Formation Python
Pandas » Séries et Trame de données les objets sont de puissants outils d'exploration et d'analyse des données. Une partie de leur pouvoir provient d'une approche multiforme pour combiner des ensembles de données distincts. Avec Pandas, vous pouvez fusionner, joindre, et enchaîner vos ensembles de données, vous permettant d'unifier et de mieux comprendre vos données lorsque vous les analysez.
Dans ce didacticiel, vous apprendrez comment et quand combiner vos données dans Pandas avec:
fusionner()pour combiner des données sur des colonnes ou des indices communs.joindre()pour combiner des données sur une colonne clé ou un indexconcat ()pour combiner des DataFrames sur des lignes ou des colonnes
Si vous avez de l'expérience avec Trame de données et Séries objets dans Pandas et vous êtes prêt à apprendre à les combiner, alors ce didacticiel vous aidera à faire exactement cela. Si vous voulez un rafraîchissement rapide sur DataFrames avant de continuer, alors Pandas DataFrames 101 vous rattrapera en un rien de temps.
Vous pouvez suivre les exemples de ce didacticiel en utilisant le bloc-notes interactif Jupyter disponible sur le lien ci-dessous:
Remarque: Les techniques que vous découvrirez ci-dessous fonctionneront généralement pour les deux Trame de données et Séries objets. Mais pour plus de simplicité et de concision, les exemples utiliseront le terme base de données pour faire référence à des objets qui peuvent être DataFrames ou Series.
Pandas fusionner(): Combinaison de données sur des colonnes ou des indices communs
La première technique que vous apprendrez est fusionner(). Vous pouvez utiliser fusionner() chaque fois que vous souhaitez effectuer des opérations de jointure de type base de données. C'est la plus flexible des trois opérations que vous apprendrez.
Lorsque vous souhaitez combiner des objets de données basés sur une ou plusieurs clés de manière similaire à une base de données relationnelle, fusionner() est l'outil dont vous avez besoin. Plus précisement, fusionner() est plus utile lorsque vous souhaitez combiner des lignes qui partagent des données.
Vous pouvez réaliser les deux plusieurs à un et plusieurs à plusieurs se joint à fusionner(). Dans une jointure plusieurs-à-un, l'un de vos jeux de données aura plusieurs lignes dans la colonne de fusion qui répètent les mêmes valeurs (telles que 1, 1, 3, 5, 5), tandis que la colonne de fusion dans l'autre jeu de données ne sera pas ont des valeurs de répétition (telles que 1, 3, 5).
Comme vous l'avez peut-être deviné, dans une jointure plusieurs-à-plusieurs, vos deux colonnes de fusion auront des valeurs de répétition. Ces fusions sont plus complexes et donnent le produit cartésien des lignes jointes.
Cela signifie qu'après la fusion, vous aurez toutes les combinaisons de lignes qui partagent la même valeur dans la colonne clé. Vous le verrez en action dans les exemples ci-dessous.
Ce qui rend fusionner() le nombre d'options pour définir le comportement de votre fusion est si flexible. Bien que la liste puisse sembler intimidante, avec la pratique, vous pourrez fusionner de manière experte des ensembles de données de toutes sortes.
Lorsque vous utilisez fusionner(), vous fournirez deux arguments obligatoires:
- le
la gaucheTrame de données - le
droiteTrame de données
Après cela, vous pouvez fournir un certain nombre d'arguments facultatifs pour définir la manière dont vos ensembles de données sont fusionnés:
-
Comment: Ceci définit le type de fusion à effectuer. Par défaut,'interne', mais d'autres options possibles incluent'extérieur','la gauche', et'droite'. -
sur: Utilisez ceci pour direfusionner()quelles colonnes ou indices (également appelés colonnes clés ou indices clés) que vous souhaitez rejoindre. C'est facultatif. S'il n'est pas spécifié, etleft_indexetright_index(couvert ci-dessous) sontFaux, puis les colonnes des deux DataFrames qui partagent des noms seront utilisées comme clés de jointure. Si tu utilisessur, la colonne ou l'index que vous spécifiez doit être présent dans les deux objets. -
à gauche suretright_on: Utilisez l'une de ces options pour spécifier une colonne ou un index qui n'est présent que dans lela gaucheoudroiteles objets que vous fusionnez. Les deux valeurs par défaut sontAucun. -
left_indexetright_index: Définissez-les surVraipour utiliser l'index des objets gauche ou droit à fusionner. Les deux valeurs par défaut sontFaux. -
suffixes: Il s'agit d'un tuple de chaînes à ajouter à des noms de colonnes identiques qui ne sont pas des clés de fusion. Cela vous permet de garder une trace des origines des colonnes du même nom.
Ce sont quelques-uns des paramètres les plus importants à transmettre à fusionner(). Pour la liste complète, consultez la documentation Pandas.
Remarque: Dans ce didacticiel, vous verrez que les exemples spécifient toujours la ou les colonnes à joindre sur. C'est le moyen le plus sûr de fusionner vos données car vous et toute personne lisant votre code saurez exactement à quoi vous attendre quand fusionner() est appelé. Si vous ne spécifiez pas la ou les colonnes de fusion avec sur, alors Pandas utilisera toutes les colonnes du même nom que les clés de fusion.
Comment fusionner()
Avant d'entrer dans les détails de l'utilisation fusionner(), vous devez d'abord comprendre les différentes formes de jointures:
Remarque: Même si vous apprenez à fusionner, vous verrez interne, extérieur, la gauche, et droite également appelé opérations de jointure. Pour ce didacticiel, vous pouvez considérer ces termes comme équivalents.
Vous en apprendrez plus en détail ci-dessous, mais jetez d'abord un œil à cette représentation visuelle des différentes jointures:

Dans cette image, les deux cercles sont vos deux jeux de données et les étiquettes indiquent la ou les parties des jeux de données que vous pouvez vous attendre à voir. Bien que ce diagramme ne couvre pas toutes les nuances, il peut être un guide pratique pour les apprenants visuels.
Si vous avez un arrière-plan SQL, vous pouvez reconnaître les noms des opérations de fusion à partir du JOINDRE syntaxe. À l'exception de interne, toutes ces techniques sont des types de jointures externes. Avec les jointures externes, vous fusionnerez vos données en fonction de toutes les clés de l'objet gauche, de l'objet droit ou des deux. Pour les clés qui n'existent que dans un objet, les colonnes sans correspondance dans l'autre objet seront remplies avec NaN (Pas un nombre).
Vous pouvez également voir une explication visuelle des différentes jointures dans un contexte SQL sur Coding Horror. Voyons maintenant les différentes jointures en action.
Exemples
De nombreux didacticiels Pandas fournissent des DataFrames très simples pour illustrer les concepts qu'ils tentent d'expliquer. Cette approche peut prêter à confusion car vous ne pouvez pas associer les données à quelque chose de concret. Donc, pour ce didacticiel, vous allez utiliser deux jeux de données du monde réel comme DataFrames à fusionner:
- Normales climatiques pour la Californie (températures)
- Normales climatiques pour la Californie (précipitations)
Vous pouvez explorer ces ensembles de données et suivre les exemples ci-dessous en utilisant le bloc-notes interactif Jupyter:
Si vous souhaitez apprendre à utiliser les blocs-notes Jupyter, consultez Jupyter Notebook: An Introduction.
Ces deux ensembles de données proviennent de la National Oceanic and Atmospheric Administration (NOAA) et ont été dérivés du référentiel de données publiques de la NOAA. Tout d'abord, chargez les jeux de données dans des DataFrames distincts:
>>> importation pandas comme pd
>>> climat_temp = pd.read_csv("climate_temp.csv")
>>> Climate_precip = pd.read_csv("climate_precip.csv")
Dans le code ci-dessus, vous avez utilisé les Pandas " read_csv () pour charger facilement vos fichiers CSV source dans Trame de données objets. Vous pouvez ensuite consulter les en-têtes et les premières lignes des DataFrames chargés avec .tête():
>>> climat_temp.tête()
STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL
0 GHCND: USC00049099 TWENTYNINE PALMS CA US ... 10 15
1 GHCND: USC00049099 TWENTYNINE PALMS CA US ... 10 15
2 GHCND: USC00049099 TWENTYNINE PALMS CA US ... 10 15
3 GHCND: USC00049099 TWENTYNINE PALMS CA US ... 10 15
4 GHCND: USC00049099 TWENTYNINE PALMS CA US ... 10 15
>>> Climate_precip.tête()
STATION ... DLY-SNOW-PCTALL-GE050TI
0 GHCND: USC00049099 ... -9999
1 GHCND: USC00049099 ... -9999
2 GHCND: USC00049099 ... -9999
3 GHCND: USC00049099 ... 0
4 GHCND: USC00049099 ... 0
Ici, vous avez utilisé .tête() pour obtenir les cinq premières lignes de chaque DataFrame. Assurez-vous d'essayer par vous-même, soit avec le bloc-notes interactif Jupyter ou dans votre console, afin de pouvoir explorer les données plus en profondeur.
Ensuite, jetez un coup d'œil aux dimensions des deux DataFrames:
>>> climat_temp.forme
(127020, 21)
>>> Climate_precip.forme
(151110, 29)
Notez que .forme est une propriété de Trame de données objets qui vous indiquent les dimensions du DataFrame. Pour climat_temp, la sortie de .forme dit que le DataFrame a 127 020 lignes et 21 colonnes.
Jointure interne
Dans cet exemple, vous utiliserez fusionner() avec ses arguments par défaut, ce qui entraînera une jointure interne. N'oubliez pas que dans une jointure interne, vous perdrez des lignes qui n'ont pas de correspondance dans les autres DataFrame colonne clé.
Avec les deux jeux de données chargés dans Trame de données objets, vous allez sélectionner une petite tranche du jeu de données de précipitations, puis utiliser une plaine fusionner() appel à faire une jointure intérieure. Cela se traduira par un ensemble de données plus petit et plus ciblé:
>>> précip_one_station = Climate_precip[[[[Climate_precip[[[["GARE"] == "GHCND: USC00045721"]
>>> précip_one_station.tête()
STATION ... DLY-SNOW-PCTALL-GE050TI
1460 GHCND: USC00045721 ... -9999
1461 GHCND: USC00045721 ... -9999
1462 GHCND: USC00045721 ... -9999
1463 GHCND: USC00045721 ... -9999
1464 GHCND: USC00045721 ... -9999
Ici, vous avez créé un nouveau DataFrame appelé précip_one_station du Climate_precip DataFrame, en sélectionnant uniquement les lignes dans lesquelles GARE le champ est "GHCND: USC00045721".
Si vous cochez la forme attribut, vous verrez qu'il contient 365 lignes. Lorsque vous effectuez la fusion, combien de lignes pensez-vous que vous obtiendrez dans le DataFrame fusionné? N'oubliez pas que vous allez effectuer une jointure interne:
>>> fusion_interne = pd.fusionner(précip_one_station, climat_temp)
>>> fusion_interne.tête()
STATION STATION_NAME ... DLY-HTDD-BASE60 DLY-HTDD-NORMAL
0 GHCND: USC00045721 MITCHELL CAVERNS CA US ... 14 19
1 GHCND: USC00045721 MITCHELL CAVERNS CA US ... 14 19
2 GHCND: USC00045721 MITCHELL CAVERNS CA US ... 14 19
3 GHCND: USC00045721 MITCHELL CAVERNS CA US ... 14 19
4 GHCND: USC00045721 MITCHELL CAVERNS CA US ... 14 19
>>> fusion_interne.forme
(365, 47)
Si vous avez deviné 365 lignes, alors vous aviez raison! Ceci est dû au fait fusionner() par défaut, une jointure interne, et une jointure interne supprimera uniquement les lignes qui ne correspondent pas. Étant donné que toutes vos lignes ont une correspondance, aucune n'a été perdue. Vous devriez également remarquer qu'il y a maintenant beaucoup plus de colonnes: 47 pour être exact.
Avec fusionner(), vous avez également le contrôle sur la ou les colonnes à joindre. Supposons que vous souhaitiez fusionner les deux ensembles de données entiers, mais uniquement sur Gare et Date car la combinaison des deux donnera une valeur unique pour chaque ligne. Pour ce faire, vous pouvez utiliser le sur paramètre:
inner_merged_total = pd.fusionner(climat_temp, Climate_precip, sur=[[[["GARE", "DATE"])
inner_merged_total.tête()
inner_merged_total.forme
Vous pouvez spécifier une seule colonne clé avec une chaîne ou plusieurs colonnes clés avec une liste. Il en résulte un DataFrame avec 123 005 lignes et 48 colonnes.
Pourquoi 48 colonnes au lieu de 47? Étant donné que vous avez spécifié les colonnes clés à joindre, Pandas n'essaie pas de fusionner toutes les colonnes fusionnables. Cela peut entraîner des noms de colonne «en double», qui peuvent ou non avoir des valeurs différentes.
«Dupliquer» est entre guillemets car les noms de colonne ne seront pas une correspondance exacte. Par défaut, ils sont ajoutés avec _X et _y. Vous pouvez également utiliser le suffixes pour contrôler ce qui est ajouté aux noms de colonne.
Pour éviter les surprises, tous les exemples suivants utiliseront le sur pour spécifier la ou les colonnes sur lesquelles se joindre.
Jointure externe
Ici, vous allez spécifier une jointure externe avec le Comment paramètre. Rappelez-vous des diagrammes ci-dessus que dans une jointure externe (également connue sous le nom de jointure externe complète), toutes les lignes des deux DataFrames seront présentes dans le nouveau DataFrame.
Si une ligne n'a pas de correspondance dans l'autre DataFrame (basé sur la colonne clé[s]), vous ne perdrez pas la ligne comme vous le feriez avec une jointure interne. Au lieu de cela, la ligne sera dans le DataFrame fusionné avec NaN valeurs remplies le cas échéant.
Ceci est mieux illustré dans un exemple:
external_merged = pd.fusionner(précip_one_station, climat_temp, Comment="extérieur", sur=[[[["GARE", "DATE"])
external_merged.tête()
external_merged.forme
Si vous vous souvenez de quand vous avez coché la case .forme attribut de climat_temp, alors vous verrez que le nombre de lignes dans external_merged est le même. Avec une jointure externe, vous pouvez vous attendre à avoir le même nombre de lignes que le DataFrame plus grand. En effet, aucune ligne n'est perdue dans une jointure externe, même lorsqu'elles n'ont pas de correspondance dans l'autre DataFrame.
Joint gauche
Dans cet exemple, vous allez spécifier une jointure gauche, également appelée jointure externe gauche-avec le Comment paramètre. L'utilisation d'une jointure externe gauche laissera votre nouveau DataFrame fusionné avec toutes les lignes du DataFrame gauche, tout en supprimant les lignes du DataFrame droit qui n'ont pas de correspondance dans la colonne clé du DataFrame gauche.
Vous pouvez penser à cela comme une fusion mi-extérieure, mi-intérieure. L'exemple ci-dessous vous montre ceci en action:
left_merged = pd.fusionner(climat_temp, précip_one_station,
Comment="la gauche", sur=[[[["GARE", "DATE"])
left_merged.tête()
left_merged.forme
left_merged a 127 020 lignes, correspondant au nombre de lignes dans le DataFrame de gauche, climat_temp. Pour prouver que cela ne vaut que pour le DataFrame gauche, exécutez le même code, mais changez la position de précip_one_station et climat_temp:
left_merged_reversed = pd.fusionner(précip_one_station, climat_temp, Comment="la gauche", sur=[[[["GARE", "DATE"])
left_merged_reversed.tête()
left_merged_reversed.forme
Il en résulte un DataFrame avec 365 lignes, correspondant au nombre de lignes dans précip_one_station.
Jointure droite
La bonne jointure (ou jointure externe droite) est la version miroir de la jointure gauche. Avec cette jointure, toutes les lignes du DataFrame droit seront conservées, tandis que les lignes du DataFrame gauche sans correspondance dans la colonne clé du DataFrame droit seront supprimées.
Pour montrer comment les jointures droite et gauche sont des images miroir l'une de l'autre, dans l'exemple ci-dessous, vous allez recréer le left_merged DataFrame d'en haut, mais cette fois en utilisant une jointure droite:
fusionné à droite = pd.fusionner(précip_one_station, climat_temp, Comment="droite", sur=[[[["GARE", "DATE"])
fusionné à droite.tête()
fusionné à droite.forme
Ici, vous avez simplement inversé les positions des DataFrames d'entrée et spécifié une jointure droite. Lorsque vous inspectez fusionné à droite, vous remarquerez peut-être que ce n'est pas exactement la même chose que left_merged. La seule différence entre les deux est l'ordre des colonnes: les premières colonnes de l'entrée seront toujours les premières du DataFrame nouvellement formé.
fusionner() est le plus complexe des outils de combinaison de données Pandas. C’est aussi la base sur laquelle les autres outils sont construits. Sa complexité est sa plus grande force, vous permettant de combiner des ensembles de données dans tous les sens et de générer de nouvelles perspectives sur vos données.
En revanche, cette complexité fait que fusionner() difficile à utiliser sans une compréhension intuitive de la théorie des ensembles et des opérations de base de données. Dans cette section, vous avez appris les différentes techniques de fusion de données, ainsi que les fusions plusieurs-à-un et plusieurs-à-plusieurs, qui découlent finalement de la théorie des ensembles. Pour plus d'informations sur la théorie des ensembles, consultez Ensembles en Python.
Maintenant, vous allez regarder une version simplifiée de fusionner(): .joindre().
Pandas .joindre(): Combinaison de données sur une colonne ou un index
Tandis que fusionner() est un fonction du module, .joindre() est un fonction d'objet qui vit sur votre DataFrame. Cela vous permet de spécifier un seul DataFrame, qui rejoindra le DataFrame que vous appelez .joindre() sur.
Sous la capuche, .joindre() les usages fusionner(), mais il fournit un moyen plus efficace de joindre des DataFrames qu’un fusionner() appel. Avant de plonger dans les options qui s'offrent à vous, jetez un œil à ce petit exemple:
précip_one_station.joindre(climat_temp, lsuffix="_la gauche", rsuffix="_droite")
Avec les indices visibles, vous pouvez voir une jointure gauche se produire ici, avec précip_one_station étant le DataFrame gauche. Vous remarquerez peut-être que cet exemple fournit les paramètres lsuffix et rsuffix. Parce que .joindre() rejoint les index et ne fusionne pas directement les DataFrames, toutes les colonnes, même celles avec des noms correspondants, sont conservées dans le DataFrame résultant.
Si vous retournez l'exemple précédent et appelez à la place .joindre() sur le plus grand DataFrame, vous remarquerez que le DataFrame est plus grand, mais les données qui n'existent pas dans le plus petit DataFrame (précip_one_station) est rempli de NaN valeurs:
climat_temp.joindre(précip_one_station, lsuffix="_la gauche", rsuffix="_droite")
Comment .joindre()
Par défaut, .joindre() tentera de faire une jointure gauche sur les indices. Si vous souhaitez rejoindre des colonnes comme vous le feriez avec fusionner(), vous devrez alors définir les colonnes comme des indices.
Comme fusionner(), .joindre() a quelques paramètres qui vous donnent plus de flexibilité dans vos jointures. Cependant, avec .joindre(), la liste des paramètres est relativement courte:
-
autre: C'est le seul paramètre requis. Il définit les autres DataFrame à joindre. Vous pouvez également spécifier une liste de DataFrames ici, vous permettant de combiner un certain nombre de jeux de données en un seul.joindre()appel. -
sur: Ce paramètre spécifie un nom de colonne ou d'index facultatif pour le DataFrame gauche (climat_tempdans l'exemple précédent) pour rejoindre leautreIndex de DataFrame. S'il est défini surAucun, qui est la valeur par défaut, alors la jointure sera index sur index. -
Comment: Cela a les mêmes options queCommentdefusionner(). La différence est qu'il est basé sur un index, sauf si vous spécifiez également des colonnes avecsur. -
lsuffixetrsuffix: Ils sont similaires àsuffixesdansfusionner(). Ils spécifient un suffixe à ajouter aux colonnes qui se chevauchent, mais n'ont aucun effet lors du passage d'une liste deautreDataFrames. -
Trier: Activez cette option pour trier le DataFrame résultant par la clé de jointure.
Exemples
Dans cette section, vous verrez des exemples montrant quelques cas d'utilisation différents pour .joindre(). Certains seront des simplifications de fusionner() appels. D'autres seront des fonctionnalités qui définissent .joindre() en dehors des plus verbeux fusionner() appels.
Puisque vous avez déjà vu un court .joindre() appel, dans ce premier exemple, vous tenterez de recréer un fusionner() appeler avec .joindre(). Qu'est-ce que cela exigera? Prenez une seconde pour réfléchir à une solution possible, puis examinez la solution proposée ci-dessous:
inner_merged_total = pd.fusionner(climat_temp, Climate_precip, sur=[[[["GARE", "DATE"])
inner_merged_total.tête()
inner_joined_total = climat_temp.joindre(
Climate_precip.set_index([[[["GARE", "DATE"]),
lsuffix="_X",
rsuffix="_y",
sur=[[[["GARE", "DATE"],
)
inner_joined_total.tête()
Parce que .joindre() fonctionne sur les indices, si nous voulons recréer fusionner() d'avant, alors nous devons définir des indices sur les colonnes de jointure que nous spécifions. Dans cet exemple, vous avez utilisé .set_index () pour définir vos index sur les colonnes clés de la jointure.
Avec cela, le lien entre fusionner() et .joindre() devrait être plus clair.
Ci-dessous, vous verrez un .joindre() appel. Parce qu'il y a des colonnes qui se chevauchent, vous devrez spécifier un suffixe avec lsuffix, rsuffix, ou les deux, mais cet exemple montrera le comportement le plus typique de .joindre():
climat_temp.joindre(Climate_precip, lsuffix="_la gauche")
Cet exemple devrait rappeler ce que vous avez vu dans l'introduction de .joindre() plus tôt. L'appel est le même, ce qui entraîne une jointure gauche qui produit un DataFrame avec le même nombre de lignes que cliamte_temp.
Dans cette section, vous avez appris .joindre() et ses paramètres et utilisations. Vous avez également appris comment .joindre() travaille sous le capot et recrée un fusionner() appeler avec .joindre() pour mieux comprendre le lien entre les deux techniques.
Pandas concat (): Combinaison de données sur des lignes ou des colonnes
La concaténation est un peu différente des techniques de fusion que vous avez vues ci-dessus. Avec la fusion, vous pouvez vous attendre à ce que l'ensemble de données résultant ait des lignes des ensembles de données parents mélangées ensemble, souvent en fonction d'une certaine similitude. Selon le type de fusion, vous risquez également de perdre des lignes qui ne correspondent pas dans l'autre ensemble de données.
Avec la concaténation, vos jeux de données sont simplement assemblés le long d'un axe – soit le axe de ligne ou axe de colonne. Visuellement, une concaténation sans paramètres le long des lignes ressemblerait à ceci:
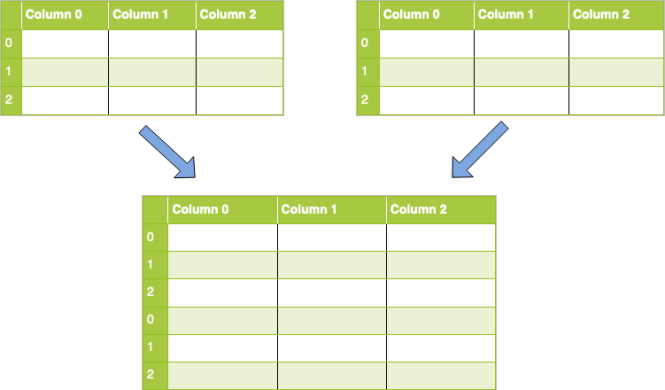
Pour implémenter cela dans le code, vous utiliserez concat () et lui passer une liste de DataFrames que vous souhaitez concaténer. Le code pour cette tâche aimerait ceci:
concaténé = pandas.concat([[[[df1, df2])
Remarque: Cet exemple suppose que les noms de vos colonnes sont identiques. Si les noms de vos colonnes sont différents lors de la concaténation le long des lignes (axe 0), par défaut, les colonnes seront également ajoutées, et NaN les valeurs seront remplies le cas échéant.
Et si à la place vous vouliez effectuer une concaténation le long des colonnes? Tout d'abord, jetez un œil à une représentation visuelle de cette opération:
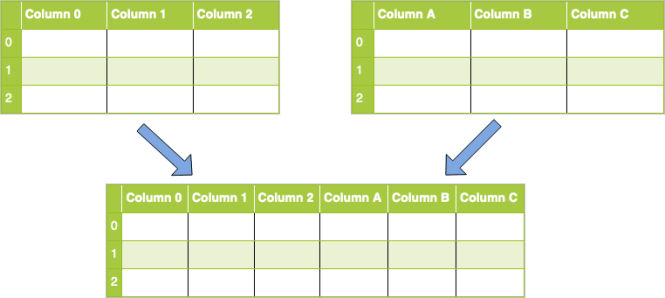
Pour ce faire, vous utiliserez un concat () appelez comme vous l'avez fait ci-dessus, mais vous devrez également passer axe paramètre avec une valeur de 1:
concaténé = pandas.concat([[[[df1, df2], axe=1)
Remarque: Cet exemple suppose que vos indices sont les mêmes entre les jeux de données. S'ils sont différents lors de la concaténation le long des colonnes (axe 1), par défaut, les indices supplémentaires (lignes) seront également ajoutés, et NaN les valeurs seront remplies le cas échéant.
Vous en apprendrez plus sur les paramètres de concat () dans la section ci-dessous. Comme vous pouvez le voir, la concaténation est un moyen plus simple de combiner des jeux de données. Il est souvent utilisé pour former un seul ensemble plus grand sur lequel effectuer des opérations supplémentaires.
Remarque: Quand vous appelez concat (), une copie de toutes les données que vous concaténez est effectuée. Vous devez être prudent avec plusieurs concat () appels, car les nombreuses copies effectuées peuvent affecter négativement les performances. Vous pouvez également définir l'option copie paramètre à Faux
Lorsque vous concaténez des jeux de données, vous pouvez spécifier l'axe le long duquel vous concaténerez. Mais que se passe-t-il avec l'autre axe?
Rien. Par défaut, une concaténation entraîne un définir l'union, où toutes les données sont conservées. Vous l'avez vu avec fusionner() et .joindre() comme jointure externe, et vous pouvez le spécifier avec le joindre paramètre.
Si vous utilisez ce paramètre, vos options sont extérieur (par défaut) et interne, qui effectuera une jointure interne (ou définir l'intersection).
Comme avec les autres jointures internes que vous avez vues précédemment, une perte de données peut se produire lorsque vous effectuez une jointure interne avec concat (). C'est uniquement là où les étiquettes d'axe correspondent que vous préserverez les lignes ou les colonnes.
Remarque: Se souvenir du joindre paramètre spécifie uniquement comment gérer les axes que vous êtes ne pas concaténer le long.
Depuis que vous avez appris joindre paramètre, voici quelques-uns des autres paramètres qui concat () prend:
-
objs: Ce paramètre prend n'importe quelle séquence (généralement une liste) deSériesouTrame de donnéesobjets à concaténer. Vous pouvez également fournir un dictionnaire. Dans ce cas, les clés seront utilisées pour construire un index hiérarchique. -
axe: Comme dans les autres techniques, cela représente l'axe que vous concaténerez le long. La valeur par défaut est0, qui concatène le long de l'index (ou de l'axe des lignes), tandis que1concatène le long des colonnes (verticalement). Vous pouvez également utiliser les valeurs de chaîneindiceouColonnes. -
joindre: Ceci est similaire auCommentdans les autres techniques, mais il n'accepte que les valeursinterneouextérieur. La valeur par défaut estextérieur, qui préserve les données, tout eninterneéliminerait les données qui n'ont pas de correspondance dans l'autre ensemble de données. -
ignore_index: Ce paramètre prend un booléen (VraiouFaux) et par défautFaux. SiVrai, le nouvel ensemble de données combiné ne conservera pas les valeurs d'index d'origine dans l'axe spécifié dans leaxeparamètre. Cela vous permet d'avoir des valeurs d'index entièrement nouvelles. -
clés: Ce paramètre vous permet de construire un index hiérarchique. Un cas d'utilisation courant consiste à avoir un nouvel index tout en préservant les index d'origine afin que vous puissiez savoir quelles lignes, par exemple, proviennent de quel jeu de données d'origine. -
copie: Ce paramètre spécifie si vous souhaitez copier les données source. La valeur par défaut estVrai. Si la valeur est définie surFaux, alors les Pandas ne feront pas de copies des données source.
Cette liste n'est pas exhaustive. Vous pouvez trouver la liste complète et à jour des paramètres dans la documentation Pandas.
Comment ajouter à un DataFrame avec ajouter()
Avant d'entrer dans concat () exemples, vous devez connaître .ajouter(). Ceci est un raccourci vers concat () qui fournit une interface plus simple et plus restrictive pour la concaténation. Vous pouvez utiliser .ajouter() à la fois Séries et Trame de données objets, et les deux fonctionnent de la même manière.
Utiliser .ajouter(), vous l'appelez sur l'un des ensembles de données dont vous disposez et passez l'autre ensemble de données (ou une liste d'ensembles de données) comme argument à la méthode:
concaténé = df1.ajouter(df2)
Vous avez fait la même chose ici que lorsque vous avez appelé pandas.concat ([df1, df2]), sauf que vous avez utilisé la méthode d'instance .ajouter() au lieu de la méthode du module concat ().
Exemples
Tout d'abord, vous effectuerez une concaténation de base le long de l'axe par défaut à l'aide des DataFrames avec lesquels vous avez joué tout au long de ce didacticiel:
double_precip = pd.concat([[[[précip_one_station, précip_one_station])
Celui-ci est très simple de par sa conception. Ici, vous avez créé un DataFrame qui est le double d'un petit DataFrame créé précédemment. Une chose à noter est que les indices se répètent. Si vous voulez un nouvel index basé sur 0, vous pouvez utiliser le ignore_index paramètre:
réindexé = pd.concat([[[[précip_one_station, précip_one_station], ignore_index=Vrai)
Comme indiqué précédemment, si vous concaténez le long de l'axe 0 (lignes) mais que les étiquettes de l'axe 1 (colonnes) ne correspondent pas, celles-ci seront ajoutées et remplies avec NaN valeurs. Il en résulte une jointure externe:
jointure_externe = pd.concat([[[[Climate_precip, climat_temp])
Avec ces deux DataFrames, comme vous ne faites que concaténer le long des lignes, très peu de colonnes portent le même nom. Cela signifie que vous verrez beaucoup de colonnes avec NaN valeurs.
Pour supprimer à la place les colonnes contenant des données manquantes, utilisez le joindre paramètre avec la valeur "interne" pour faire une jointure interne:
inner_joined = pd.concat([[[[climat_temp, Climate_precip], joindre="interne")
En utilisant la jointure interne, il ne vous restera que les colonnes communes aux DataFrames d'origine: GARE, NOM DE LA STATION, et DATE.
Vous pouvez également inverser cela en définissant axe paramètre:
inner_joined_cols = pd.concat([[[[climat_temp, Climate_precip], axe=1, joindre="interne")
Vous n'avez maintenant que les lignes contenant des données pour toutes les colonnes des deux DataFrames. Ce n'est pas un hasard si le nombre de lignes correspond à celui du plus petit DataFrame.
Une autre astuce utile pour la concaténation consiste à utiliser clés pour créer des étiquettes d'axe hiérarchiques. Ceci est utile si vous souhaitez conserver les indices ou les noms de colonnes des jeux de données d'origine mais également en avoir de nouveaux d'un niveau supérieur:
hierarchical_keys = pd.concat([[[[climat_temp, Climate_precip], clés=[[[["temp", "précip"])
Si vous vérifiez les DataFrames d'origine, vous pouvez vérifier si les étiquettes d'axe de niveau supérieur temp et précip ont été ajoutés aux lignes appropriées.
Enfin, jetez un œil au premier exemple de concaténation réécrit pour utiliser .ajouter():
en annexe = précip_one_station.ajouter(précip_one_station)
Notez que le résultat de l'utilisation .ajouter() est le même que lorsque vous avez utilisé concat () au début de cette section.
Conclusion
Vous avez maintenant appris les trois techniques les plus importantes pour combiner des données dans Pandas:
fusionner()pour combiner des données sur des colonnes ou des indices communs.joindre()pour combiner des données sur une colonne clé ou un indexconcat ()pour combiner des DataFrames sur des lignes ou des colonnes
En plus d'apprendre à utiliser ces techniques, vous avez également appris la logique des ensembles en expérimentant les différentes façons de joindre vos ensembles de données. Vous avez également découvert les API des techniques ci-dessus et certains appels alternatifs comme .ajouter() que vous pouvez utiliser pour simplifier votre code.
Vous avez vu ces techniques en action sur un véritable ensemble de données obtenu auprès de la NOAA, qui vous a montré non seulement comment combiner vos données, mais aussi les avantages de le faire avec les techniques intégrées de Pandas. Si vous n'avez pas encore téléchargé les fichiers du projet, vous pouvez les obtenir ici:
As tu appris quelque chose de nouveau? Trouver une façon créative de résoudre un problème en combinant des ensembles de données complexes? Faites-le nous savoir dans les commentaires ci-dessous!
[ad_2]