trouver un expert Python
- Episode # 75 Les jeux Pythonic sur CheckIO
- L'hébergement WordPress le mieux géré (découvrez pourquoi)
- Épisode 58 Créez de meilleurs programmes Python avec accès simultané, bibliothèques et patterns
- Épisode n ° 22 Internals de CPython et apprendre Python avec pythontutor.com
- Objectifs et sujets des podcasts – Tests en Python
Le threading Python vous permet d’exécuter simultanément différentes parties de votre programme et peut simplifier votre conception. Si vous avez de l'expérience en Python et souhaitez accélérer votre programme à l'aide de threads, ce didacticiel est pour vous!
Dans cet article, vous apprendrez:
- Quels sont les fils
- Comment créer des threads et attendre qu'ils finissent
- Comment utiliser un
ThreadPoolExecutor - Comment éviter les conditions de course
- Comment utiliser les outils communs que Python
filetagefournit
Cet article suppose que vous maîtrisez les bases de Python et que vous utilisez au moins la version 3.6 pour exécuter les exemples. Si vous avez besoin d'un rappel, vous pouvez commencer avec les parcours de formation Python et vous mettre à niveau.
Si vous n'êtes pas sûr de vouloir utiliser Python filetage, asyncio, ou multitraitement, alors vous pouvez vérifier Accélérez votre programme Python avec la concurrence.
Toutes les sources utilisées dans ce tutoriel sont disponibles dans la Vrai python Repo GitHub.
Bonus gratuit: 5 réflexions sur la maîtrise Python, un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour améliorer vos compétences en Python.
Fais le quiz: Testez vos connaissances avec notre questionnaire interactif «Python Threading». À la fin, vous recevrez un score qui vous permettra de suivre vos progrès d'apprentissage au fil du temps:
Fais le quiz "
Qu'est-ce qu'un fil?
Un thread est un flux d'exécution distinct. Cela signifie que votre programme comportera deux choses à la fois. Mais pour la plupart des implémentations de Python 3, les différents threads ne s'exécutent pas en même temps: ils apparaissent simplement.
Il est tentant de penser que l’enfilage a deux (ou plus) processeurs différents en cours d’exécution sur votre programme, chacun effectuant une tâche indépendante en même temps. C’est presque vrai. Les threads peuvent s'exécuter sur différents processeurs, mais ils ne fonctionneront que l'un après l'autre.
L'exécution simultanée de plusieurs tâches nécessite une implémentation non standard de Python, l'écriture de votre code dans un langage différent ou l'utilisation de multitraitement qui vient avec des frais généraux supplémentaires.
En raison de la manière dont l'implémentation Python de CPython fonctionne, le threading peut ne pas accélérer toutes les tâches. Ceci est dû aux interactions avec le GIL qui limitent essentiellement l'exécution d'un thread Python à la fois.
Les tâches qui passent beaucoup de temps à attendre des événements externes sont généralement de bons candidats pour les threads. Les problèmes nécessitant des calculs lourds de la part du processeur et nécessitant peu de temps d'attente pour des événements externes risquent de ne pas s'exécuter plus rapidement.
Cela est vrai pour le code écrit en Python et s'exécutant sur l'implémentation CPython standard. Si vos discussions sont écrites en C, elles ont la possibilité de publier GIL et de s'exécuter simultanément. Si vous utilisez une autre implémentation Python, consultez la documentation pour voir comment elle traite les threads.
Si vous exécutez une implémentation Python standard, écrivez uniquement en Python et avez un problème lié au processeur, vous devez vérifier la multitraitement module à la place.
L'architecture de votre programme en vue de l'utilisation du threading peut également permettre de gagner en clarté dans la conception. La plupart des exemples que vous apprendrez dans ce didacticiel ne vont pas nécessairement s’exécuter plus rapidement car ils utilisent des threads. L'utilisation de filets à l'intérieur contribue à rendre la conception plus propre et plus facile à raisonner.
Alors, cessons de parler de thread et commençons à l’utiliser!
Commencer un fil
Maintenant que vous avez une idée de ce qu’est un fil, apprenons à en créer un. La bibliothèque standard Python fournit filetage, qui contient la plupart des primitives que vous verrez dans cet article. Fil, dans ce module, encapsule bien les threads, fournissant une interface propre pour travailler avec eux.
Pour démarrer un fil séparé, vous créez un Fil par exemple, puis dites-lui de .début():
1 importation enregistrement
2 importation filetage
3 importation temps
4
5 def thread_function(prénom):
6 enregistrement.Info("Fil % s: à partir de ", prénom)
7 temps.dormir(2)
8 enregistrement.Info("Fil % s: finition ", prénom)
9
dix si __prénom__ == "__principale__":
11 format = "% (asctime) s: %(messages"
12 enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
13 datefmt="% H:% M:% S")
14
15 enregistrement.Info("Principal: avant de créer un fil")
16 X = filetage.Fil(cible=thread_function, args=(1,))
17 enregistrement.Info("Principal: avant de lancer le fil")
18 X.début()
19 enregistrement.Info("Main: attendez que le fil se termine")
20 # x.join ()
21 enregistrement.Info("Main: tout est fait")
Si vous regardez les instructions de journalisation, vous pouvez voir que le principale section crée et démarre le fil de discussion:
X = filetage.Fil(cible=thread_function, args=(1,))
X.début()
Lorsque vous créez un Fil, vous lui transmettez une fonction et une liste contenant les arguments de cette fonction. Dans ce cas, vous dites au Fil courir thread_function () et le transmettre 1 comme argument.
Pour cet article, vous utiliserez des entiers séquentiels comme noms de vos threads. Il y a threading.get_ident (), qui renvoie un nom unique pour chaque thread, mais ceux-ci ne sont généralement ni courts ni faciles à lire.
thread_function () lui-même ne fait pas beaucoup. Il enregistre simplement quelques messages avec un le sommeil de temps() entre eux.
Lorsque vous exécutez ce programme tel quel (avec la ligne vingt commentée), le résultat ressemblera à ceci:
$ ./single_thread.py
Principal: avant de créer un fil
Main: avant d'exécuter le fil
Fil 1: à partir
Main: attendez que le fil se termine
Main: tout est fait
Fil 1: finition
Vous remarquerez que le Fil fini après le Principale section de votre code a fait. Vous reviendrez sur la raison pour laquelle vous parlerez de la mystérieuse ligne 20 dans la section suivante.
Fils de démon
En informatique, un démon est un processus qui s’exécute en arrière-plan.
Python filetage a un sens plus spécifique pour démon. UNE démon thread s’arrêtera immédiatement à la sortie du programme. Une façon de réfléchir à ces définitions est de considérer la démon Enfilez un fil qui tourne en arrière-plan sans vous soucier de le fermer.
Si un programme est en cours d'exécution Les fils qui ne sont pas démons, le programme attendra que ces threads soient terminés avant de se terminer. Les fils cette sont les démons, cependant, sont simplement tués où qu'ils soient lorsque le programme se termine.
Examinons de plus près le résultat de votre programme ci-dessus. Les deux dernières lignes sont intéressantes. Lorsque vous exécutez le programme, vous remarquerez qu’il y a une pause (d’environ 2 secondes) après __principale__ a imprimé son terminé message et avant que le fil soit fini.
Cette pause signifie que Python attend la fin du thread non démon. Lorsque votre programme Python se termine, une partie du processus d'arrêt consiste à nettoyer la routine de threading.
Si vous regardez la source de Python filetage, vous verrez ça threading._shutdown () parcourt tous les fils et appels en cours .joindre() sur tout ce qui n'a pas le démon ensemble de drapeaux.
Votre programme attend donc de quitter car le thread lui-même attend dans un sommeil. Dès que le message est terminé et imprimé, .joindre() reviendra et le programme peut quitter.
Ce comportement est souvent ce que vous voulez, mais d’autres options nous sont offertes. Répétons d’abord le programme avec un démon fil. Vous faites cela en changeant la façon dont vous construisez le Fil, en ajoutant le démon = vrai drapeau:
X = filetage.Fil(cible=thread_function, args=(1,), démon=Vrai)
Lorsque vous exécutez le programme maintenant, vous devriez voir cette sortie:
$ ./daemon_thread.py
Principal: avant de créer un fil
Main: avant d'exécuter le fil
Fil 1: à partir
Main: attendez que le fil se termine
Main: tout est fait
La différence ici est que la dernière ligne de la sortie est manquante. thread_function () n'a pas eu l'occasion de terminer. C'était un démon fil, alors quand __principale__ atteint la fin de son code et le programme voulait terminer, le démon a été tué.
joindre() un fil
Les threads Daemon sont pratiques, mais qu'en est-il lorsque vous voulez attendre qu'un thread s'arrête? Qu'en est-il lorsque vous voulez faire cela et ne pas quitter votre programme? Revenons maintenant à votre programme initial et examinons la ligne vingt commentée:
Pour dire à un thread d'attendre qu'un autre thread se termine, vous appelez .joindre(). Si vous supprimez la mise en commentaire de cette ligne, le thread principal s'interrompt et attend le thread. X pour terminer la course.
Avez-vous testé cela sur le code avec le thread démon ou le thread normal? Il s’avère que ce n’est pas grave. Si vous .joindre() un fil, cette déclaration attendra que l’un ou l’autre type de fil soit terminé.
Travailler avec plusieurs threads
L’exemple de code jusqu’à présent ne fonctionnait que sur deux threads: le thread principal et l’autre que vous avez commencé avec le threading.Thread objet.
Il est fréquent que vous souhaitiez démarrer un certain nombre de threads et qu’ils effectuent un travail intéressant. Commençons par examiner le moyen le plus difficile de le faire, puis vous passerez à une méthode plus simple.
Le moyen le plus difficile de démarrer plusieurs threads est celui que vous connaissez déjà:
importation enregistrement
importation filetage
importation temps
def thread_function(prénom):
enregistrement.Info("Fil % s: à partir de ", prénom)
temps.dormir(2)
enregistrement.Info("Fil % s: finition ", prénom)
si __prénom__ == "__principale__":
format = "% (asctime) s: %(messages"
enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
datefmt="% H:% M:% S")
les fils = liste()
pour indice dans intervalle(3):
enregistrement.Info("Main: créer et démarrer le fil %ré. ", indice)
X = filetage.Fil(cible=thread_function, args=(indice,))
les fils.ajouter(X)
X.début()
pour indice, fil dans énumérer(les fils):
enregistrement.Info("Principal: avant de rejoindre le fil %ré. ", indice)
fil.joindre()
enregistrement.Info("Main: fil %ré terminé", indice)
Ce code utilise le même mécanisme que vous avez vu ci-dessus pour démarrer un thread, créer un Fil objet, puis appelez .début(). Le programme conserve une liste de Fil objets afin qu'il puisse ensuite les attendre plus tard en utilisant .joindre().
L'exécution de ce code plusieurs fois donnera probablement des résultats intéressants. Voici un exemple de sortie de ma machine:
$ ./multiple_threads.py
Main: créer et démarrer le thread 0.
Fil 0: à partir
Principal: créez et démarrez le fil 1.
Fil 1: à partir
Principal: créez et démarrez le fil 2.
Fil 2: à partir
Principal: avant de rejoindre le fil 0.
Fil 2: finition
Fil 1: finition
Fil 0: finition
Main: fil 0 fait
Principal: avant de rejoindre le fil 1.
Main: fil 1 fait
Principal: avant de rejoindre le fil 2.
Main: fil 2 fait
Si vous parcourez soigneusement la sortie, vous verrez que les trois threads démarrent dans l’ordre que vous attendez, mais dans ce cas, ils se terminent dans l’ordre inverse! Les exécutions multiples produiront différents ordres. Cherchez le Fil x: finition message pour vous dire quand chaque fil est fait.
L'ordre dans lequel les threads sont exécutés est déterminé par le système d'exploitation et peut être assez difficile à prédire. Elle peut (et va probablement varier) d'une exécution à l'autre. Vous devez donc en être conscient lorsque vous concevez des algorithmes utilisant le threading.
Heureusement, Python vous donne plusieurs primitives que vous examinerez plus tard pour vous aider à coordonner les threads et à les faire fonctionner ensemble. Avant cela, voyons comment faciliter la gestion d’un groupe de threads.
Utilisant un ThreadPoolExecutor
Il existe un moyen plus facile de démarrer un groupe de threads que celui que vous avez vu ci-dessus. C'est ce qu'on appelle un ThreadPoolExecutoret fait partie de la bibliothèque standard de concurrent.futures (à partir de Python 3.2).
Le moyen le plus simple de le créer est en tant que gestionnaire de contexte, en utilisant le avec déclaration pour gérer la création et la destruction de la piscine.
Ici se trouve le __principale__ à partir du dernier exemple réécrit pour utiliser un ThreadPoolExecutor:
importation concurrent.futures
# [rest of code]
si __prénom__ == "__principale__":
format = "% (asctime) s: %(messages"
enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
datefmt="% H:% M:% S")
avec concurrent.avenir.ThreadPoolExecutor(max_workers=3) comme exécuteur:
exécuteur.carte(thread_function, intervalle(3))
Le code crée un ThreadPoolExecutor en tant que gestionnaire de contexte, en lui indiquant le nombre de threads de travail qu'il souhaite dans le pool. Il utilise ensuite .carte() pour parcourir un itératif de choses, dans votre cas gamme (3), en passant chacun à un thread de la piscine.
La fin de avec bloquer provoque le ThreadPoolExecutor faire un .joindre() sur chacun des threads de la piscine. Il est fortement recommandé que vous utilisez ThreadPoolExecutor en tant que gestionnaire de contexte quand vous le pouvez pour ne jamais oublier de .joindre() les fils.
Remarque: Utilisant un ThreadPoolExecutor peut causer des erreurs déroutantes.
Par exemple, si vous appelez une fonction qui ne prend aucun paramètre mais que vous lui transmettez des paramètres dans .carte(), le fil va lancer une exception.
Malheureusement, ThreadPoolExecutor masquera cette exception et (dans le cas ci-dessus), le programme se terminera sans sortie. Cela peut être assez déroutant de déboguer au début.
L'exécution de votre exemple de code corrigé produira une sortie ressemblant à ceci:
$ ./executor.py
Fil 0: à partir
Fil 1: à partir
Fil 2: à partir
Fil 1: finition
Fil 0: finition
Fil 2: finition
Encore une fois, remarquez comment Fil 1 fini avant Fil 0. La planification des threads est effectuée par le système d’exploitation et ne suit pas un plan facile à comprendre.
Conditions de course
Avant de passer à d'autres fonctionnalités cachées dans Python filetage, parlons maintenant de l’un des problèmes les plus difficiles que vous rencontrerez lors de l’écriture de programmes threadés: les conditions de concurrence.
Une fois que vous avez vu en quoi consiste une situation de concurrence critique, vous passerez aux primitives fournies par la bibliothèque standard pour éviter que des conditions de concurrence ne se produisent.
Des conditions de concurrence peuvent se produire lorsque deux ou plusieurs threads accèdent à une donnée ou une ressource partagée. Dans cet exemple, vous allez créer une condition de concurrence importante qui se produit à chaque fois, mais sachez que la plupart des conditions de concurrence ne sont pas aussi évidentes. Souvent, ils ne se produisent que rarement et peuvent produire des résultats déroutants. Comme vous pouvez l'imaginer, cela les rend assez difficiles à déboguer.
Heureusement, cette situation de compétition se produira à chaque fois et vous la parcourrez en détail pour expliquer ce qui se passe.
Pour cet exemple, vous allez écrire une classe qui met à jour une base de données. OK, vous n’allez pas vraiment avoir de base de données: vous allez simplement la simuler, parce que ce n’est pas le but de cet article.
Votre FakeDatabase aura .__ init __ () et .mettre à jour() méthodes:
classe FakeDatabase:
def __init__(soi):
soi.valeur = 0
def mettre à jour(soi, prénom):
enregistrement.Info("Fil % s: démarrage de la mise à jour ", prénom)
copie_local = soi.valeur
copie_local + = 1
temps.dormir(0,1)
soi.valeur = copie_local
enregistrement.Info("Fil % s: mise à jour de finition ", prénom)
FakeDatabase garde la trace d'un numéro unique: .valeur. Ce seront les données partagées sur lesquelles vous verrez la condition de concurrence critique.
.__ init __ () initialise simplement .valeur à zéro. Jusqu'ici tout va bien.
.mettre à jour() a l'air un peu étrange. C’est simuler la lecture d’une valeur dans une base de données, y effectuer des calculs, puis réécrire une nouvelle valeur dans la base de données.
Dans ce cas, lire dans la base de données signifie simplement copier .valeur à une variable locale. Le calcul consiste simplement à ajouter un à la valeur, puis .dormir() Pour un peu. Enfin, il réécrit la valeur en copiant la valeur locale dans .valeur.
Voici comment vous utiliserez cette FakeDatabase:
si __prénom__ == "__principale__":
format = "% (asctime) s: %(messages"
enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
datefmt="% H:% M:% S")
base de données = FakeDatabase()
enregistrement.Info("Test de mise à jour. La valeur de départ est %ré. ", base de données.valeur)
avec concurrent.avenir.ThreadPoolExecutor(max_workers=2) comme exécuteur:
pour indice dans intervalle(2):
exécuteur.soumettre(base de données.mettre à jour, indice)
enregistrement.Info("Test de la mise à jour. La valeur finale est %ré. ", base de données.valeur)
Le programme crée un ThreadPoolExecutor avec deux fils et appelle ensuite .soumettre() sur chacun d'eux, en leur disant de courir database.update ().
.soumettre() a une signature qui permet aux arguments positionnels et nommés d'être passés à la fonction s'exécutant dans le thread:
.soumettre(une fonction, *args, **Kwargs)
Dans l'usage ci-dessus, indice est passé comme premier et unique argument de position database.update (). Vous verrez plus loin dans cet article que vous pouvez transmettre plusieurs arguments de la même manière.
Puisque chaque fil court .mettre à jour(), et .mettre à jour() ajoute un à .valeur, vous pourriez vous attendre valeur.base être 2 quand il est imprimé à la fin. Mais vous ne regarderiez pas cet exemple si c'était le cas. Si vous exécutez le code ci-dessus, la sortie ressemble à ceci:
$ ./racecond.py
Test de la mise à jour déverrouillée. La valeur de départ est 0.
Fil 0: démarrage de la mise à jour
Fil 1: démarrage de la mise à jour
Fil 0: fin de la mise à jour
Fil 1: mise à jour de finition
Test de la mise à jour déverrouillée. La valeur finale est 1.
Vous vous attendiez peut-être à ce que cela se produise, mais examinons en détail ce qui se passe réellement ici, car cela facilitera la compréhension de la solution à ce problème.
Un fil
Avant de vous plonger dans ce problème avec deux threads, revenons un peu en arrière et parlons un peu plus en détail du fonctionnement des threads.
Vous ne plongerez pas dans tous les détails ici, car ce n’est pas important à ce niveau. Nous allons également simplifier certaines choses d’une manière qui ne sera pas techniquement exacte, mais qui vous donnera la bonne idée de ce qui se passe.
Quand vous dites à votre ThreadPoolExecutor pour exécuter chaque thread, vous devez lui indiquer quelle fonction exécuter et quels paramètres lui être transmis: executor.submit (database.update, index).
Le résultat est que chacun des threads du pool appellera database.update (index). Notez que base de données est une référence à celui FakeDatabase objet créé dans __principale__. Appel .mettre à jour() sur cet objet appelle une méthode d'instance sur cet objet.
Chaque fil va avoir une référence au même FakeDatabase objet, base de données. Chaque thread aura également une valeur unique, indice, pour faciliter la lecture des instructions de journalisation:
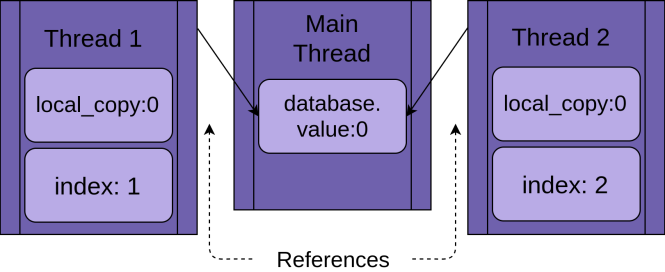
Quand le fil commence à courir .mettre à jour(), il a sa propre version de toutes les données local à la fonction. Dans le cas de .mettre à jour(), c'est copie_local. C'est définitivement une bonne chose. Sinon, deux threads exécutant la même fonction se confondent toujours. Cela signifie que toutes les variables qui sont étendues (ou locales) à une fonction sont thread-safe.
Maintenant, vous pouvez commencer à comprendre ce qui se passe si vous exécutez le programme ci-dessus avec un seul thread et un seul appel à .mettre à jour().
L'image ci-dessous décrit l'exécution de .mettre à jour() si un seul thread est exécuté. La déclaration est affichée à gauche, suivie d’un diagramme montrant les valeurs dans le fil valeur_local et le partagé valeur.base:
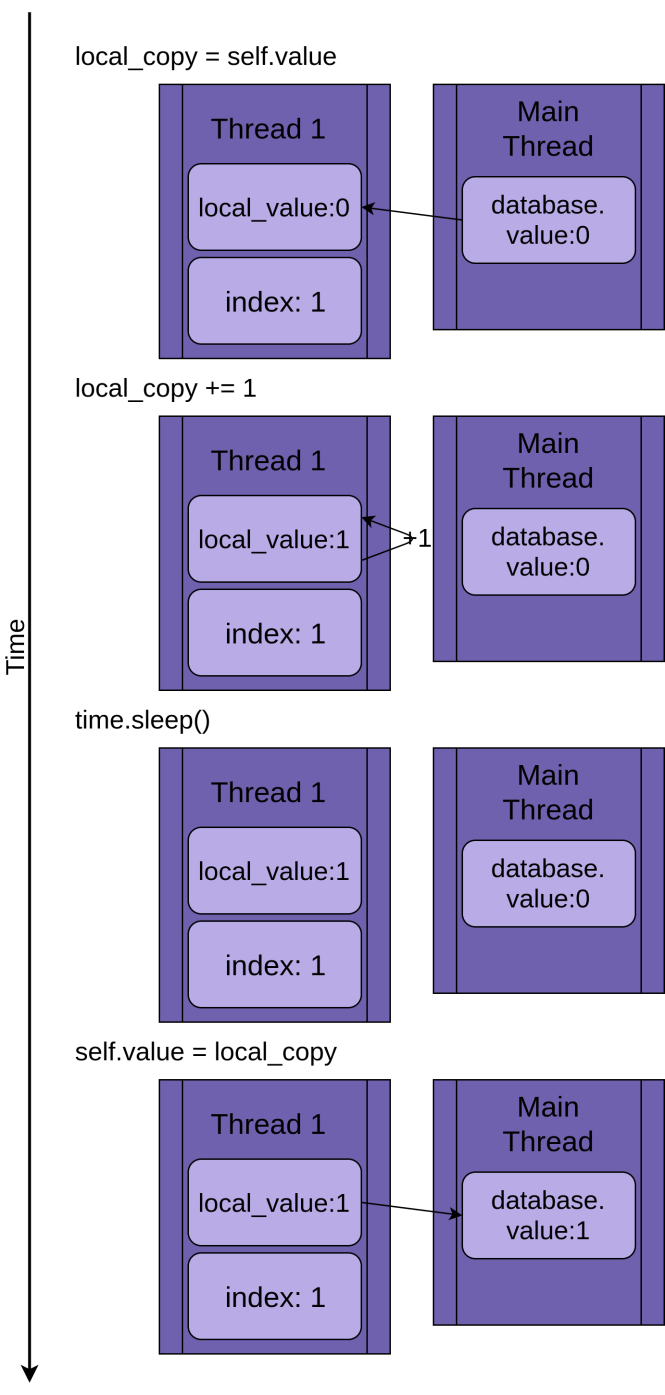
Le diagramme est conçu pour que le temps augmente à mesure que vous vous déplacez de haut en bas. Ça commence quand Fil 1 est créé et se termine quand il est terminé.
Quand Fil 1 départs, FakeDatabase.value est zéro. La première ligne de code de la méthode, copie_local = self.value, copie la valeur zéro dans la variable locale. Ensuite, il augmente la valeur de copie_local avec le copie_local + = 1 déclaration. Tu peux voir .valeur dans Fil 1 se mettre à un.
Suivant le sommeil de temps() est appelé, ce qui met le thread actuel en pause et permet à d'autres threads de s'exécuter. Comme il n'y a qu'un seul thread dans cet exemple, cela n'a aucun effet.
Quand Fil 1 se réveille et continue, il copie la nouvelle valeur de copie_local à FakeDatabase.valueet puis le fil est terminé. Tu peux voir ça valeur.base est mis à un.
Jusqu'ici tout va bien. Vous avez couru .mettre à jour() une fois et FakeDatabase.value a été augmenté à un.
Deux fils
Pour en revenir à la situation de concurrence critique, les deux threads fonctionneront simultanément mais pas au même moment. Ils auront chacun leur propre version de copie_local et chaque point à la même base de données. C'est ce partagé base de données objet qui va causer les problèmes.
Le programme commence par Fil 1 fonctionnement .mettre à jour():

Quand Fil 1 appels le sommeil de temps(), il permet à l’autre thread de commencer à s’exécuter. C'est là que les choses deviennent intéressantes.
Fil 2 démarre et fait les mêmes opérations. C’est aussi la copie valeur.base dans son privé copie_local, et cela partagé valeur.base n'a pas encore été mis à jour:
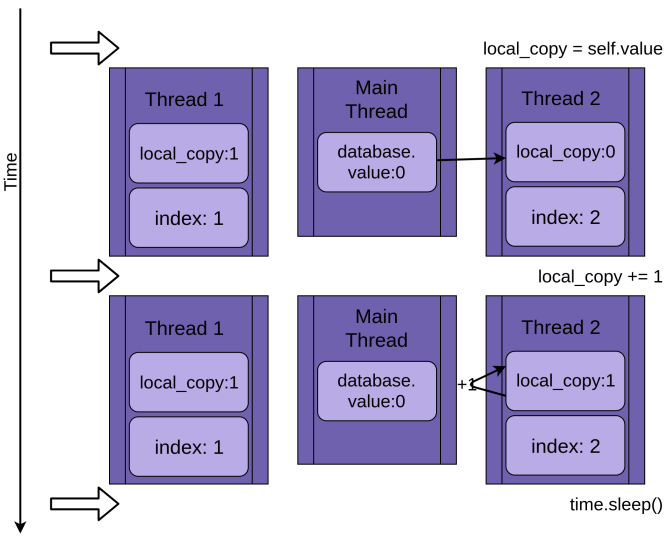
Quand Fil 2 va enfin dormir, le partagé valeur.base est toujours non modifié à zéro, et les deux versions privées de copie_local avoir la valeur un.
Fil 1 se réveille maintenant et enregistre sa version de copie_local puis se termine en donnant Fil 2 une dernière chance de courir. Fil 2 n'a aucune idée que Fil 1 couru et mis à jour valeur.base pendant qu'il dormait. Il stocke ses version de copie_local dans valeur.base, le mettant également à un:

Les deux threads ont un accès entrelacé à un seul objet partagé, en écrasant leurs résultats respectifs. Des conditions de concurrence similaires peuvent survenir lorsqu'un thread libère de la mémoire ou ferme un descripteur de fichier avant que l'autre thread n'ait fini d'y accéder.
Pourquoi ce n’est pas un exemple ridicule
L'exemple ci-dessus est conçu pour garantir que la situation de concurrence critique se produit chaque fois que vous exécutez votre programme. Étant donné que le système d'exploitation peut échanger un fil à tout moment, il est possible d'interrompre une instruction telle que x = x + 1 après avoir lu la valeur de X mais avant qu'il ait écrit la valeur incrémentée.
Les détails de la façon dont cela se produit sont très intéressants, mais ne sont pas nécessaires pour la suite de cet article, alors n'hésitez pas à passer cette section cachée.
Le code ci-dessus n’est pas aussi complet que vous l’auriez peut-être imaginé Il a été conçu pour forcer une situation de compétition à chaque fois que vous l'exécutez, mais cela la rend beaucoup plus facile à résoudre que la plupart des conditions de course.
Il y a deux choses à garder à l'esprit quand on pense aux conditions de course:
-
Même une opération comme
x + = 1prend le processeur de nombreuses étapes. Chacune de ces étapes est une instruction distincte adressée au processeur. -
Le système d'exploitation peut échanger le thread en cours d'exécution à tout moment. Un fil peut être échangé après n'importe laquelle de ces petites instructions. Cela signifie qu’un fil peut être mis en veille pour laisser un autre thread s'exécuter dans la milieu d'une déclaration Python.
Voyons cela en détail. Le REPL ci-dessous montre une fonction qui prend un paramètre et l'incrémente:
>>> def inc(X):
... X + = 1
...
>>> importation dis
>>> dis.dis(inc)
2 0 LOAD_FAST 0 (x)
2 LOAD_CONST 1 (1)
4 INPLACE_ADD
6 STORE_FAST 0 (x)
8 LOAD_CONST 0 (Aucun)
10 RETURN_VALUE
L’exemple REPL utilise dis de la bibliothèque standard Python pour montrer les étapes les plus petites que le processeur effectue pour implémenter votre fonction. Il fait un LOAD_FAST de la valeur de données X, il fait un LOAD_CONST 1et puis il utilise le INPLACE_ADD d'ajouter ces valeurs ensemble.
Nous nous arrêtons ici pour une raison spécifique. C'est le point dans .mettre à jour() ci-dessus où le sommeil de temps() forcé les threads pour basculer. Il est tout à fait possible que, de temps à autre, le système d’exploitation change de thread à cet endroit précis, même sans dormir(), mais l'appel à dormir() y arrive à chaque fois.
Comme vous l'avez appris ci-dessus, le système d'exploitation peut permuter les threads à tout moment. Vous avez parcouru cette liste à la déclaration marquée 4. Si le système d’exploitation échange ce thread et exécute un autre thread qui modifie également X, puis quand ce fil reprendra, il écrasera X avec une valeur incorrecte.
Techniquement, cet exemple n’a pas de condition de concurrence critique car X est local à inc (). Il illustre toutefois comment un thread peut être interrompu au cours d’une seule opération Python. Le même ensemble d'opérations LOAD, MODIFY, STORE est également appliqué aux valeurs globales et partagées. Vous pouvez explorer avec le dis module et prouvez-le vous-même.
Il est rare qu’une telle situation se produise, mais rappelez-vous qu’il est probable qu’un événement peu fréquent, pris sur des millions d’itérations, se produira. La rareté de ces conditions de course les rend beaucoup, beaucoup plus difficiles à déboguer que les bogues ordinaires.
Revenons maintenant à votre tutoriel régulier!
Maintenant que vous avez vu une situation de concurrence en action, voyons comment la résoudre!
Synchronisation de base avec Fermer à clé
Il existe un certain nombre de moyens d'éviter ou de résoudre les conditions de concurrence. Vous ne les regarderez pas tous ici, mais certains sont utilisés fréquemment. Commençons avec Fermer à clé.
Pour résoudre votre situation de concurrence critique ci-dessus, vous devez trouver un moyen de n'autoriser qu'un seul thread à la fois dans la section lecture-modification-écriture de votre code. La façon la plus courante de faire cela s'appelle Fermer à clé en Python. Dans d'autres langues, cette même idée s'appelle un mutex. Mutex vient de MUTual EXclusion, qui est exactement ce qu’est un Fermer à clé Est-ce que.
UNE Fermer à clé est un objet qui agit comme un laissez-passer. Un seul fil à la fois peut avoir le Fermer à clé. Tout autre fil qui veut le Fermer à clé doit attendre que le propriétaire du Fermer à clé l'abandonne.
Les fonctions de base pour ce faire sont .acquérir() et .Libération(). Un fil va appeler my_lock.acquire () obtenir la serrure. Si le verrou est déjà en attente, le thread appelant attendra qu'il soit libéré. Il y a un point important ici. Si un thread obtient le verrou mais ne le rend jamais, votre programme sera bloqué. Vous en saurez plus à ce sujet plus tard.
Heureusement, Python Fermer à clé fonctionnera également en tant que gestionnaire de contexte, de sorte que vous pouvez l'utiliser dans un avec déclaration, et il est publié automatiquement lorsque le avec bloquer les sorties pour une raison quelconque.
Regardons le FakeDatabase avec un Fermer à clé ajouté à cela. La fonction d'appel reste la même:
classe FakeDatabase:
def __init__(soi):
soi.valeur = 0
soi._fermer à clé = filetage.Fermer à clé()
def locked_update(soi, prénom):
enregistrement.Info("Fil % s: démarrage de la mise à jour ", prénom)
enregistrement.déboguer("Fil % s sur le point de verrouiller ", prénom)
avec soi._fermer à clé:
enregistrement.déboguer("Fil % s a verrouillé ", prénom)
copie_local = soi.valeur
copie_local + = 1
temps.dormir(0,1)
soi.valeur = copie_local
enregistrement.déboguer("Fil % s sur le point de libérer le verrou ", prénom)
enregistrement.déboguer("Fil % s après la libération ", prénom)
enregistrement.Info("Fil % s: mise à jour de finition ", prénom)
Outre l'ajout d'un tas de journaux de débogage afin que vous puissiez voir le verrouillage plus clairement, le gros changement consiste à ajouter un membre appelé ._fermer à clé, qui est un threading.Lock () objet. Ce ._fermer à clé est initialisé à l'état déverrouillé et verrouillé et libéré par le avec déclaration.
Il convient de noter ici que le thread exécutant cette fonction conservera cette Fermer à clé jusqu'à la fin de la mise à jour de la base de données. Dans ce cas, cela signifie qu'il tiendra le Fermer à clé pendant qu'il copie, met à jour, met en veille, puis écrit la valeur dans la base de données.
Si vous exécutez cette version avec la journalisation définie sur le niveau d'avertissement, vous verrez ceci:
$ ./fixrace.py
Test de la mise à jour verrouillée. La valeur de départ est 0.
Fil 0: démarrage de la mise à jour
Fil 1: démarrage de la mise à jour
Fil 0: fin de la mise à jour
Fil 1: mise à jour de finition
Test de la mise à jour verrouillée. La valeur finale est 2.
Regarde ça. Votre programme fonctionne enfin!
Vous pouvez activer la journalisation complète en définissant le niveau sur DÉBOGUER en ajoutant cette instruction après avoir configuré la sortie de journalisation __principale__:
enregistrement.getLogger().setLevel(enregistrement.DÉBOGUER)
Lancer ce programme avec DÉBOGUER la journalisation activée ressemble à ceci:
$ ./fixrace.py
Test de la mise à jour verrouillée. La valeur de départ est 0.
Fil 0: démarrage de la mise à jour
Fil 0 sur le point de se verrouiller
Le fil 0 a un verrou
Fil 1: démarrage de la mise à jour
Fil 1 sur le point de verrouiller
Le fil 0 sur le point de libérer le verrou
Fil 0 après la sortie
Fil 0: fin de la mise à jour
Le fil 1 a un verrou
Fil 1 sur le point de libérer le verrou
Fil 1 après la sortie
Fil 1: mise à jour de finition
Test de la mise à jour verrouillée. La valeur finale est 2.
Dans cette sortie, vous pouvez voir Fil 0 acquiert le verrou et le tient toujours lorsqu'il s'endort. Fil 1 puis commence et tente d'acquérir le même verrou. Parce que Fil 0 le tient toujours, Fil 1 doit attendre. C’est l’exclusion mutuelle qu’un Fermer à clé fournit.
De nombreux exemples dans la suite de cet article auront ATTENTION et DÉBOGUER enregistrement de niveau. Nous ne montrerons généralement que les ATTENTION niveau de sortie, comme le DÉBOGUER les journaux peuvent être assez longs. Essayez les programmes avec la journalisation affichée et voyez ce qu’ils font.
Impasse
Avant de poursuivre, vous devez examiner un problème courant lors de l'utilisation de Serrures. Comme vous l'avez vu, si le Fermer à clé a déjà été acquis, un deuxième appel à .acquérir() attendra que le fil qui tient le Fermer à clé appels .Libération(). Que pensez-vous qu'il se passe lorsque vous exécutez ce code:
importation filetage
l = filetage.Fermer à clé()
impression("avant premier acquérir")
l.acquérir()
impression("avant deuxième acquérir")
l.acquérir()
impression("verrou acquis deux fois")
Quand le programme appelle l.acquire () la deuxième fois, il attend en attendant le Fermer à clé être libéré. Dans cet exemple, vous pouvez résoudre le blocage en supprimant le deuxième appel, mais les blocages se produisent généralement de l'une des deux choses les plus subtiles:
- Un bug d'implémentation où un
Fermer à clén'est pas libéré correctement - Un problème de conception où une fonction d’utilité doit être appelée par des fonctions pouvant ou non déjà posséder le
Fermer à clé
La première situation se produit parfois, mais en utilisant un Fermer à clé en tant que gestionnaire de contexte réduit considérablement la fréquence. Il est recommandé d’écrire du code chaque fois que possible pour utiliser les gestionnaires de contexte, car ils permettent d’éviter les situations où une exception vous échappe. .Libération() appel.
Le problème de conception peut être un peu plus compliqué dans certaines langues. Heureusement, les threads Python ont un deuxième objet, appelé RLock, qui est conçu pour cette situation. Cela permet à un fil de .acquérir() un RLock plusieurs fois avant d'appeler .Libération(). Ce fil est toujours nécessaire pour appeler .Libération() le même nombre de fois qu'il a appelé .acquérir(), mais il devrait le faire quand même.
Fermer à clé et RLock sont deux des outils de base utilisés dans la programmation par threads pour éviter les conditions de concurrence critique. Il y en a quelques autres qui fonctionnent de différentes manières. Avant de les regarder, passons à un domaine de problème légèrement différent.
Filetage producteur-consommateur
Le problème producteur-consommateur est un problème informatique standard utilisé pour examiner des problèmes de threading ou de synchronisation de processus. Vous allez en examiner une variante pour vous faire une idée des primitives utilisées par Python. filetage module fournit.
Pour cet exemple, vous allez imaginer un programme qui doit lire des messages d’un réseau et les écrire sur un disque. Le programme ne demande pas de message quand il le souhaite. Il doit être à l'écoute et accepter les messages au fur et à mesure qu'ils arrivent. Les messages n'arriveront pas à un rythme régulier, mais arriveront en rafale. Cette partie du programme s'appelle le producteur.
De l'autre côté, une fois que vous avez un message, vous devez l'écrire dans une base de données. L'accès à la base de données est lent, mais suffisamment rapide pour suivre le rythme moyen des messages. Il est ne pas assez rapide pour suivre le rythme de la rafale de messages. Cette partie est destinée au consommateur.
Entre le producteur et le consommateur, vous créerez un Pipeline ce sera la partie qui changera à mesure que vous en apprendrez sur différents objets de synchronisation.
C’est la disposition de base. Examinons une solution en utilisant Fermer à clé. Cela ne fonctionne pas parfaitement, mais il utilise des outils que vous connaissez déjà, c’est donc un bon point de départ.
Utilisation du producteur-consommateur Fermer à clé
Comme il s'agit d'un article sur Python filetageet puisque vous venez de lire sur le Fermer à clé primitive, essayons de résoudre ce problème avec deux threads en utilisant un Fermer à clé ou deux.
La conception générale est qu'il y a un producteur fil qui lit le faux réseau et met le message dans un Pipeline:
SENTINELLE = objet()
def producteur(pipeline):
"" "Imaginez que nous recevions un message du réseau." ""
pour indice dans intervalle(dix):
message = au hasard.randint(1, 101)
enregistrement.Info("Le producteur a eu un message: % s", message)
pipeline.set_message(message, "Producteur")
# Envoyer un message sentinelle pour dire au consommateur que nous avons terminé
pipeline.set_message(SENTINELLE, "Producteur")
Pour générer un faux message, le producteur obtient un nombre aléatoire compris entre un et cent. Il appelle .set_message () sur le pipeline l'envoyer au consommateur.
le producteur utilise également un SENTINELLE valeur pour signaler au consommateur de s'arrêter après l'envoi de dix valeurs. C’est un peu gênant, mais ne vous inquiétez pas, vous verrez des moyens de vous en débarrasser. SENTINELLE valeur après avoir travaillé à travers cet exemple.
De l'autre côté de la pipeline est le consommateur:
def consommateur(pipeline):
"" "Imaginons que nous sauvegardons un numéro dans la base de données." ""
message = 0
tandis que message est ne pas SENTINELLE:
message = pipeline.get_message("Consommateur")
si message est ne pas SENTINELLE:
enregistrement.Info("Consommateur stockant le message: % s", message)
le consommateur lit un message du pipeline et l'écrit dans une fausse base de données, qui dans ce cas est en train de l'imprimer à l'écran. Si cela devient le SENTINELLE valeur, il retourne de la fonction, ce qui terminera le thread.
Avant de regarder la partie vraiment intéressante, la Pipeline, Ici se trouve le __principale__ section, qui engendre ces discussions:
si __prénom__ == "__principale__":
format = "% (asctime) s: %(messages"
enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
datefmt="% H:% M:% S")
# logging.getLogger (). setLevel (logging.DEBUG)
pipeline = Pipeline()
avec concurrent.avenir.ThreadPoolExecutor(max_workers=2) comme exécuteur:
exécuteur.soumettre(producteur, pipeline)
exécuteur.soumettre(consommateur, pipeline)
Cela devrait sembler assez familier car il est proche de la __principale__ code dans les exemples précédents.
Rappelez-vous que vous pouvez allumer DÉBOGUER en vous connectant pour voir tous les messages de journalisation en supprimant la mise en commentaire de cette ligne:
# logging.getLogger (). setLevel (logging.DEBUG)
Il peut être intéressant de traverser la DÉBOGUER enregistrer des messages pour voir exactement où chaque thread acquiert et libère les verrous.
Voyons maintenant le Pipeline qui transmet des messages du producteur au consommateur:
classe Pipeline:
"" "
Classe permettant un pipeline à élément unique entre le producteur et le consommateur.
"" "
def __init__(soi):
soi.message = 0
soi.producteur_lock = filetage.Fermer à clé()
soi.consumer_lock = filetage.Fermer à clé()
soi.consumer_lock.acquérir()
def get_message(soi, prénom):
enregistrement.déboguer("% s: sur le point d'acquérir getlock ", prénom)
soi.consumer_lock.acquérir()
enregistrement.déboguer("% s: avoir getlock ", prénom)
message = soi.message
enregistrement.déboguer("% s: sur le point de libérer setlock ", prénom)
soi.producer_lock.Libération()
enregistrement.déboguer("% s:setlock released", prénom)
revenir message
def set_message(soi, message, prénom):
enregistrement.déboguer("% s:about to acquire setlock", prénom)
soi.producer_lock.acquérir()
enregistrement.déboguer("% s:have setlock", prénom)
soi.message = message
enregistrement.déboguer("% s:about to release getlock", prénom)
soi.consumer_lock.Libération()
enregistrement.déboguer("% s:getlock released", prénom)
Woah! That’s a lot of code. A pretty high percentage of that is just logging statements to make it easier to see what’s happening when you run it. Here’s the same code with all of the logging statements removed:
classe Pipeline:
"" "
Class to allow a single element pipeline between producer and consumer.
"" "
def __init__(soi):
soi.message = 0
soi.producer_lock = filetage.Fermer à clé()
soi.consumer_lock = filetage.Fermer à clé()
soi.consumer_lock.acquérir()
def get_message(soi, prénom):
soi.consumer_lock.acquérir()
message = soi.message
soi.producer_lock.Libération()
revenir message
def set_message(soi, message, prénom):
soi.producer_lock.acquérir()
soi.message = message
soi.consumer_lock.Libération()
That seems a bit more manageable. le Pipeline in this version of your code has three members:
.messagestores the message to pass..producer_lockest unthreading.Lockobject that restricts access to the message by theproducteurthread..consumer_lockest aussi unthreading.Lockthat restricts access to the message by theconsommateurthread.
__init__() initializes these three members and then calls .acquire() sur le .consumer_lock. This is the state you want to start in. The producteur is allowed to add a new message, but the consommateur needs to wait until a message is present.
.get_message() et .set_messages() are nearly opposites. .get_message() appels .acquire() sur le consumer_lock. This is the call that will make the consommateur wait until a message is ready.
Once the consommateur has acquired the .consumer_lock, it copies out the value in .message and then calls .release() sur le .producer_lock. Releasing this lock is what allows the producteur to insert the next message into the pipeline.
Before you go on to .set_message(), there’s something subtle going on in .get_message() that’s pretty easy to miss. It might seem tempting to get rid of message and just have the function end with return self.message. See if you can figure out why you don’t want to do that before moving on.
Here’s the answer. As soon as the consommateur appels .producer_lock.release(), it can be swapped out, and the producteur can start running. That could happen before .release() returns! This means that there is a slight possibility that when the function returns self.message, that could actually be the suivant message generated, so you would lose the first message. This is another example of a race condition.
Moving on to .set_message(), you can see the opposite side of the transaction. le producteur will call this with a message. It will acquire the .producer_lock, set the .message, and the call .release() on then consumer_lock, which will allow the consommateur to read that value.
Let’s run the code that has logging set to ATTENTION and see what it looks like:
$ ./prodcom_lock.py
Producer got data 43
Producer got data 45
Consumer storing data: 43
Producer got data 86
Consumer storing data: 45
Producer got data 40
Consumer storing data: 86
Producer got data 62
Consumer storing data: 40
Producer got data 15
Consumer storing data: 62
Producer got data 16
Consumer storing data: 15
Producer got data 61
Consumer storing data: 16
Producer got data 73
Consumer storing data: 61
Producer got data 22
Consumer storing data: 73
Consumer storing data: 22
At first, you might find it odd that the producer gets two messages before the consumer even runs. If you look back at the producteur et .set_message(), you will notice that the only place it will wait for a Fermer à clé is when it attempts to put the message into the pipeline. This is done after the producteur gets the message and logs that it has it.
When the producteur attempts to send this second message, it will call .set_message() the second time and it will block.
The operating system can swap threads at any time, but it generally lets each thread have a reasonable amount of time to run before swapping it out. That’s why the producteur usually runs until it blocks in the second call to .set_message().
Once a thread is blocked, however, the operating system will always swap it out and find a different thread to run. In this case, the only other thread with anything to do is the consommateur.
le consommateur appels .get_message(), which reads the message and calls .release() sur le .producer_lock, thus allowing the producteur to run again the next time threads are swapped.
Notice that the first message was 43, and that is exactly what the consommateur read, even though the producteur had already generated the 45 message.
While it works for this limited test, it is not a great solution to the producer-consumer problem in general because it only allows a single value in the pipeline at a time. When the producteur gets a burst of messages, it will have nowhere to put them.
Let’s move on to a better way to solve this problem, using a Queue.
Producer-Consumer Using Queue
If you want to be able to handle more than one value in the pipeline at a time, you’ll need a data structure for the pipeline that allows the number to grow and shrink as data backs up from the producteur.
Python’s standard library has a queue module which, in turn, has a Queue class. Let’s change the Pipeline utiliser un Queue instead of just a variable protected by a Fermer à clé. You’ll also use a different way to stop the worker threads by using a different primitive from Python filetage, an un événement.
Let’s start with the un événement. le threading.Event object allows one thread to signal an un événement while many other threads can be waiting for that un événement to happen. The key usage in this code is that the threads that are waiting for the event do not necessarily need to stop what they are doing, they can just check the status of the un événement every once in a while.
The triggering of the event can be many things. In this example, the main thread will simply sleep for a while and then .set() it:
1 si __name__ == "__main__":
2 format = "%(asctime)s: %(message)s"
3 enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
4 datefmt="%H:%M:%S")
5 # logging.getLogger().setLevel(logging.DEBUG)
6
7 pipeline = Pipeline()
8 un événement = filetage.un événement()
9 avec concurrent.avenir.ThreadPoolExecutor(max_workers=2) comme exécuteur:
dix exécuteur.soumettre(producteur, pipeline, un événement)
11 exécuteur.soumettre(consommateur, pipeline, un événement)
12
13 temps.dormir(0.1)
14 enregistrement.Info("Main: about to set event")
15 un événement.ensemble()
The only changes here are the creation of the un événement object on line 6, passing the un événement as a parameter on lines 8 and 9, and the final section on lines 11 to 13, which sleep for a second, log a message, and then call .set() on the event.
le producteur also did not have to change too much:
1 def producteur(pipeline, un événement):
2 """Pretend we're getting a number from the network."""
3 tandis que ne pas un événement.is_set():
4 message = au hasard.randint(1, 101)
5 enregistrement.Info("Producer got message: % s", message)
6 pipeline.set_message(message, "Producer")
7
8 enregistrement.Info("Producer received EXIT event. Exiting")
It now will loop until it sees that the event was set on line 3. It also no longer puts the SENTINEL value into the pipeline.
consommateur had to change a little more:
1 def consommateur(pipeline, un événement):
2 """Pretend we're saving a number in the database."""
3 tandis que ne pas un événement.is_set() ou ne pas pipeline.vide():
4 message = pipeline.get_message("Consumer")
5 enregistrement.Info(
6 "Consumer storing message: % s (queue size=% s)",
7 message,
8 pipeline.qsize(),
9 )
dix
11 enregistrement.Info("Consumer received EXIT event. Exiting")
While you got to take out the code related to the SENTINEL value, you did have to do a slightly more complicated tandis que condition. Not only does it loop until the un événement is set, but it also needs to keep looping until the pipeline has been emptied.
Making sure the queue is empty before the consumer finishes prevents another fun issue. Si la consommateur does exit while the pipeline has messages in it, there are two bad things that can happen. The first is that you lose those final messages, but the more serious one is that the producteur can get caught on the producer_lock and never return.
This happens if the un événement gets triggered after the producteur has checked the .is_set() condition but before it calls pipeline.set_message().
If that happens, it’s possible for the producer to wake up and exit with the .producer_lock still being held. le producteur will then try to .acquire() la .producer_lock, but the consommateur has exited and will never .release() il.
The rest of the consommateur should look familiar.
le Pipeline has changed dramatically, however:
1 classe Pipeline(queue.Queue):
2 def __init__(soi):
3 super().__init__(maxsize=dix)
4
5 def get_message(soi, prénom):
6 enregistrement.déboguer("% s:about to get from queue", prénom)
7 valeur = soi.obtenir()
8 enregistrement.déboguer("% s:got %d from queue", prénom, valeur)
9 revenir valeur
dix
11 def set_message(soi, valeur, prénom):
12 enregistrement.déboguer("% s:about to add %d to queue", prénom, valeur)
13 soi.mettre(valeur)
14 enregistrement.déboguer("% s:added %d to queue", prénom, valeur)
You can see that Pipeline is a subclass of queue.Queue. Queue has an optional parameter when initializing to specify a maximum size of the queue.
If you give a positive number for maxsize, it will limit the queue to that number of elements, causing .put() to block until there are fewer than maxsize elements. If you don’t specify maxsize, then the queue will grow to the limits of your computer’s memory.
.get_message() et .set_message() got much smaller. They basically wrap .obtenir() et .put() sur le Queue. You might be wondering where all of the locking code that prevents the threads from causing race conditions went.
The core devs who wrote the standard library knew that a Queue is frequently used in multi-threading environments and incorporated all of that locking code inside the Queue lui-même. Queue is thread-safe.
Running this program looks like the following:
$ ./prodcom_queue.py
Producer got message: 32
Producer got message: 51
Producer got message: 25
Producer got message: 94
Producer got message: 29
Consumer storing message: 32 (queue size=3)
Producer got message: 96
Consumer storing message: 51 (queue size=3)
Producer got message: 6
Consumer storing message: 25 (queue size=3)
Producer got message: 31
[many lines deleted]
Producer got message: 80
Consumer storing message: 94 (queue size=6)
Producer got message: 33
Consumer storing message: 20 (queue size=6)
Producer got message: 48
Consumer storing message: 31 (queue size=6)
Producer got message: 52
Consumer storing message: 98 (queue size=6)
Main: about to set event
Producer got message: 13
Consumer storing message: 59 (queue size=6)
Producer received EXIT event. Exiting
Consumer storing message: 75 (queue size=6)
Consumer storing message: 97 (queue size=5)
Consumer storing message: 80 (queue size=4)
Consumer storing message: 33 (queue size=3)
Consumer storing message: 48 (queue size=2)
Consumer storing message: 52 (queue size=1)
Consumer storing message: 13 (queue size=0)
Consumer received EXIT event. Exiting
If you read through the output in my example, you can see some interesting things happening. Right at the top, you can see the producteur got to create five messages and place four of them on the queue. It got swapped out by the operating system before it could place the fifth one.
le consommateur then ran and pulled off the first message. It printed out that message as well as how deep the queue was at that point:
Consumer storing message: 32 (queue size=3)
This is how you know that the fifth message hasn’t made it into the pipeline encore. The queue is down to size three after a single message was removed. You also know that the queue can hold ten messages, so the producteur thread didn’t get blocked by the queue. It was swapped out by the OS.
Remarque: Your output will be different. Your output will change from run to run. That’s the fun part of working with threads!
As the program starts to wrap up, can you see the main thread generating the un événement which causes the producteur to exit immediately. le consommateur still has a bunch of work do to, so it keeps running until it has cleaned out the pipeline.
Try playing with different queue sizes and calls to time.sleep() dans le producteur ou la consommateur to simulate longer network or disk access times respectively. Even slight changes to these elements of the program will make large differences in your results.
This is a much better solution to the producer-consumer problem, but you can simplify it even more. le Pipeline really isn’t needed for this problem. Once you take away the logging, it just becomes a queue.Queue.
Here’s what the final code looks like using queue.Queue directly:
importation concurrent.futures
importation enregistrement
importation queue
importation au hasard
importation filetage
importation temps
def producteur(queue, un événement):
"""Pretend we're getting a number from the network."""
tandis que ne pas un événement.is_set():
message = au hasard.randint(1, 101)
enregistrement.Info("Producer got message: % s", message)
queue.mettre(message)
enregistrement.Info("Producer received event. Exiting")
def consommateur(queue, un événement):
"""Pretend we're saving a number in the database."""
tandis que ne pas un événement.is_set() ou ne pas queue.vide():
message = queue.obtenir()
enregistrement.Info(
"Consumer storing message: % s (size=%d)", message, queue.qsize()
)
enregistrement.Info("Consumer received event. Exiting")
si __name__ == "__main__":
format = "%(asctime)s: %(message)s"
enregistrement.basicConfig(format=format, niveau=enregistrement.INFO,
datefmt="%H:%M:%S")
pipeline = queue.Queue(maxsize=dix)
un événement = filetage.un événement()
avec concurrent.avenir.ThreadPoolExecutor(max_workers=2) comme exécuteur:
exécuteur.soumettre(producteur, pipeline, un événement)
exécuteur.soumettre(consommateur, pipeline, un événement)
temps.dormir(0.1)
enregistrement.Info("Main: about to set event")
un événement.ensemble()
That’s easier to read and shows how using Python’s built-in primitives can simplify a complex problem.
Fermer à clé et Queue are handy classes to solve concurrency issues, but there are others provided by the standard library. Before you wrap up this tutorial, let’s do a quick survey of some of them.
Threading Objects
There are a few more primitives offered by the Python filetage module. While you didn’t need these for the examples above, they can come in handy in different use cases, so it’s good to be familiar with them.
Semaphore
The first Python filetage object to look at is threading.Semaphore. UNE Semaphore is a counter with a few special properties. The first one is that the counting is atomic. This means that there is a guarantee that the operating system will not swap out the thread in the middle of incrementing or decrementing the counter.
The internal counter is incremented when you call .release() and decremented when you call .acquire().
The next special property is that if a thread calls .acquire() when the counter is zero, that thread will block until a different thread calls .release() and increments the counter to one.
Semaphores are frequently used to protect a resource that has a limited capacity. An example would be if you have a pool of connections and want to limit the size of that pool to a specific number.
Timer
UNE threading.Timer is a way to schedule a function to be called after a certain amount of time has passed. You create a Timer by passing in a number of seconds to wait and a function to call:
t = filetage.Timer(30.0, my_function)
You start the Timer by calling .start(). The function will be called on a new thread at some point after the specified time, but be aware that there is no promise that it will be called exactly at the time you want.
If you want to stop a Timer that you’ve already started, you can cancel it by calling .cancel(). Appel .cancel() après le Timer has triggered does nothing and does not produce an exception.
UNE Timer can be used to prompt a user for action after a specific amount of time. If the user does the action before the Timer expires, .cancel() can be called.
Barrier
UNE threading.Barrier can be used to keep a fixed number of threads in sync. When creating a Barrier, the caller must specify how many threads will be synchronizing on it. Each thread calls .wait() sur le Barrier. They all will remain blocked until the specified number of threads are waiting, and then the are all released at the same time.
Remember that threads are scheduled by the operating system so, even though all of the threads are released simultaneously, they will be scheduled to run one at a time.
One use for a Barrier is to allow a pool of threads to initialize themselves. Having the threads wait on a Barrier after they are initialized will ensure that none of the threads start running before all of the threads are finished with their initialization.
Conclusion: Threading in Python
You’ve now seen much of what Python filetage has to offer and some examples of how to build threaded programs and the problems they solve. You’ve also seen a few instances of the problems that arise when writing and debugging threaded programs.
If you’d like to explore other options for concurrency in Python, check out Speed Up Your Python Program With Concurrency.
If you’re interested in doing a deep dive on the asyncio module, go read Async IO in Python: A Complete Walkthrough.
Whatever you do, you now have the information and confidence you need to write programs using Python threading!
Special thanks to reader JL Diaz for helping to clean up the introduction.
Take the Quiz: Test your knowledge with our interactive “Python Threading” quiz. Upon completion you will receive a score so you can track your learning progress over time:
Take the Quiz »
[ad_2]