour méthode dans ("disque", "lmdb", "hdf5"):
t = temps(
"_read_many_funcs[method](num_images) ",
installer="num_images = cutoff",
nombre=1,
globals=globals(),
)
read_many_timings[[[[méthode].ajouter(t)
# Imprimer la méthode, le temps limite et le temps écoulé
impression(F"Méthode: méthode, N ° images: couper, Utilisation du temps: t")
Comme nous l'avons fait précédemment, vous pouvez représenter graphiquement les résultats du test de lecture:


Le graphique du haut montre les temps de lecture normaux non ajustés, montrant la différence radicale entre la lecture de .png fichiers et LMDB ou HDF5.
En revanche, le graphique en bas montre la bûche des minuteries, en soulignant les différences relatives avec moins d'images. Notamment, nous pouvons voir comment HDF5 commence derrière, mais, avec plus d'images, devient systématiquement plus rapide que LMDB avec une petite marge.
En utilisant la même fonction de traçage que pour les timings d’écriture, on obtient:
disk_x_r = read_many_timings[[[["disque"]
lmdb_x_r = read_many_timings[[[["lmdb"]
hdf5_x_r = read_many_timings[[[["hdf5"]
plot_with_legend(
coupures,
[[[[disk_x_r, lmdb_x_r, hdf5_x_r],
[[[["Fichiers PNG", "LMDB", "HDF5"],
"Nombre d'images",
"Secondes à lire",
"Temps de lecture",
bûche=Faux,
)
plot_with_legend(
coupures,
[[[[disk_x_r, lmdb_x_r, hdf5_x_r],
[[[["Fichiers PNG", "LMDB", "HDF5"],
"Nombre d'images",
"Secondes à lire",
"Enregistrer le temps de lecture",
bûche=Vrai,
)
En pratique, le temps d'écriture est souvent moins critique que le temps de lecture. Imaginez que vous entraîniez un réseau de neurones profond sur des images, et que seulement la moitié de votre jeu de données d'image complet entre en même temps dans la RAM. Chaque époque de formation d’un réseau nécessite l’ensemble du jeu de données, et le modèle a besoin de quelques centaines d’époques pour converger. Vous lirez essentiellement la moitié du jeu de données en mémoire à chaque époque.
Les gens font plusieurs astuces, telles que la formation de pseudo-époques pour l’améliorer un peu, mais vous avez l’idée.
Maintenant, regardez à nouveau le graphique lu ci-dessus. La différence entre un temps de lecture de 40 secondes et de 4 secondes correspond soudainement à la différence entre six heures d'attente pour que votre modèle s'entraîne ou quarante minutes!
Si nous visualisons les temps de lecture et d'écriture sur le même graphique, nous avons les éléments suivants:
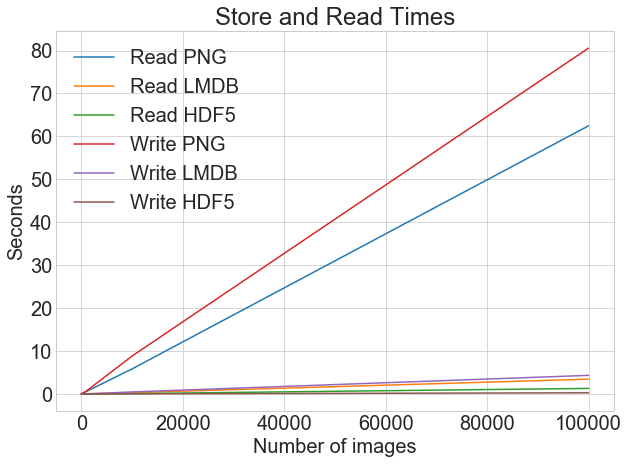
Vous pouvez tracer toutes les durées de lecture et d'écriture sur un même graphique en utilisant la même fonction de traçage:
plot_with_legend(
coupures,
[[[[disk_x_r, lmdb_x_r, hdf5_x_r, disk_x, lmdb_x, hdf5_x],
[[[[
"Lire PNG",
"Lire LMDB",
"Lire HDF5",
"Ecrire PNG",
"Écrire LMDB",
"Ecrire HDF5",
],
"Nombre d'images",
"Secondes",
"Magasin de journaux et temps de lecture",
bûche=Faux,
)
Lorsque vous stockez des images au format .png fichiers, il y a une grande différence entre les temps d'écriture et de lecture. Cependant, avec LMDB et HDF5, la différence est beaucoup moins marquée. Globalement, même si le temps de lecture est plus critique que le temps d'écriture, un argument de poids plaide en faveur du stockage d'images à l'aide de LMDB ou HDF5.
Maintenant que vous avez constaté les avantages de LMDB et de HDF5 en termes de performances, examinons une autre mesure cruciale: l’utilisation du disque.
Considérer l'utilisation du disque
La vitesse n'est pas la seule mesure de performance qui puisse vous intéresser. Nous avons déjà affaire à de très grands ensembles de données. L'espace disque est donc une préoccupation très valable et pertinente.
Supposons que vous ayez un jeu de données d'image de 3 To. Vraisemblablement, vous les avez déjà sur le disque quelque part, contrairement à notre exemple ICRA, donc en utilisant une autre méthode de stockage, vous en effectuez une copie, qui doit également être stockée. Cela vous apportera d’énormes avantages en termes de performances lorsque vous utiliserez les images, mais vous devrez vous assurer de disposer de suffisamment d’espace disque.
Combien d'espace disque les différentes méthodes de stockage utilisent-elles? Voici l’espace disque utilisé pour chaque méthode pour chaque quantité d’images:

J'ai utilisé le Linux du -h -c nom_dossier / * commande pour calculer l'utilisation du disque sur mon système. Les chiffres ayant été arrondis, cette méthode est approximative, mais voici la comparaison générale:
# Mémoire utilisée en ko
disk_mem = [[[[24, 204, 2004, 20032, 200296]
lmdb_mem = [[[[60, 420, 4000, 39000, 393000]
hdf5_mem = [[[[36, 304, 2900, 29000, 293000]
X = [[[[disk_mem, lmdb_mem, hdf5_mem]
Indiana = np.s'organiser(3)
largeur = 0,35
plt.sous-parcelles(figsize=(8, dix))
parcelles = [[[[plt.bar(Indiana, [[[[rangée[[[[0] pour rangée dans X], largeur)]
pour je dans intervalle(1, len(coupures)):
parcelles.ajouter(
plt.bar(
Indiana, [[[[rangée[[[[je] pour rangée dans X], largeur, bas=[[[[rangée[[[[je - 1] pour rangée dans X]
)
)
plt.ylabel("Mémoire en ko")
plt.Titre("Mémoire disque utilisée par méthode")
plt.xticks(Indiana, ("PNG", "LMDB", "HDF5"))
plt.yticks(np.s'organiser(0, 400000, 100000))
plt.Légende(
[[[[terrain[[[[0] pour terrain dans parcelles], ("dix", "100", "1000", "10 000", "100 000")
)
plt.spectacle()
Both HDF5 and LMDB take up more disk space than if you store using normal .png images. It’s important to note that both LMDB and HDF5 disk usage and performance depend highly on various factors, including operating system and, more critically, the size of the data you store.
LMDB gains its efficiency from caching and taking advantage of OS page sizes. You don’t need to understand its inner workings, but note that with larger images, you will end up with significantly more disk usage with LMDB, because images won’t fit on LMDB’s leaf pages, the regular storage location in the tree, and instead you will have many overflow pages. The LMDB bar in the chart above will shoot off the chart.
Our 32x32x3 pixel images are relatively small compared to the average images you may use, and they allow for optimal LMDB performance.
While we won’t explore it here experimentally, in my own experience with images of 256x256x3 or 512x512x3 pixels, HDF5 is usually slightly more efficient in terms of disk usage than LMDB. This is a good transition into the final section, a qualitative discussion of the differences between the methods.
Discussion
There are other distinguishing features of LMDB and HDF5 that are worth knowing about, and it’s also important to briefly discuss some of the criticisms of both methods. Several links are included along with the discussion if you want to learn more.
Parallel Access
A key comparison that we didn’t test in the experiments above is concurrent reads and writes. Often, with such large datasets, you may want to speed up your operation through parallelization.
In the majority of cases, you won’t be interested in reading parts of the same image at the same time, but you volonté want to read multiple images at once. With this definition of concurrency, storing to disk as .png files actually allows for complete concurrency. Nothing prevents you from reading several images at once from different threads, or writing multiple files at once, as long as the image names are different.
How about LMDB? There can be multiple readers on an LMDB environment at a time, but only one writer, and writers do not block readers. You can read more about that at the LMDB technology website.
Multiple applications can access the same LMDB database at the same time, and multiple threads from the same process can also concurrently access the LMDB for reads. This allows for even quicker read times: if you divided all of CIFAR into ten sets, then you could set up ten processes to each read in one set, and it would divide the loading time by ten.
HDF5 also offers parallel I/O, allowing concurrent reads and writes. However, in implementation, a write lock is held, and access is sequential, unless you have a parallel file system.
There are two main options if you are working on such a system, which are discussed more in depth in this article by the HDF Group on parallel IO. It can get quite complicated, and the simplest option is to intelligently split your dataset into multiple HDF5 files, such that each process can deal with one .h5 file independently of the others.
Documentation
If you Google lmdb, at least in the United Kingdom, the third search result is IMDb, the Internet Movie Database. That’s not what you were looking for!
Actually, there is one main source of documentation for the Python binding of LMDB, which is hosted on Read the Docs LMDB. While the Python package hasn’t even reached version > 0.94, it est quite widely used and is considered stable.
As for the LMDB technology itself, there is more detailed documentation at the LMDB technology website, which can feel a bit like learning calculus in second grade, unless you start from their Getting Started page.
For HDF5, there is very clear documentation at the h5py docs site, as well as a helpful blog post by Christopher Lovell, which is an excellent overview of how to use the h5py paquet. The O’Reilly book, Python and HDF5 also is a good way to get started.
While not as documented as perhaps a beginner would appreciate, both LMDB and HDF5 have large user communities, so a deeper Google search usually yields helpful results.
A More Critical Look at Implementation
There is no utopia in storage systems, and both LMDB and HDF5 have their share of pitfalls.
A key point to understand about LMDB is that new data is written without overwriting or moving existing data. This is a design decision that allows for the extremely quick reads you witnessed in our experiments, and also guarantees data integrity and reliability without the additional need of keeping transaction logs.
Remember, however, that you needed to define the map_size parameter for memory allocation avant writing to a new database? This is where LMDB can be a hassle. Suppose you have created an LMDB database, and everything is wonderful. You’ve waited patiently for your enormous dataset to be packed into a LMDB.
Then, later down the line, you remember that you need to add new data. Even with the buffer you specified on your map_size, you may easily expect to see the lmdb.MapFullError Erreur. Unless you want to re-write your entire database, with the updated map_size, you’ll have to store that new data in a separate LMDB file. Even though one transaction can span multiple LMDB files, having multiple files can still be a pain.
Additionally, some systems have restrictions on how much memory may be claimed at once. In my own experience, working with high-performance computing (HPC) systems, this has proved extremely frustrating, and has often made me prefer HDF5 over LMDB.
With both LMDB and HDF5, only the requested item is read into memory at once. With LMDB, key-unit pairs are read into memory one by one, while with HDF5, the ensemble de données object can be accessed like a Python array, with indexing ensemble de données[i], ranges, ensemble de données[i:j] and other splicing ensemble de données[i:j:interval].
Because of the way the systems are optimized, and depending on your operating system, the order in which you access items can impact performance.
In my experience, it’s generally true that for LMDB, you may get better performance when accessing items sequentially by key (key-value pairs being kept in memory ordered alphanumerically by key), and that for HDF5, accessing large ranges will perform better than reading every element of the dataset one by one using the following:
# Slightly slower
pour je dans intervalle(len(ensemble de données)):
# Read the ith value in the dataset, one at a time
do_something_with(ensemble de données[[[[je])
# This is better
Les données = ensemble de données[:]
pour ré dans Les données:
do_something_with(ré)
If you are considering a choice of file storage format to write your software around, it would be remiss not to mention Moving away from HDF5 by Cyrille Rossant on the pitfalls of HDF5, and Konrad Hinsen’s response On HDF5 and the future of data management, which shows how some of the pitfalls can be avoided in his own use cases with many smaller datasets rather than a few enormous ones. Note that a relatively smaller dataset is still several GB in size.
Integration With Other Libraries
If you’re dealing with really large datasets, it’s highly likely that you’ll be doing something significant with them. It’s worthwhile to consider deep learning libraries and what kind of integration there is with LMDB and HDF5.
First of all, all libraries support reading images from disk as .png files, as long as you convert them into NumPy arrays of the expected format. This holds true for all the methods, and we have already seen above that it is relatively straightforward to read in images as arrays.
Here are several of the most popular deep learning libraries and their LMDB and HDF5 integration:
-
Caffe has a stable, well-supported LMDB integration, and it handles the reading step transparently. The LMDB layer can also easily be replaced with a HDF5 database.
-
Keras uses the HDF5 format to save and restore models. This implies that TensorFlow can as well.
-
TensorFlow has a built-in class
LMDBDatasetthat provides an interface for reading in input data from an LMDB file and can produce iterators and tensors in batches. TensorFlow does ne pas have a built-in class for HDF5, but one can be written that inherits from theDatasetclasse. I personally use a custom class altogether that is designed for optimal read access based on the way I structure my HDF5 files. -
Theano does not natively support any particular file format or database, but as previously stated, can use anything as long as it is read in as an N-dimensional array.
While far from comprehensive, this hopefully gives you a feel for the LMDB/HDF5 integration by some key deep learning libraries.
A Few Personal Insights on Storing Images in Python
In my own daily work analyzing terabytes of medical images, I use both LMDB and HDF5, and have learned that, with any storage method, forethought is critical.
Often, models need to be trained using k-fold cross validation, which involves splitting the entire dataset into k-sets (k typically being 10), and k models being trained, each with a different k-set used as test set. This ensures that the model is not overfitting the dataset, or, in other words, unable to make good predictions on unseen data.
A standard way to craft a k-set is to put an equal representation of each type of data represented in the dataset in each k-set. Thus, saving each k-set into a separate HDF5 dataset maximizes efficiency. Sometimes, a single k-set cannot be loaded into memory at once, so even the ordering of data within a dataset requires some forethought.
With LMDB, I similarly am careful to plan ahead before creating the database(s). There are a few good questions worth asking before you save images:
- How can I save the images such that most of the reads will be sequential?
- What are good keys?
- How can I calculate a good
map_size, anticipating potential future changes in the dataset? - How large can a single transaction be, and how should transactions be subdivided?
Regardless of the storage method, when you’re dealing with large image datasets, a little planning goes a long way.
Conclusion
You’ve made it to the end! You’ve now had a bird’s eye view of a large topic.
In this article, you’ve been introduced to three ways of storing and accessing lots of images in Python, and perhaps had a chance to play with some of them. All the code for this article is in a Jupyter notebook here or Python script here. Run at your own risk, as a few GB of your disk space will be overtaken by little square images of cars, boats, and so on.
You’ve seen evidence of how various storage methods can drastically affect read and write time, as well as a few pros and cons of the three methods considered in this article. While storing images as .png files may be the most intuitive, there are large performance benefits to considering methods such as HDF5 or LMDB.
Feel free to discuss in the comment section the excellent storage methods not covered in this article, such as LevelDB, Feather, TileDB, Badger, BoltDB, or anything else. There is no perfect storage method, and the best method depends on your specific dataset and use cases.
Lectures complémentaires
Here are some references related to the three methods covered in this article:
You may also appreciate “An analysis of image storage systems for scalable training of deep neural networks” by Lim, Young, and Patton. That paper covers experiments similar to the ones in this article, but on a much larger scale, considering cold and warm cache as well as other factors.
[ad_2]