Formation Python
- 5 meilleurs plugins pour accepter des dons avec WordPress
- Rechercher des expressions rationnelles et remplacer des exemples de scripts
- Travailler efficacement avec les données – Real Python
- Meilleur plugin de sécurité WordPress 2020: analyses de pare-feu et de logiciels malveillants
- Épisode n ° 28 Rendre rapide Python: Profiler le code Python
NumPy est une bibliothèque Python qui fournit une structure de données simple mais puissante: le tableau à n dimensions. C'est sur cette base que repose presque toute la puissance de la boîte à outils de science des données de Python, et l'apprentissage de NumPy est la première étape du parcours de tout scientifique de données Python. Ce didacticiel vous fournira les connaissances dont vous avez besoin pour utiliser NumPy et les bibliothèques de niveau supérieur qui en dépendent.
Dans ce didacticiel, vous apprendrez:
- Quoi concepts de base en science des données sont rendus possibles par NumPy
- Comment créer Tableaux NumPy en utilisant diverses méthodes
- Comment manipuler des tableaux NumPy pour effectuer calculs utiles
- Comment appliquer ces nouvelles compétences à problèmes du monde réel
Pour tirer le meilleur parti de ce didacticiel NumPy, vous devez être familiarisé avec l'écriture de code Python. Le parcours d'apprentissage Introduction à Python est un excellent moyen de vous assurer que vous maîtrisez les compétences de base. Si vous êtes familier avec les mathématiques matricielles, cela vous sera certainement utile également. Cependant, vous n'avez pas besoin de savoir quoi que ce soit sur la science des données. Vous l'apprendrez ici.
Il existe également un référentiel d'exemples de code NumPy que vous verrez tout au long de ce didacticiel. Vous pouvez l'utiliser comme référence et tester les exemples pour voir comment la modification du code modifie le résultat. Pour télécharger le code, cliquez sur le lien ci-dessous:
Choisir NumPy: les avantages
Puisque vous connaissez déjà Python, vous vous demandez peut-être si vous devez vraiment apprendre un tout nouveau paradigme pour faire de la science des données. Python pour les boucles sont géniales! La lecture et l'écriture de fichiers CSV peuvent être effectuées avec du code traditionnel. Cependant, il existe des arguments convaincants pour apprendre un nouveau paradigme.
Voici les quatre principaux avantages que NumPy peut apporter à votre code:
- Plus vite: NumPy utilise des algorithmes écrits en C qui se terminent en nanosecondes plutôt qu'en secondes.
- Moins de boucles: NumPy vous aide à réduire les boucles et à éviter de vous embrouiller dans les index d'itération.
- Code plus clair: Sans boucles, votre code ressemblera davantage aux équations que vous essayez de calculer.
- Meilleure qualité: Il y a des milliers de contributeurs qui s'efforcent de garder NumPy rapide, convivial et sans bogue.
En raison de ces avantages, NumPy est la norme de facto pour les tableaux multidimensionnels dans la science des données Python, et la plupart des bibliothèques les plus populaires sont construites dessus. Apprendre NumPy est un excellent moyen d'établir une base solide à mesure que vous développez vos connaissances dans des domaines plus spécifiques de la science des données.
Installation de NumPy
Il est temps de tout configurer pour que vous puissiez commencer à apprendre à travailler avec NumPy. Il existe plusieurs façons de procéder, et vous ne pouvez pas vous tromper en suivant les instructions sur le site Web NumPy. Mais il y a quelques détails supplémentaires à connaître qui sont décrits ci-dessous.
Vous installerez également Matplotlib. Vous l'utiliserez dans l'un des exemples suivants pour découvrir comment d'autres bibliothèques utilisent NumPy.
Utilisation de Repl.it comme éditeur en ligne
Si vous voulez simplement commencer avec quelques exemples, suivez ce didacticiel et commencez à créer de la mémoire musculaire avec NumPy, Repl.it est une excellente option pour l'édition dans le navigateur. Vous pouvez vous inscrire et lancer un environnement Python en quelques minutes. Sur le côté gauche, il y a un onglet pour les packages. Vous pouvez en ajouter autant que vous le souhaitez. Pour ce didacticiel NumPy, utilisez les versions actuelles de NumPy et Matplotlib.
Voici où vous pouvez trouver les packages dans l'interface:
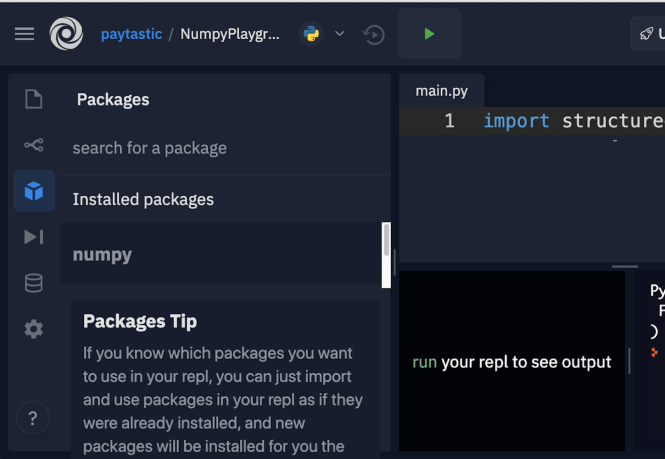
Heureusement, ils vous permettent de cliquer et d'installer.
Installation de NumPy avec Anaconda
La distribution Anaconda est une suite d'outils communs de science des données Python regroupés autour d'un directeur chargé d'emballage qui aide à gérer vos environnements virtuels et les dépendances de projet. Il est construit autour conda, qui est le véritable gestionnaire de paquets. C'est la méthode recommandée par le projet NumPy, en particulier si vous vous lancez dans la science des données en Python sans avoir déjà configuré un environnement de développement complexe.
Si vous avez déjà un workflow que vous aimez et qui utilise pépin, Pipenv, Poetry ou un autre ensemble d'outils, il serait peut-être préférable de ne pas ajouter conda au mélange. le conda le référentiel de packages est séparé de PyPI, et conda lui-même met en place un petit îlot séparé de paquets sur votre machine, donc gérer les chemins et se souvenir de quel paquet vit où peut être un cauchemar.
Une fois que vous avez conda installé, vous pouvez exécuter le installer commande pour les bibliothèques dont vous aurez besoin:
$ conda installer numpy matplotlib
Cela installera ce dont vous avez besoin pour ce didacticiel NumPy, et vous serez prêt à partir.
Installation de NumPy avec pépin
Bien que le projet NumPy recommande d'utiliser conda si vous recommencez à neuf, il n'y a rien de mal à gérer vous-même votre environnement et à utiliser simplement du bon vieux pépin, Pipenv, Poetry, ou toute autre alternative à pépin est votre préféré.
Voici les commandes à configurer pépin:
$ mkdir numpy-tutoriel
$ CD tutoriel numpy
$ python3 -m venv .numpy-tutorial-venv
$ la source .numpy-tutorial-venv / bin / activate
(.numpy-tutorial-venv)
$ pip installer numpy matplotlib
Collecter numpy
Téléchargement de numpy-1.19.1-cp38-cp38-macosx_10_9_x86_64.whl (15,3 Mo)
| ████████████████████████████████ | 15,3 Mo 2,7 Mo / s
Collecter matplotlib
Téléchargement de matplotlib-3.3.0-1-cp38-cp38-macosx_10_9_x86_64.whl (11,4 Mo)
| ████████████████████████████████ | 11,4 Mo 16,8 Mo / s
...
Après cela, assurez-vous que votre environnement virtuel est activé et que tout votre code doit s'exécuter comme prévu.
Utilisation d'IPython, de notebooks ou de JupyterLab
Bien que les sections ci-dessus devraient vous fournir tout ce dont vous avez besoin pour commencer, vous pouvez éventuellement installer quelques outils supplémentaires pour rendre le travail dans la science des données plus convivial pour les développeurs.
IPython est une boucle Python read-eval-print (REPL) mise à niveau qui rend l'édition de code dans une session d'interprétation en direct plus simple et plus jolie. Voici à quoi ressemble une session IPython REPL:
Dans [1]: importer engourdi comme np
Dans [2]: chiffres = np.tableau([[[[
...: [[[[1, 2, 3],
...: [[[[4, 5, 6],
...: [[[[6, sept, 9],
...: ])
Dans [3]: chiffres
En dehors[3]:
tableau ([[1, 2, 3],
[4, 5, 6],
[6, 7, 9]])
Il présente plusieurs différences par rapport à un REPL Python de base, notamment ses numéros de ligne, l'utilisation de couleurs et la qualité des visualisations de tableau. Il existe également de nombreux bonus d'expérience utilisateur qui rendent plus agréable la saisie, la ré-saisie et la modification du code.
Vous pouvez installer IPython de manière autonome:
Sinon, si vous attendez et installez l'un des outils suivants, ils incluront une copie d'IPython.
Une alternative légèrement plus fonctionnelle à une REPL est une carnet. Cependant, les notebooks sont un style d'écriture Python légèrement différent de celui des scripts standard. Au lieu d'un fichier Python traditionnel, ils vous donnent une série de mini-scripts appelés cellules que vous pouvez exécuter et réexécuter dans l'ordre de votre choix, le tout dans la même session de mémoire Python.
Une chose intéressante à propos des blocs-notes est que vous pouvez inclure des graphiques et rendre des paragraphes Markdown entre les cellules, ils sont donc vraiment utiles pour rédiger des analyses de données directement dans le code!
Voici à quoi cela ressemble:

L'offre de bloc-notes la plus populaire est probablement le bloc-notes Jupyter, mais nteract est une autre option qui englobe la fonctionnalité Jupyter et tente de la rendre un peu plus accessible et puissante.
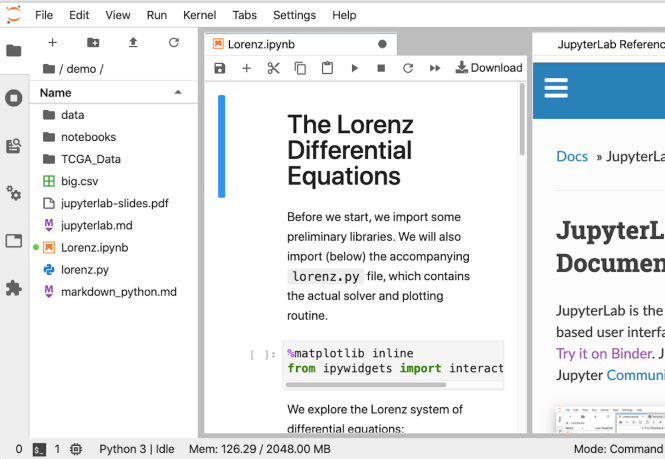
Cependant, si vous regardez Jupyter Notebook et pensez qu'il a besoin de plus de qualités de type IDE, JupyterLab est une autre option. Vous pouvez personnaliser les éditeurs de texte, les blocs-notes, les terminaux et les composants personnalisés, le tout dans une interface basée sur un navigateur. Ce sera probablement plus confortable pour les personnes venant de MatLab. C'est la plus récente des offres, mais sa version 1.0 était de retour en 2019, elle devrait donc être stable et complète.
Voici à quoi ressemble l'interface:
Quelle que soit l'option que vous choisissez, une fois que vous l'avez installée, vous serez prêt à exécuter vos premières lignes de code NumPy. Il est temps pour le premier exemple.
Bonjour NumPy: Tutoriel sur les notes de test de courbe
Ce premier exemple présente quelques concepts de base de NumPy que vous utiliserez tout au long du reste du didacticiel:
- Création de tableaux en utilisant
numpy.array () - Traiter des tableaux complets comme des valeurs individuelles pour rendre les calculs vectorisés plus lisibles
- Utilisation des fonctions NumPy intégrées pour modifier et agréger les données
Ces concepts sont au cœur de l'utilisation efficace de NumPy.
Le scénario est le suivant: vous êtes un enseignant qui vient de noter vos élèves sur un test récent. Malheureusement, vous avez peut-être rendu le test trop difficile et la plupart des élèves ont fait pire que prévu. Pour aider tout le monde, vous allez courbe les notes de tout le monde.
Ce sera une courbe relativement rudimentaire, cependant. Vous prendrez quel que soit le score moyen et déclarerez qu'un C. De plus, vous vous assurerez que la courbe n'est pas accidentellement blesser les notes de vos élèves ou leur aide à tel point que l’élève fait mieux que 100%
Entrez ce code dans votre REPL:
1>>> importer engourdi comme np
2>>> CURVE_CENTER = 80
3>>> grades = np.tableau([[[[72, 35, 64, 88, 51, 90, 74, 12])
4>>> def courbe(grades):
5... moyenne = grades.signifier()
6... changement = CURVE_CENTER - moyenne
sept... new_grades = grades + changement
8... revenir np.agrafe(new_grades, grades, 100)
9...
dix>>> courbe(grades)
11tableau ([ 91.25, 54.25, 83.25, 100. , 70.25, 100. , 93.25, 31.25])
Les scores originaux ont été augmentés en fonction de leur position dans le peloton, mais aucun d'entre eux n'a été poussé au-dessus de 100%.
Voici les faits saillants importants:
- Ligne 1 importe NumPy à l'aide de
npalias, qui est une convention courante qui vous évite quelques frappes. - Ligne 3 crée votre premier NumPy tableau, qui est unidimensionnel et a une forme de
(8,)et un type de donnéesint64. Ne vous inquiétez pas encore trop de ces détails. Vous les découvrirez plus en détail plus loin dans le didacticiel. - Ligne 5 prend la moyenne de tous les scores en utilisant
.signifier(). Les tableaux ont un lot des méthodes.
Sur la ligne 7, vous profitez de deux concepts importants à la fois:
- Vectorisation
- Diffusion
Vectorisation est le processus qui consiste à effectuer la même opération de la même manière pour chaque élément d'un tableau. Cela supprime pour boucle de votre code mais obtient le même résultat.
Diffusion est le processus consistant à étendre deux tableaux de formes différentes et à déterminer comment effectuer un calcul vectorisé entre eux. Rappelles toi, grades est un tableau de nombres de forme (8,) et changement est un scalaire, ou numéro unique, essentiellement avec la forme (1,). Dans ce cas, NumPy ajoute le scalaire à chaque élément du tableau et renvoie un nouveau tableau avec les résultats.
Enfin, à la ligne 8, vous limitez, ou agrafe, les valeurs à un ensemble de minimums et maximums. En plus des méthodes de tableau, NumPy dispose également d'un grand nombre de fonctions intégrées. Vous n’avez pas besoin de tous les mémoriser, c’est à cela que sert la documentation. Chaque fois que vous êtes bloqué ou que vous pensez qu'il devrait y avoir un moyen plus simple de faire quelque chose, jetez un œil à la documentation et voyez s'il n'y a pas déjà une routine qui fait exactement ce dont vous avez besoin.
Dans ce cas, vous avez besoin d'une fonction qui prend un tableau et s'assure que les valeurs ne dépassent pas un minimum ou un maximum donné. agrafe() fait exactement cela.
La ligne 8 fournit également un autre exemple de diffusion. Pour le deuxième argument de agrafe(), vous passez grades, en veillant à ce que chaque nouvelle courbe ne soit pas inférieure à la note d'origine. Mais pour le troisième argument, vous passez une seule valeur: 100. NumPy prend cette valeur et la diffuse sur chaque élément de new_grades, garantissant qu'aucune des notes nouvellement courbées ne dépasse un score parfait.
Mise en forme: formes et axes de tableau
Maintenant que vous avez vu une partie de ce que NumPy peut faire, il est temps de renforcer cette base avec une théorie importante. Il est important de garder à l'esprit quelques concepts, en particulier lorsque vous travaillez avec des tableaux de dimensions supérieures.
Vecteurs, qui sont des tableaux de nombres unidimensionnels, sont les moins compliqués à suivre. Deux dimensions ne sont pas trop mauvaises non plus, car elles sont similaires aux feuilles de calcul. Mais les choses commencent à devenir délicates à trois dimensions, et en visualiser quatre? Oublie ça.
Maîtriser la forme
La forme est un concept clé lorsque vous utilisez des tableaux multidimensionnels. À un moment donné, il est plus facile d’oublier la visualisation de la forme de vos données et de suivre certaines règles mentales et de faire confiance à NumPy pour vous indiquer la forme correcte.
Tous les tableaux ont une propriété appelée .forme qui renvoie un tuple de la taille dans chaque dimension. La dimension est moins importante, mais il est essentiel que les tableaux que vous transmettez aux fonctions aient la forme attendue par les fonctions. Un moyen courant de vérifier que vos données ont la forme appropriée consiste à imprimer les données et leur forme jusqu'à ce que vous soyez sûr que tout fonctionne comme prévu.
Cet exemple suivant montrera ce processus. Vous allez créer un tableau avec une forme complexe, le vérifier et le réorganiser pour qu’il ressemble à ce qu’il est censé:
Dans [1]: importer engourdi comme np
Dans [2]: les températures = np.tableau([[[[
...: 29,3, 42,1, 18,8, 16,1, 38,0, 12,5,
...: 12,6, 49,9, 38,6, 31,3, 9.2, 22.2
...: ]).remodeler(2, 2, 3)
Dans [3]: les températures.forme
En dehors[3]: (2, 2, 3)
Dans [4]: les températures
En dehors[4]:
tableau ([[[29.3, 42.1, 18.8],
[16.1, 38. , 12.5]],
[[12.6, 49.9, 38.6],
[31.3, 9.2, 22.2]]])
Dans [5]: np.swapaxes(les températures, 1, 2)
En dehors[5]:
tableau ([[[29.3, 16.1],
[42.1, 38. ],
[18.8, 12.5]],
[[12.6, 31.3],
[49.9, 9.2],
[38.6, 22.2]]])
Ici, vous utilisez un numpy.ndarray méthode appelée .reshape () pour former un bloc de données 2 × 2 × 3. Lorsque vous vérifiez la forme de votre tableau dans l'entrée 3, c'est exactement ce que vous lui avez dit. Cependant, vous pouvez voir comment les tableaux imprimés deviennent rapidement difficiles à visualiser dans trois dimensions ou plus. Après avoir échangé les axes avec .swapaxes (), il devient un peu plus clair quelle dimension est quelle. Vous en verrez plus sur les axes dans la section suivante.
La forme reviendra dans la section sur la diffusion. Pour l'instant, gardez à l'esprit que ces petits chèques ne coûtent rien. Vous pouvez toujours supprimer les cellules ou vous débarrasser du code une fois que tout se passe bien.
Comprendre les axes
L'exemple ci-dessus montre à quel point il est important de savoir non seulement dans quelle forme se trouvent vos données, mais également dans quelles données axe. Dans les tableaux NumPy, les axes sont indexés à zéro et identifient quelle dimension est quelle. Par exemple, un tableau à deux dimensions a un axe vertical (axe 0) et un axe horizontal (axe 1). De nombreuses fonctions et commandes de NumPy modifient leur comportement en fonction de l'axe que vous leur dites de traiter.
Cet exemple montrera comment .max () se comporte par défaut, sans axe argument, et comment il change la fonctionnalité en fonction de axe vous spécifiez quand vous fournissez un argument:
Dans [1]: importer engourdi comme np
Dans [2]: table = np.tableau([[[[
...: [[[[5, 3, sept, 1],
...: [[[[2, 6, sept ,9],
...: [[[[1, 1, 1, 1],
...: [[[[4, 3, 2, 0],
...: ])
Dans [3]: table.max()
En dehors[3]: 9
Dans [4]: table.max(axe=0)
En dehors[4]: tableau ([5, 6, 7, 9])
Dans [5]: table.max(axe=1)
En dehors[5]: tableau ([7, 9, 1, 4])
Par défaut, .max () renvoie la plus grande valeur de tout le tableau, quel que soit le nombre de dimensions. Cependant, une fois que vous spécifiez un axe, il effectue ce calcul pour chaque ensemble de valeurs le long de cet axe particulier. Par exemple, avec un argument de axe = 0, .max () sélectionne la valeur maximale dans chacun des quatre ensembles verticaux de valeurs de table et renvoie un tableau qui a été aplati, ou agrégés dans un tableau unidimensionnel.
En fait, de nombreuses fonctions de NumPy se comportent de cette manière: si aucun axe n'est spécifié, elles effectuent une opération sur l'ensemble de données. Sinon, ils effectuent l'opération dans un dans le sens de l'axe mode.
Diffusion
Jusqu'à présent, vous avez vu quelques exemples plus petits de diffusion, mais le sujet commencera à avoir plus de sens au fur et à mesure que vous en verrez. Fondamentalement, il fonctionne autour d'une règle: les tableaux peuvent être diffusés les uns contre les autres si leurs dimensions correspondent ou si l'un des tableaux a une taille de 1.
Si les tableaux correspondent en taille le long d'un axe, alors les éléments seront exploités élément par élément, de la même manière que la fonction Python intégrée Zip *: français() travaux. Si l'un des tableaux a une taille de 1 dans un axe, alors cette valeur sera diffuser le long de cet axe, ou dupliqué autant de fois que nécessaire pour correspondre au nombre d'éléments le long de cet axe dans l'autre tableau.
Voici un exemple rapide. Tableau UNE a la forme (4, 1, 8), et tableau B a la forme (1, 6, 8). Sur la base des règles ci-dessus, vous pouvez opérer sur ces tableaux ensemble:
- Dans l'axe 0,
UNEa un4etBa un1, alorsBpeut être diffusé le long de cet axe. - Dans l'axe 1,
UNEa un 1 etBa un 6, doncUNEpeut être diffusé le long de cet axe. - Dans l'axe 2, les deux tableaux ont des tailles correspondantes, de sorte qu'ils peuvent fonctionner correctement.
Les trois axes suivent avec succès la règle.
Vous pouvez configurer les tableaux comme ceci:
Dans [1]: importer engourdi comme np
Dans [2]: UNE = np.organiser(32).remodeler(4, 1, 8)
Dans [3]: UNE
En dehors[3]:
tableau ([[[ 0, 1, 2, 3, 4, 5, 6, 7]],
[[ 8, 9, 10, 11, 12, 13, 14, 15]],
[[16, 17, 18, 19, 20, 21, 22, 23]],
[[24, 25, 26, 27, 28, 29, 30, 31]]])
Dans [4]: B = np.organiser(48).remodeler(1, 6, 8)
Dans [5]: B
En dehors[5]:
tableau ([[[ 0, 1, 2, 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 12, 13, 14, 15],
[16, 17, 18, 19, 20, 21, 22, 23],
[24, 25, 26, 27, 28, 29, 30, 31],
[32, 33, 34, 35, 36, 37, 38, 39],
[40, 41, 42, 43, 44, 45, 46, 47]]])
UNE a 4 avions, chacun avec 1 rangée et 8 Colonnes. B a seulement 1 avion avec 6 lignes et 8 Colonnes. Regardez ce que NumPy fait pour vous lorsque vous essayez de faire un calcul entre eux!
Ajoutez les deux tableaux ensemble:
Dans [7]: UNE + B
En dehors[7]:
tableau ([[[ 0, 2, 4, 6, 8, 10, 12, 14],
[ 8, 10, 12, 14, 16, 18, 20, 22],
[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54]],
[[[[[ 8, 10, 12, 14, 16, 18, 20, 22],
[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62]],
[[[[[16, 18, 20, 22, 24, 26, 28, 30],
[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62],
[56, 58, 60, 62, 64, 66, 68, 70]],
[[[[[24, 26, 28, 30, 32, 34, 36, 38],
[32, 34, 36, 38, 40, 42, 44, 46],
[40, 42, 44, 46, 48, 50, 52, 54],
[48, 50, 52, 54, 56, 58, 60, 62],
[56, 58, 60, 62, 64, 66, 68, 70],
[64, 66, 68, 70, 72, 74, 76, 78]]])
La façon dont fonctionne la diffusion est que NumPy duplique l'avion dans B trois fois pour avoir un total de quatre, correspondant au nombre d'avions dans UNE. Il duplique également la ligne unique dans UNE cinq fois pour un total de six, correspondant au nombre de lignes dans B. Ensuite, il ajoute chaque élément dans le nouveau UNE tableau à son homologue au même emplacement dans B. Le résultat de chaque calcul apparaît à l'emplacement correspondant de la sortie.
Remarque: C'est un bon moyen de créer un tableau à partir d'une plage en utilisant arange ()!
Encore une fois, même si vous pouvez utiliser des mots tels que «plan», «ligne» et «colonne» pour décrire la façon dont les formes de cet exemple sont diffusées pour créer des formes tridimensionnelles correspondantes, les choses se compliquent à des dimensions plus élevées. Souvent, vous devrez simplement suivre les règles de diffusion et faire de nombreuses impressions pour vous assurer que tout fonctionne comme prévu.
La compréhension de la diffusion est une partie importante de la maîtrise des calculs vectorisés, et les calculs vectorisés sont le moyen d'écrire un code NumPy propre et idiomatique.
Opérations de science des données: filtrer, ordonner, agréger
Cela conclut une section qui était lourde en théorie mais un peu légère sur des exemples pratiques et réels. Dans cette section, vous découvrirez quelques exemples d'opérations de science des données réelles et utiles: filtrage, tri et agrégation de données.
Indexage
L'indexation utilise plusieurs des mêmes idiomes que le code Python normal utilise. Vous pouvez utiliser des indices positifs ou négatifs pour indexer à partir de l'avant ou de l'arrière du tableau. Vous pouvez utiliser deux points (:) pour spécifier «le reste» ou «tout», et vous pouvez même utiliser deux deux points pour sauter des éléments comme avec les listes Python classiques.
Voici la différence: les tableaux NumPy utilisent des virgules entre les axes, vous pouvez donc indexer plusieurs axes dans un ensemble de crochets. Un exemple est le moyen le plus simple de montrer cela. Il est temps de confirmer le carré magique de Dürer!
Le carré numérique ci-dessous a des propriétés étonnantes. Si vous additionnez l'une des lignes, colonnes ou diagonales, vous obtiendrez le même nombre, 34. C'est également ce que vous obtiendrez si vous additionnez chacun des quatre quadrants, les quatre carrés du centre, les quatre coins carrés, ou les quatre carrés d'angle de l'une des grilles 3 × 3 contenues. Vous allez le prouver!
Fait amusant: Dans la rangée du bas, les nombres 15 et 14 sont au milieu, représentant l'année où Dürer a créé ce carré. Les chiffres 1 et 4 sont également dans cette rangée, représentant les première et quatrième lettres de l'alphabet, A et D, qui sont les initiales du créateur de la place, Albrecht Dürer!
Entrez ce qui suit dans votre REPL:
Dans [1]: importer engourdi comme np
Dans [2]: carré = np.tableau([[[[
...: [[[[16, 3, 2, 13],
...: [[[[5, dix, 11, 8],
...: [[[[9, 6, sept, 12],
...: [[[[4, 15, 14, 1]
...: ])
Dans [3]: pour je dans intervalle(4):
...: affirmer carré[:[:[:[: je].somme() == 34
...: affirmer carré[[[[je, :].somme() == 34
...:
Dans [4]: affirmer carré[:[:[:[:2, :2].somme() == 34
Dans [5]: affirmer carré[[[[2:, :2].somme() == 34
Dans [6]: affirmer carré[:[:[:[:2, 2:].somme() == 34
Dans [7]: affirmer carré[[[[2:, 2:].somme() == 34
À l'intérieur de pour boucle, vous vérifiez que toutes les lignes et toutes les colonnes totalisent 34. Après cela, en utilisant l'indexation sélective, vous vérifiez que chacun des quadrants ajoute également jusqu'à 34.
Une dernière chose à noter est que vous pouvez prendre la somme de n'importe quel tableau pour additionner tous ses éléments globalement avec square.sum (). Cette méthode peut également prendre un axe argument pour faire une somme par axe à la place.
Masquage et filtrage
La sélection basée sur un index est excellente, mais que faire si vous souhaitez filtrer vos données en fonction de critères non uniformes ou non séquentiels plus complexes? C'est là que le concept d'un masque entre en jeu.
Un masque est un tableau qui a exactement la même forme que vos données, mais au lieu de vos valeurs, il contient des valeurs booléennes: soit Vrai ou Faux. Vous pouvez utiliser ce tableau de masques pour indexer votre tableau de données de manière non linéaire et complexe. Il retournera tous les éléments où le tableau booléen a un Vrai valeur.
Voici un exemple montrant le processus, d'abord au ralenti, puis comment il est généralement effectué, le tout sur une seule ligne:
Dans [1]: importer engourdi comme np
Dans [2]: Nombres = np.linspace(5, 50, 24, dtype=int).remodeler(4, -1)
Dans [3]: Nombres
En dehors[3]:
tableau ([[ 5, 6, 8, 10, 12, 14],
[16, 18, 20, 22, 24, 26],
[28, 30, 32, 34, 36, 38],
[40, 42, 44, 46, 48, 50]])
Dans [4]: masque = Nombres % 4 == 0
Dans [5]: masque
En dehors[5]:
tableau ([[False, False, True, False, True, False],
[ True, False, True, False, True, False],
[ True, False, True, False, True, False],
[ True, False, True, False, True, False]])
Dans [6]: Nombres[[[[masque]
En dehors[6]: tableau ([ 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48])
Dans [7]: par_four = Nombres[[[[Nombres % 4 == 0]
Dans [8]: par_four
En dehors[8]: tableau ([ 8, 12, 16, 20, 24, 28, 32, 36, 40, 44, 48])
Vous verrez une explication des nouvelles astuces de création de tableau dans l'entrée 2 dans un instant, mais pour l'instant, concentrez-vous sur le cœur de l'exemple. Voici les parties importantes:
- Entrée 4 crée le masque en exécutant un calcul booléen vectorisé, en prenant chaque élément et en vérifiant s'il se divise uniformément par quatre. Cela renvoie un tableau de masque de la même forme avec les résultats élément par élément du calcul.
- Entrée 6 utilise ce masque pour indexer dans l'original
Nombrestableau. Cela fait perdre au tableau sa forme d'origine, le réduisant à une dimension, mais vous obtenez toujours les données que vous recherchez. - Entrée 7 fournit une sélection masquée idiomatique plus traditionnelle que vous pourriez voir dans la nature, avec un tableau de filtrage anonyme créé en ligne, à l'intérieur des crochets de sélection. Cette syntaxe est similaire à l'utilisation dans le langage de programmation R.
Pour en revenir à l'entrée 2, vous rencontrez trois nouveaux concepts:
- En utilisant
np.linspace ()pour générer un tableau régulièrement espacé - Réglage du
dtyped'une sortie - Remodeler un tableau avec
-1
np.linspace () génère n nombres uniformément répartis entre un minimum et un maximum, ce qui est utile pour un échantillonnage uniformément réparti dans le traçage scientifique.
En raison du calcul particulier de cet exemple, il est plus facile d'avoir des entiers dans le Nombres tableau. Mais comme l'espace entre 5 et 50 ne se divise pas uniformément par 24, les nombres résultants seraient des nombres à virgule flottante. Vous spécifiez un dtype de int pour forcer la fonction à arrondir et vous donner des entiers entiers. Vous verrez une discussion plus détaillée sur les types de données plus tard.
Finalement, array.reshape () peut prendre -1 comme l'une de ses tailles de dimension. Cela signifie que NumPy devrait simplement déterminer la taille de cet axe particulier en fonction de la taille des autres axes. Dans ce cas, avec 24 valeurs et une taille de 4 dans l'axe 0, l'axe 1 se termine par une taille de 6.
Voici un autre exemple pour montrer la puissance du filtrage masqué. La distribution normale est une distribution de probabilité dans laquelle environ 95,45% des valeurs se produisent à l'intérieur de deux écarts-types de la moyenne.
Vous pouvez le vérifier avec un peu d’aide de NumPy’s Aléatoire module de génération de valeurs aléatoires:
Dans [1]: importer engourdi comme np
Dans [2]: de numpy.random importer default_rng
Dans [3]: rng = default_rng()
Dans [4]: valeurs = rng.standard_normal(10 000)
Dans [5]: valeurs[:[:[:[:5]
En dehors[5]: tableau ([977921085818361585253-3641365235[977921085818361585253-3641365235[977921085818361585253-3641365235[977921085818361585253-3641365235
-.1311344527, 1.286542056])
Dans [6]: std = valeurs.std()
Dans [7]: std
En dehors[7]: .9940375551073492
Dans [8]: filtré = valeurs[([([([(valeurs > -2 * std) & (valeurs < 2 * std)]
Dans [9]: filtré.Taille
En dehors[9]: 9565
Dans [10]: valeurs.Taille
En dehors[10]: 10 000
Dans [11]: filtré.Taille / valeurs.Taille
En dehors[11]: 0,9565
Ici, vous utilisez une syntaxe potentiellement étrange pour combiner des conditions de filtre: a binaire & opérateur. Pourquoi serait-ce le cas? C’est parce que NumPy désigne & et | comme opérateurs vectorisés par élément pour combiner des booléens. Si vous essayez de faire A et B, alors vous recevrez un avertissement indiquant que la valeur de vérité d'un tableau est étrange, car le et fonctionne sur la valeur de vérité de l'ensemble du tableau, pas élément par élément.
Transposition, tri et concaténation
D'autres manipulations, même si elles ne sont pas aussi courantes que l'indexation ou le filtrage, peuvent également être très pratiques selon la situation dans laquelle vous vous trouvez. Vous verrez quelques exemples dans cette section.
Voici transposer un tableau:
Dans [1]: importer engourdi comme np
Dans [2]: une = np.tableau([[[[
...: [[[[1, 2],
...: [[[[3, 4],
...: [[[[5, 6],
...: ])
Dans [3]: une.T
En dehors[3]:
tableau ([[1, 3, 5],
[2, 4, 6]])
Dans [4]: une.transposer()
En dehors[4]:
tableau ([[1, 3, 5],
[2, 4, 6]])
Lorsque vous calculez la transposition d'un tableau, les indices de ligne et de colonne de chaque élément sont commutés. Article [0, 2], par exemple, devient item [2, 0]. Vous pouvez aussi utiliser à comme alias pour a.transpose ().
Le bloc de code suivant montre le tri, mais vous verrez également une technique de tri plus puissante dans la section à venir sur les données structurées:
Dans [1]: importer engourdi comme np
Dans [2]: Les données = np.tableau([[[[
...: [[[[sept, 1, 4],
...: [[[[8, 6, 5],
...: [[[[1, 2, 3]
...: ])
Dans [3]: np.Trier(Les données)
En dehors[3]:
tableau ([[1, 4, 7],
[5, 6, 8],
[1, 2, 3]])
Dans [4]: np.Trier(Les données, axe=Aucun)
En dehors[4]: tableau ([1, 1, 2, 3, 4, 5, 6, 7, 8])
Dans [5]: np.Trier(Les données, axe=0)
En dehors[5]:
tableau ([[1, 1, 3],
[7, 2, 4],
[8, 6, 5]])
Omettre le axe L'argument sélectionne automatiquement la dernière dimension la plus interne, qui correspond aux lignes de cet exemple. En utilisant Aucun aplatit le tableau et effectue un tri global. Sinon, vous pouvez spécifier l'axe de votre choix. Dans la sortie 5, chaque colonne du tableau a toujours tous ses éléments, mais ils ont été triés de bas en haut dans cette colonne.
Enfin, voici un exemple de enchaînement. Tant qu'il y a un np.concatenate () fonction, il existe également un certain nombre de fonctions d'assistance qui sont parfois plus faciles à lire.
Voici quelques exemples:
Dans [1]: importer engourdi comme np
Dans [2]: une = np.tableau([[[[
...: [[[[4, 8],
...: [[[[6, 1]
...: ])
Dans [3]: b = np.tableau([[[[
...: [[[[3, 5],
...: [[[[sept, 2],
...: ])
Dans [4]: np.hstack((une, b))
En dehors[4]:
array([[4, 8, 3, 5],
[6, 1, 7, 2]])
Dans [5]: np.vstack((b, une))
En dehors[5]:
array([[3, 5],
[7, 2],
[4, 8],
[6, 1]])
Dans [6]: np.concatenate((une, b))
En dehors[6]:
array([[[[[4, 8],
[6, 1],
[3, 5],
[7, 2]])
Dans [7]: np.concatenate((une, b), axis=None)
En dehors[7]: array([4, 8, 6, 1, 3, 5, 7, 2])
Inputs 4 and 5 show the slightly more intuitive functions hstack() et vstack(). Inputs 6 and 7 show the more generic concatenate(), first without an axis argument and then with axis=None. This flattening behavior is similar in form to what you just saw with sort().
One important stumbling block to note is that all these functions take a tuple of arrays as their first argument rather than a variable number of arguments as you might expect. You can tell because there’s an extra pair of parentheses.
Aggregating
Your last stop on this tour of functionality before diving into some more advanced topics and examples is aggregation. You’ve already seen quite a few aggregating methods, including .sum(), .max(), .mean(), and .std(). You can reference NumPy’s larger library of functions to see more. Many of the mathematical, financial, and statistical functions use aggregation to help you reduce the number of dimensions in your data.
Practical Example 1: Implementing a Maclaurin Series
Now it’s time to see a realistic use case for the skills introduced in the sections above: implementing an equation.
One of the hardest things about converting mathematical equations to code without NumPy is that many of the visual similarities are missing, which makes it hard to tell what portion of the equation you’re looking at as you read the code. Summations are converted to more verbose pour loops, and limit optimizations end up looking like while loops.
Using NumPy allows you to keep closer to a one-to-one representation from equation to code.
In this next example, you’ll encode the Maclaurin series for ex. Maclaurin series are a way of approximating more complicated functions with an infinite series of summed terms centered about zero.
Pour ex, the Maclaurin series is the following summation:

You add up terms starting at zero and going theoretically to infinity. Each nth term will be x raised to n and divided by n!, which is the notation for the factorial operation.
Now it’s time for you to put that into NumPy code. Create a file called maclaurin.py:
from math import e, factorial
import numpy as np
fac = np.vectorize(factorial)
def e_x(x, terms=dix):
"""Approximates e^x using a given number of terms of
the Maclaurin series
"""
n = np.arange(terms)
return np.sum((x ** n) / fac(n))
si __name__ == "__main__":
impression("Actual:", e ** 3) # Using e from the standard library
impression("N (terms)tMaclaurintError")
pour n dans range(1, 14):
maclaurin = e_x(3, terms=n)
impression(F"nttmaclaurin:.03ftte**3 - maclaurin:.03f")
When you run this, you should see the following result:
$ python3 maclaurin.py
Actual: 20.085536923187664
N (terms) Maclaurin Error
1 1.000 19.086
2 4.000 16.086
3 8.500 11.586
4 13.000 7.086
5 16.375 3.711
6 18.400 1.686
7 19.412 0.673
8 19.846 0.239
9 20.009 0.076
10 20.063 0.022
11 20.080 0.006
12 20.084 0.001
13 20.085 0.000
As you increase the number of terms, your Maclaurin value gets closer and closer to the actual value, and your error shrinks smaller and smaller.
The calculation of each term involves taking x to the n power and dividing by n!, or the factorial of n. Adding, summing, and raising to powers are all operations that NumPy can vectorize automatically and quickly, but not so for factorial().
To use factorial() in a vectorized calculation, you have to use np.vectorize() to create a vectorized version. The documentation for np.vectorize() states that it’s little more than a thin wrapper that applies a pour loop to a given function. There are no real performance benefits from using it instead of normal Python code, and there are potentially some overhead penalties. However, as you’ll see in a moment, the readability benefits are huge.
Once your vectorized factorial is in place, the actual code to calculate the entire Maclaurin series is shockingly short. It’s also readable. Most importantly, it’s almost exactly one-to-one with how the mathematical equation looks:
n = np.arange(terms)
return np.sum((x ** n) / fac(n))
This is such an important idea that it deserves to be repeated. With the exception of the extra line to initialize n, the code reads almost exactly the same as the original math equation. Non pour loops, no temporary i, j, k variables. Just plain, clear, math.
Just like that, you’re using NumPy for mathematical programming! For extra practice, try picking one of the other Maclaurin series and implementing it in a similar way.
Optimizing Storage: Data Types
Now that you have a bit more practical experience, it’s time to go back to theory and look at data types. Data types don’t play a central role in a lot of Python code. Numbers work like they’re supposed to, strings do other things, Booleans are true or false, and other than that, you make your own objects and collections.
In NumPy, though, there’s a little more detail that needs to be covered. NumPy uses C code under the hood to optimize performance, and it can’t do that unless all the items in an array are of the same type. That doesn’t just mean the same Python type. They have to be the same underlying C type, with the same shape and size in bits!
Numerical Types: int, bool, float, and complex
Since most of your data science and numerical calculations will tend to involve numbers, they seem like the best place to start. There are essentially four numerical types in NumPy code, and each one can take a few different sizes.
The table below breaks down the details of these types:
| Nom | # of Bits | Python Type | NumPy Type |
|---|---|---|---|
| Integer | 64 | int |
np.int_ |
| Booleans | 8 | bool |
np.bool_ |
| Float | 64 | float |
np.float_ |
| Complex | 128 | complex |
np.complex_ |
These are just the types that map to existing Python types. NumPy also has types for the smaller-sized versions of each, like 8-, 16-, and 32-bit integers, 32-bit single-precision floating-point numbers, and 64-bit single-precision complex numbers. The documentation lists them in their entirety.
To specify the type when creating an array, you can provide a dtype argument:
Dans [1]: import numpy as np
Dans [2]: une = np.array([[[[1, 3, 5.5, 7,7, 9.2], dtype=np.single)
Dans [3]: une
En dehors[3]: array([1. , 3. , 5.5, 7.7, 9.2], dtype=float32)
Dans [4]: b = np.array([[[[1, 3, 5.5, 7,7, 9.2], dtype=np.uint8)
Dans [5]: b
En dehors[5]: array([1, 3, 5, 7, 9], dtype=uint8)
NumPy automatically converts your platform-independent type np.single to whatever fixed-size type your platform supports for that size. In this case, it uses np.float32. If your provided values don’t match the shape of the dtype you provided, then NumPy will either fix it for you or raise an error.
String Types: Sized Unicode
Strings behave a little strangely in NumPy code because NumPy needs to know how many bytes to expect, which isn’t usually a factor in Python programming. Luckily, NumPy does a pretty good job at taking care of less complex cases for you:
Dans [1]: import numpy as np
Dans [2]: names = np.array([[[["bob", "amy", "han"], dtype=str)
Dans [3]: names
En dehors[3]: array(['bob', 'amy', 'han'], dtype='<U3')
Dans [4]: names.itemsize
En dehors[4]: 12
Dans [5]: names = np.array([[[["bob", "amy", "han"])
Dans [6]: names
En dehors[6]: array(['bob', 'amy', 'han'], dtype='<U3')
Dans [7]: more_names = np.array([[[["bobo", "jehosephat"])
Dans [8]: np.concatenate((names, more_names))
En dehors[8]: array(['bob', 'amy', 'han', 'bobo', 'jehosephat'], dtype='<U10')
In input 2, you provide a dtype of Python’s built-in str type, but in output 3, it’s been converted into a little-endian Unicode string of size 3. When you check the size of a given item in input 4, you see that they’re each 12 bytes: three 4-byte Unicode characters.
Remarque: When dealing with NumPy data types, you have to think about things like the endianness of your values. In this case, the dtype '<U3' means that each value is the size of three Unicode characters, with the least-significant byte stored first in memory and the most-significant byte stored last. UNE dtype of '>U3' would signify the reverse.
As an example, NumPy represents the Unicode character “🐍” with the bytes 0xF4 0x01 0x00 with a dtype of '<U1' et 0x00 0x01 0xF4 with a dtype of '>U1'. Try it out by creating an array full of emoji, setting the dtype to one or the other, and then calling .tobytes() on your array!
If you’d like to study up on how Python treats the ones and zeros of your normal Python data types, then the official documentation for the struct library, which is a standard library module that works with raw bytes, is another good resource.
When you combine that with an array that has a larger item to create a new array in input 8, NumPy helpfully figures out how big the new array’s items need to be and grows them all to size <U10.
But here’s what happens when you try to modify one of the slots with a value larger than the capacity of the dtype:
Dans [9]: names[[[[2] = "jamima"
Dans [10]: names
En dehors[10]: array(['bob', 'amy', 'jam'], dtype='<U3')
It doesn’t work as expected and truncates your value instead. If you already have an array, then NumPy’s automatic size detection won’t work for you. You get three characters and that’s it. The rest get lost in the void.
This is all to say that, in general, NumPy has your back when you’re working with strings, but you should always keep an eye on the size of your elements and make sure you have enough space when modifying or changing arrays in place.
Structured Arrays
Originally, you learned that array items all have to be the same data type, but that wasn’t entirely correct. NumPy has a special kind of array, called a record array ou structured array, with which you can specify a type and, optionally, a name on a per-column basis. This makes sorting and filtering even more powerful, and it can feel similar to working with data in Excel, CSVs, or relational databases.
Here’s a quick example to show them off a little:
Dans [1]: import numpy as np
Dans [2]: Les données = np.array([[[[
...: ("joe", 32, 6),
...: ("mary", 15, 20),
...: ("felipe", 80, 100),
...: ("beyonce", 38, 9001),
...: ], dtype=[([([([("name", str, dix), ("age", int), ("power", int)])
Dans [3]: Les données[[[[0]
En dehors[3]: ('joe', 32, 6)
Dans [4]: Les données[[[["name"]
En dehors[4]: array(['joe', 'mary', 'felipe', 'beyonce'], dtype='<U10')
Dans [5]: Les données[[[[Les données[[[["power"] > 9000][[[["name"]
En dehors[5]: array(['beyonce'], dtype='<U10')
In input 2, you create an array, except each item is a tuple with a name, an age, and a power level. For the dtype, you actually provide a list of tuples with the information about each field: name is a 10-character Unicode field, and both age et power are standard 4-byte or 8-byte integers.
In input 3, you can see that the rows, known as records, are still accessible using the index.
In input 4, you see a new syntax for accessing an entire column, or field.
Finally, in input 5, you see a super-powerful combination of mask-based filtering based on a field and field-based selection. Notice how it’s not that much different to read the following SQL query:
SELECT name FROM Les données
WHERE power > 9000;
In both cases, the result is a list of names where the power level is over 9000.
You can even add in ORDER BY functionality by making use of np.sort():
Dans [6]: np.sort(Les données[[[[Les données[[[["age"] > 20], order="power")[[[["name"]
En dehors[6]: array(['joe', 'felipe', 'beyonce'], dtype='<U10')
This sorts the data by power before retrieving it, which rounds out your selection of NumPy tools for selecting, filtering, and sorting items just like you might in SQL!
More on Data Types
This section of the tutorial was designed to get you just enough knowledge to be productive with NumPy’s data types, understand a little of how things work under the hood, and recognize some common pitfalls. It’s certainly not an exhaustive guide. The NumPy documentation on ndarrays has tons more resources.
There’s also a lot more information on dtype objects, including the different ways to construct, customize, and optimize them and how to make them more robust for all your data-handling needs. If you run into trouble and your data isn’t loading into arrays exactly how you expected, then that’s a good place to start.
Lastly, the NumPy recarray is a powerful object in its own right, and you’ve really only scratched the surface of the capabilities of structured datasets. It’s definitely worth reading through the recarray documentation as well as the documentation for the other specialized array subclasses that NumPy provides.
Looking Ahead: More Powerful Libraries
In this next section, you’ll move on to the powerhouse tools that are built on top of the foundational building blocks you saw above. Here are a few of the libraries that you’ll want to take a look at as your next steps on the road to total Python data science mastery.
pandas
pandas is a library that takes the concept of structured arrays and builds it out with tons of convenience methods, developer-experience improvements, and better automation. If you need to import data from basically anywhere, clean it, reshape it, polish it, and then export it into basically any format, then pandas is the library for you. It’s likely that at some point, you’ll import pandas as pd at the same time you import numpy as np.
The pandas documentation has a speedy tutorial filled with concrete examples called 10 Minutes to pandas. It’s a great resource that you can use to get some quick, hands-on practice.
scikit-learn
If your goals lie more in the direction of machine learning, then scikit-learn is the next step. Given enough data, you can do classification, regression, clustering, and more in just a few lines.
If you’re already comfortable with the math, then the scikit-learn documentation has a great list of tutorials to get you up and running in Python. If not, then the Math for Data Science Learning Path is a good place to start. Additionally, there’s also an entire learning path for machine learning.
It’s important for you to understand at least the basics of the mathematics behind the algorithms rather than just importing them and running with it. Bias in machine learning models is a huge ethical, social, and political issue.
Throwing data at models without a considering how to address the bias is a great way to get into trouble and negatively impact people’s lives. Doing some research and learning how to predict where bias might occur is a good start in the right direction.
Matplotlib
No matter what you’re doing with your data, at some point you’ll need to communicate your results to other humans, and Matplotlib is one of the main libraries for making that happen. For an introduction, check out Plotting with Matplotlib. In the next section, you’ll get some hands-on practice with Matplotlib, but you’ll use it for image manipulation rather than for making plots.
Practical Example 2: Manipulating Images With Matplotlib
It’s always neat when you’re working with a Python library and it hands you something that turns out to be a basic NumPy array. In this example, you’ll experience that in all its glory.
You’re going to load an image using Matplotlib, realize that RGB images are really just width × height × 3 arrays of int8 integers, manipulate those bytes, and use Matplotlib again to save that modified image once you’re done.
Download this image to work with:

It’s a picture of an adorable kitten that is 1920 pixels by 1299 pixels. You’re going to change the colors of those pixels.
Create a Python file called image_mod.py, then set up your imports and load the image:
1import numpy as np
2import matplotlib.image as mpimg
3
4img = mpimg.imread("kitty.jpg")
5impression(type(img))
6impression(img.shape)
This is a good start. Matplotlib has its own module for handling images, and you’re going to lean on that because it makes straightforward to read and write image formats.
If you run this code, then your friend the NumPy array will appear in the output:
$ python3 image_mod.py
It’s an image with a height of 1299 pixels, a width of 1920 pixels, and three channels: one each for the red, green, and blue (RGB) color levels.
Want to see what happens when you drop out the R and G channels? Add this to your script:
septoutput = img.copy() # The original image is read-only!
8output[:[:[:[: :, :2] = 0
9mpimg.imsave("blue.jpg", output)
Run it again and check the folder. There should be a new image:

Is your mind blown yet? Do you feel the power? Images are just fancy arrays! Pixels are just numbers!
But now, it’s time to do something a little more useful. You’re going to convert this image to grayscale. However, converting to grayscale is more complicated. Averaging the R, G, and B channels and making them all the same will give you an image that’s grayscale. But the human brain is weird, and that conversion doesn’t seem to handle the luminosity of the colors quite right.
In fact, it’s better to see it for yourself. You can use the fact that if you output an array with only one channel instead of three, then you can specify a color map, known as a cmap in the Matplotlib world. If you specify a cmap, then Matplotlib will handle the linear gradient calculations for you.
Get rid of the last three lines in your script and replace them with this:
septaverages = img.mean(axis=2) # Take the average of each R, G, and B
8mpimg.imsave("bad-gray.jpg", averages, cmap="gray")
These new lines create a new array called averages, which is a copy of the img array that you’ve flattened along axis 2 by taking the average of all three channels. You’ve averaged all three channels and outputted something with R, G, and B values equal to that average. When R, G, and B are all the same, the resulting color is on the grayscale.
What it ends up yielding isn’t terrible:

But you can do better using the luminosity method. This technique does a weighted average of the three channels, with the mindset that the color green drives how bright an image appears to be, and blue can make it appear darker. You’ll use the @ operator, which is NumPy’s operator for doing a traditional two-dimensional array dot product.
Replace those last two lines in your script again:
septweights = np.array([[[[0.3, 0.59, 0.11])
8niveaux de gris = img @ weights
9mpimg.imsave("good-gray.jpg", niveaux de gris, cmap="gray")
This time, instead of doing a flat average, you’re completing a dot product, which is a sort of weighted combination of the three values. Since the weights add up to one, it’s exactly equivalent to doing a weighted average of the three color channels.
Here’s the result:

The first image is a bit darker, and the edges and shadows are bolder. The second image is lighter and brighter, and the dark lines aren’t quite as bold. There you have it—you used Matplotlib and NumPy arrays to manipulate an image!
Conclusion
No matter how many dimensions your data lives in, NumPy gives you the tools to work with it. You can store it, reshape it, combine it, filter it, and sort it, and your code will read like you’re operating on only one number at a time rather than hundreds or thousands.
In this tutorial, you learned:
- le core concepts of data science made possible by NumPy
- How to create NumPy arrays using various methods
- How to manipulate NumPy arrays to perform useful calculations
- How to apply these new skills to real-world problems
Don’t forget to check out the repository of NumPy code samples from throughout this tutorial. You can use it for reference and experiment with the examples to see how changing the code changes the outcome:
Now you’re ready for the next steps in your data science journey. Whether you’re cleaning data, training neural networks, communicating using powerful plots, or aggregating data from the Internet of Things, these activities all start from the same place: the humble NumPy array.
[ad_2]