Formation gratuite Python
La quantité incroyable de données sur Internet constitue une ressource précieuse pour tous les domaines de recherche ou d’intérêt personnel. Pour exploiter efficacement ces données, vous devez acquérir les compétences nécessaires Web scraping. Les librairies Python demandes et Beautiful Soup sont des outils puissants pour le travail. Si vous aimez apprendre à l'aide d'exemples pratiques et que vous maîtrisez les langages Python et HTML, ce didacticiel est pour vous.
Dans ce tutoriel, vous allez apprendre à:
- Utilisation
demandeset belle soupe pour grattage et analyse des données du web - Traverser un pipeline de raclage Web du début à la fin
- Construire un script qui récupère les offres d'emploi sur le Web et affiche les informations pertinentes dans votre console
Il s’agit d’un projet puissant, car vous pourrez appliquer le même processus et les mêmes outils à n’importe quel site Web statique existant sur le World Wide Web. Vous pouvez télécharger le code source du projet et tous les exemples de ce tutoriel en cliquant sur le lien ci-dessous:
Commençons!
Qu'est-ce que le Web Scraping?
Web raclage est le processus de collecte d'informations à partir d'Internet. Même copier-coller les paroles de votre chanson préférée est une forme de raclage Web! Cependant, les mots «Web scraping» font généralement référence à un processus impliquant une automatisation. Certains sites Web n’aiment pas que les racleurs automatiques collectent leurs données, alors que d’autres ne le font pas.
Si vous grattez une page avec respect à des fins éducatives, vous ne rencontrerez probablement aucun problème. Néanmoins, c’est une bonne idée de faire des recherches par vous-même et de vous assurer que vous ne violez pas les Conditions de service avant de commencer un projet à grande échelle. Pour en savoir plus sur les aspects juridiques du raclage Web, consultez Perspectives juridiques sur le raclage des données du Web moderne.
Pourquoi gratter le Web?
Dites que vous êtes un surfeur (à la fois en ligne et dans la vie réelle) et que vous recherchez un emploi. Cependant, vous ne cherchez pas seulement tout emploi. Dans l’esprit des internautes, vous attendez l’occasion idéale de rouler votre chemin!
Vous aimez un site d'emploi qui offre exactement le type d'emploi que vous recherchez. Malheureusement, une nouvelle position n'apparaît qu'une fois dans une lune bleue. Vous pensez vérifier chaque jour, mais cela ne semble pas être la façon la plus amusante et la plus productive de passer votre temps.
Heureusement, le monde offre d’autres manières d’appliquer l’esprit de ce surfeur! Au lieu de regarder le site tous les jours, vous pouvez utiliser Python pour aider à automatiser les parties répétitives de votre recherche d’emploi. Raclage Web automatisé peut être une solution pour accélérer le processus de collecte de données. Vous écrivez votre code une fois et il obtiendra les informations que vous souhaitez plusieurs fois et à partir de plusieurs pages.
En revanche, lorsque vous essayez d’obtenir manuellement les informations souhaitées, vous pouvez passer beaucoup de temps à cliquer, faire défiler et rechercher. Cela est particulièrement vrai si vous avez besoin de grandes quantités de données de sites Web régulièrement mis à jour avec du nouveau contenu. Le râpage manuel peut prendre beaucoup de temps et se répéter.
Il y a tellement d’informations sur le Web et de nouvelles informations sont constamment ajoutées. Quelque chose parmi toutes ces données est susceptible de vous intéresser, et une grande partie est simplement destinée à la prise. Que vous recherchiez un emploi, que vous rassembliez des données pour soutenir votre organisation locale ou que vous vouliez enfin télécharger toutes les paroles de votre artiste préféré sur votre ordinateur, la récupération automatique du Web peut vous aider à atteindre vos objectifs.
Défis de la Web Scraping
Le Web s'est développé de manière organique à partir de nombreuses sources. Il combine une tonne de technologies, de styles et de personnalités différents et continue de croître à ce jour. En d'autres termes, le Web est une sorte de désordre chaud! Cela peut entraîner quelques difficultés que vous verrez lorsque vous essayez de gratter Web.
Un défi est variété. Chaque site est différent. Bien que vous rencontriez des structures générales qui ont tendance à se répéter, chaque site Web est unique et nécessitera un traitement personnel si vous souhaitez extraire les informations qui vous intéressent.
Un autre défi est durabilité. Les sites Web changent constamment. Supposons que vous ayez créé un nouveau grattoir Web brillant qui sélectionne automatiquement ce que vous voulez parmi vos ressources d’intérêt. La première fois que vous exécutez votre script, cela fonctionne parfaitement. Mais lorsque vous exécutez le même script peu de temps après, vous vous retrouvez face à une pile de traces très décourageante et décourageante!
Ceci est un scénario réaliste, car de nombreux sites Web sont en développement actif. Une fois la structure du site modifiée, il se peut que votre scraper ne puisse plus naviguer correctement dans le plan du site ni trouver les informations pertinentes. La bonne nouvelle est que de nombreux changements sur les sites Web sont minimes et progressifs. Vous pourrez donc probablement mettre à jour votre scraper avec des ajustements minimes.
Cependant, gardez à l'esprit que, comme Internet est dynamique, les scrapeurs que vous construirez nécessiteront probablement une maintenance constante. Vous pouvez configurer une intégration continue pour exécuter des tests de grattage régulièrement afin de s’assurer que votre script principal ne se brise pas à votre insu.
API: une alternative à la Web Scraping
Certains fournisseurs de sites Web offrent Interfaces de programmation d'application (API) qui vous permettent d'accéder à leurs données d'une manière prédéfinie. Avec les API, vous pouvez éviter d'analyser le code HTML et accéder directement aux données à l'aide de formats tels que JSON et XML. Le HTML est avant tout un moyen de présenter visuellement du contenu aux utilisateurs.
Lorsque vous utilisez une API, le processus est généralement plus stable que la collecte des données via le scraping Web. C’est parce que les API sont conçues pour être consommées par des programmes plutôt que par des yeux humains. Si la conception d’un site Web change, cela ne signifie pas pour autant que la structure de l’API a changé.
Cependant, les API pouvez changer aussi bien. Les défis de la variété et de la durabilité s’appliquent aux API comme aux sites Web. De plus, il est beaucoup plus difficile de vérifier vous-même la structure d’une API si la documentation fournie manque de qualité.
L'approche et les outils dont vous avez besoin pour collecter des informations à l'aide d'API n'entrent pas dans le cadre de ce didacticiel. Pour en savoir plus à ce sujet, consultez API Integration in Python.
Gratter le site de monstre
Dans ce didacticiel, vous allez créer un scraper Web qui récupère les offres d’emploi de développeur logiciel sur le site de regroupement d’emplois Monster. Votre scraper Web analysera le code HTML pour sélectionner les informations pertinentes et filtrer ce contenu pour des mots spécifiques.
Vous pouvez consulter n'importe quel site sur Internet que vous pouvez consulter, mais la difficulté de le faire dépend du site. Ce tutoriel vous propose une introduction à la suppression de contenu Web pour vous aider à comprendre le processus global. Ensuite, vous pouvez appliquer ce même processus à tous les sites Web que vous souhaitez gratter.
Partie 1: Inspectez votre source de données
La première étape consiste à accéder au site que vous souhaitez gratter à l'aide de votre navigateur préféré. Vous devez comprendre la structure du site pour extraire les informations qui vous intéressent.
Explorez le site Web
Cliquez sur le site et interagissez-le comme n'importe quel utilisateur normal. Par exemple, vous pouvez rechercher des emplois Software Developer en Australie à l’aide de l’interface de recherche native du site:

Vous pouvez voir qu’une liste des tâches renvoyées se trouve à gauche et que des descriptions plus détaillées sur la tâche sélectionnée se trouvent à droite. Lorsque vous cliquez sur l'une des tâches de gauche, le contenu de droite change. Vous pouvez également constater que lorsque vous interagissez avec le site Web, l’URL de la barre d’adresse de votre navigateur change également.
Déchiffrer les informations dans les URL
De nombreuses informations peuvent être encodées dans une URL. Votre parcours de nettoyage Web sera beaucoup plus facile si vous vous familiarisez d’abord avec le fonctionnement des URL et en quoi elles sont faites. Essayez de choisir l’URL du site sur lequel vous êtes actuellement:
https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia
Vous pouvez décomposer l'URL ci-dessus en deux parties principales:
- L'URL de base représente le chemin d'accès à la fonctionnalité de recherche du site Web. Dans l'exemple ci-dessus, l'URL de base est
https://www.monster.com/jobs/search/. - Les paramètres de la requête représentent des valeurs supplémentaires pouvant être déclarées sur la page. Dans l'exemple ci-dessus, les paramètres de requête sont
? q = développeur de logiciels et où = Australie.
Toute tâche que vous recherchez sur ce site Web utilisera la même URL de base. Toutefois, les paramètres de la requête changeront en fonction de ce que vous recherchez. Vous pouvez les considérer comme des chaînes de requête envoyées à la base de données pour récupérer des enregistrements spécifiques.
Les paramètres de requête se composent généralement de trois choses:
- Début: Le début des paramètres de la requête est signalé par un point d'interrogation (
?). - Information: Les informations constituant un paramètre de requête sont codées dans des paires clé-valeur, les clés et les valeurs associées étant reliées par un signe égal (
clé = valeur). - Séparateur: Chaque URL peut avoir plusieurs paramètres de requête, qui sont séparés les uns des autres par un et commercial (
Et).
Avec ces informations, vous pouvez séparer les paramètres de requête de l’URL en deux paires clé-valeur:
q = développeur de logicielssélectionne le type d’emploi que vous recherchez.où = Australiesélectionne l’emplacement que vous recherchez.
Essayez de modifier les paramètres de recherche et observez les conséquences sur votre URL. Allez-y et entrez de nouvelles valeurs dans la barre de recherche en haut:

Ensuite, essayez de modifier les valeurs directement dans votre URL. Voyez ce qui se passe lorsque vous collez l'URL suivante dans la barre d'adresse de votre navigateur:
https://www.monster.com/jobs/search/?q=Programmer&where=New-York
Vous remarquerez que les modifications apportées dans la zone de recherche du site sont directement reflétées dans les paramètres de requête de l'URL, et inversement. Si vous changez l’un d’eux, vous verrez des résultats différents sur le site Web. Lorsque vous explorez des URL, vous pouvez obtenir des informations sur la manière de récupérer des données à partir du serveur du site Web.
Inspecter le site à l'aide des outils de développement
Ensuite, vous voudrez en savoir plus sur la structure des données pour affichage. Vous devez comprendre la structure de la page pour choisir ce que vous voulez dans la réponse HTML que vous collecterez au cours de l’une des étapes à venir.
Outils de développement peut vous aider à comprendre la structure d'un site Web. Tous les navigateurs modernes sont livrés avec des outils de développement installés. Dans ce didacticiel, vous apprendrez à utiliser les outils de développement de Chrome. Le processus sera très similaire à celui des autres navigateurs modernes.
Dans Chrome, vous pouvez ouvrir les outils de développement via le menu. Affichage → Développeur → Outils de développement. Vous pouvez également y accéder en cliquant avec le bouton droit sur la page et en sélectionnant Inspecter option, ou en utilisant un raccourci clavier.
Les outils de développement vous permettent d’explorer de manière interactive le domaine DOM du site afin de mieux comprendre la source avec laquelle vous travaillez. Pour creuser dans le DOM de votre page, sélectionnez le Éléments onglet dans les outils de développement. Vous verrez une structure avec des éléments HTML cliquables. Vous pouvez développer, réduire et même modifier des éléments directement dans votre navigateur:
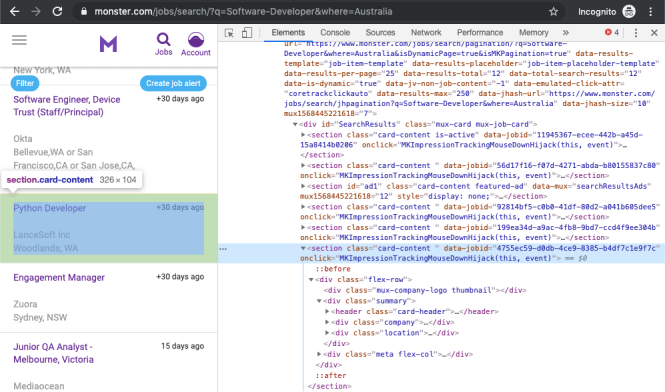
Vous pouvez considérer le texte affiché dans votre navigateur comme la structure HTML de cette page. Si vous êtes intéressé, vous pouvez en savoir plus sur la différence entre DOM et HTML sur CSS-TRICKS.
Lorsque vous cliquez avec le bouton droit sur des éléments de la page, vous pouvez sélectionner Inspecter pour zoomer sur leur emplacement dans le DOM. Vous pouvez également survoler le texte HTML à droite et voir les éléments correspondants s'allumer sur la page.
Tâche: Trouver une seule offre d'emploi. Quel élément HTML est-il encapsulé et quels autres éléments HTML contient-il?
Jouez et explorez! Plus vous connaîtrez la page sur laquelle vous travaillez, plus il sera facile de la supprimer. Cependant, ne vous laissez pas submerger par tout ce texte HTML. Vous utiliserez le pouvoir de la programmation pour parcourir ce labyrinthe et ne sélectionner que les parties les plus intéressantes de Beautiful Soup.
Partie 2: supprimer du contenu HTML d'une page
Maintenant que vous avez une idée de ce avec quoi vous travaillez, il est temps de commencer à utiliser Python. Tout d’abord, vous souhaiterez obtenir le code HTML du site dans votre script Python afin de pouvoir interagir avec celui-ci. Pour cette tâche, vous utiliserez Python. demandes bibliothèque. Tapez ce qui suit dans votre terminal pour l'installer:
Ouvrez ensuite un nouveau fichier dans votre éditeur de texte préféré. Il suffit de quelques lignes de code pour récupérer le code HTML:
importation demandes
URL = "https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia"
page = demandes.obtenir(URL)
Ce code effectue une requête HTTP sur l'URL donnée. Il récupère les données HTML renvoyées par le serveur et les stocke dans un objet Python.
Si vous examinez le contenu téléchargé, vous remarquerez qu'il ressemble beaucoup au code HTML que vous avez précédemment inspecté avec les outils de développement. Pour améliorer la manière dont le code HTML est affiché dans la sortie de votre console, vous pouvez imprimer le .contenu attribuer avec pprint ().
Sites statiques
Le site Web que vous grattez dans ce didacticiel sert contenu HTML statique. Dans ce scénario, le serveur qui héberge le site renvoie des documents HTML contenant déjà toutes les données que vous pourrez voir en tant qu’utilisateur.
Lorsque vous avez précédemment inspecté la page à l'aide d'outils de développement, vous avez découvert qu'une offre d'emploi se composait du code HTML long et désordonné suivant:
<section classe="contenu de la carte" data-jobid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c" sur clic="MKImpressionTrackingMouseDownHijack (this, event)">
<div classe="flex-row">
<div classe="mux-company-logo thumbnail"> </div>
<div classe="sommaire">
<entête classe="en-tête de carte">
<h2 classe="Titre"> <une contournement des données="vrai" data-m_impr_a_placement_id="JSR2CW" data-m_impr_j_cid="4" data-m_impr_j_coc="" data-m_impr_j_jawsid="371676273" data-m_impr_j_jobid="0" data-m_impr_j_jpm="2" data-m_impr_j_jpt="3" data-m_impr_j_lat="30.1882" data-m_impr_j_lid="619" data-m_impr_j_long="-95.6732" data-m_impr_j_occid="11838" data-m_impr_j_p="3" data-m_impr_j_postingid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c" data-m_impr_j_pvc="4496dab8-a60c-4f02-a2d1-6213320e7213" data-m_impr_s_t="t" data-m_impr_uuid="0b620778-73c7-4550-9db5-df4efad23538" href="https://job-openings.monster.com/python-developer-woodlands-wa-us-lancesoft-inc/4755ec59-d0db-4ce9-8385-b4df7c1e9f7c" sur clic="clickJobTitle ('plid = 619 & pcid = 4 & poccid = 11838', 'Développeur logiciel', ''); clickJobTitleSiteCat ('" events.event48 ":" true "," eVar25 ":" Python Developer "," eVar66 ":" Monster "," eVar67 ":" JSR2CW "," eVar26 ":" _ LanceSoft Inc "," eVar31 ":" Woodlands_WA _ "," prop24 ":" 2019-07-02T12: 00 "," eVar53 ":" 1500127001001 ", "eVar50": "agrégé", "eVar74": "normal" ') ">Développeur Python
</une> </h2>
</entête>
<div classe="entreprise">
<envergure classe="prénom">LanceSoft Inc</envergure>
<ul classe="list-inline">
</ul>
</div>
<div classe="emplacement">
<envergure classe="prénom">
Woodlands, WA
</envergure>
</div>
</div>
<div classe="méta flex-col">
<temps date / heure="2017-05-26T12: 00">il y a 2 jours</temps>
<envergure classe="mux-tooltip appliqué seulement" data-mux="infobulle" Titre="Appliqué">
<je aria-caché="vrai" classe="icône icône appliquée"> </je>
<envergure classe="sr-only">Appliqué</envergure>
</envergure>
<envergure classe="mux-tooltip enregistré seulement" data-mux="infobulle" Titre="Enregistré">
<je aria-caché="vrai" classe="icône icône enregistrée"> </je>
<envergure classe="sr-only">Enregistré</envergure>
</envergure>
</div>
</div>
</section>
Il peut être difficile d’envisager un aussi long bloc de code HTML. Pour faciliter la lecture, vous pouvez utiliser un formateur HTML pour le nettoyer automatiquement un peu plus. Une bonne lisibilité vous aide à mieux comprendre la structure de tout bloc de code. Même si cela peut aider ou non à améliorer le formatage du HTML, cela vaut toujours la peine d’essayer.
Remarque: Gardez à l'esprit que chaque site Web sera différent. C’est pourquoi il est nécessaire d’inspecter et de comprendre la structure du site sur lequel vous travaillez actuellement avant de poursuivre.
Le code HTML ci-dessus comporte certainement quelques parties confuses. Par exemple, vous pouvez faire défiler vers la droite pour voir le grand nombre d’attributs que le élément a. Heureusement la noms de classe sur les éléments qui vous intéressent sont relativement simples:
class = "titre": le titre de l'offre d'emploiclasse = "entreprise": l'entreprise qui propose le posteclass = "location": l'endroit où vous travailleriez
Au cas où vous vous perdriez dans une grande pile de HTML, souvenez-vous que vous pouvez toujours revenir à votre navigateur et utiliser les outils de développement pour explorer davantage la structure HTML de manière interactive.
A ce jour, vous avez exploité avec succès la puissance et la conception conviviale des logiciels Python. demandes bibliothèque. Avec seulement quelques lignes de code, vous avez réussi à extraire le contenu HTML statique du Web et à le rendre disponible pour un traitement ultérieur.
Cependant, il existe quelques situations plus difficiles que vous pouvez rencontrer lorsque vous grattez des sites Web. Avant de commencer à utiliser Beautiful Soup pour sélectionner les informations pertinentes du code HTML que vous venez de gratter, jetez un coup d’œil à deux de ces situations.
Sites Web cachés
Certaines pages contiennent des informations cachées derrière une connexion. Cela signifie que vous aurez besoin d’un compte pour pouvoir voir (et gratter) tout ce qui se trouve sur la page. Le processus de création d'une requête HTTP à partir de votre script Python diffère de la façon dont vous accédez à une page à partir de votre navigateur. Cela signifie que le fait que vous puissiez vous connecter à la page via votre navigateur ne signifie pas que vous pourrez la supprimer avec votre script Python.
Cependant, il existe certaines techniques avancées que vous pouvez utiliser avec le demandes pour accéder au contenu derrière les connexions. Ces techniques vous permettront de vous connecter à des sites Web tout en effectuant la demande HTTP à partir de votre script.
Sites Web dynamiques
Les sites statiques sont plus faciles à utiliser car le serveur vous envoie une page HTML contenant déjà toutes les informations en réponse. Vous pouvez analyser une réponse HTML avec Beautiful Soup et commencer à sélectionner les données pertinentes.
Par contre, avec un site dynamique le serveur peut ne pas renvoyer du code HTML du tout. Au lieu de cela, vous recevrez un code JavaScript en réponse. Cela sera complètement différent de ce que vous avez vu lorsque vous avez inspecté la page avec les outils de développement de votre navigateur.
Remarque: Pour décharger le travail du serveur sur les ordinateurs des clients, de nombreux sites Web modernes évitent autant que possible de faire des calculs sur leurs serveurs. Au lieu de cela, ils enverront JavaScript code que votre navigateur exécutera localement pour produire le code HTML souhaité.
Comme mentionné précédemment, ce qui se passe dans le navigateur n'est pas lié à ce qui se passe dans votre script. Votre navigateur exécutera avec diligence le code JavaScript reçu par un serveur et créera le DOM et le HTML pour vous localement. Cependant, faire une demande à un site Web dynamique dans votre script Python va ne pas vous fournir le contenu de la page HTML.
Quand vous utilisez demandes, vous ne recevrez que ce que le serveur renvoie. Dans le cas d’un site Web dynamique, vous obtiendrez du code JavaScript que vous ne pourrez pas analyser avec Beautiful Soup. La seule façon de passer du code JavaScript au contenu qui vous intéresse est de exécuter le code, tout comme votre navigateur. le demandes bibliothèque ne peut pas le faire pour vous, mais il existe d’autres solutions.
Par exemple, demandes-html est un projet créé par l'auteur de la demandes une bibliothèque qui vous permet de rendre facilement le code JavaScript à l’aide d’une syntaxe similaire à celle demandes. Il inclut également des fonctionnalités permettant d'analyser les données à l'aide de Beautiful Soup sous le capot.
Remarque: Un autre choix populaire pour gratter le contenu dynamique est Sélénium. Vous pouvez considérer Selenium comme un navigateur allégé qui exécute le code JavaScript avant de transmettre la réponse HTML rendue à votre script.
Dans ce didacticiel, vous n’allez pas approfondir la tâche de gratter le contenu généré dynamiquement. Pour le moment, il vous suffit de vous rappeler que vous devrez examiner les options susmentionnées si la page qui vous intéresse est générée de manière dynamique dans votre navigateur.
Partie 3: Analyser le code HTML avec une belle soupe
Vous avez réussi à extraire un peu de HTML d’Internet, mais quand vous le regardez maintenant, cela semble être un énorme gâchis. Il y a des tonnes d’éléments HTML ici et là, des milliers d’attributs éparpillés, et le JavaScript n’est-il pas également mélangé? Il est temps d’analyser cette longue réponse de code avec Beautiful Soup pour la rendre plus accessible et sélectionner les données qui vous intéressent.
Beautiful Soup est une bibliothèque Python pour analyser des données structurées. Il vous permet d'interagir avec HTML de la même manière que vous interagissiez avec une page Web à l'aide d'outils de développement. Beautiful Soup expose quelques fonctions intuitives que vous pouvez utiliser pour explorer le code HTML que vous avez reçu. Pour commencer, utilisez votre terminal pour installer la bibliothèque Beautiful Soup:
$ pip3 installer beautifulsoup4
Importez ensuite la bibliothèque et créez un objet Beautiful Soup:
importation demandes
de bs4 importation BeautifulSoup
URL = "https://www.monster.com/jobs/search/?q=Software-Developer&where=Australia"
page = demandes.obtenir(URL)
soupe = BeautifulSoup(page.contenu, 'html.parser')
Lorsque vous ajoutez les deux lignes de code en surbrillance, vous créez un objet Beautiful Soup qui prend en entrée le contenu HTML que vous avez précédemment gratté. Lorsque vous instanciez l'objet, vous indiquez également à Beautiful Soup d'utiliser l'analyseur approprié.
Rechercher des éléments par ID
Dans une page Web HTML, chaque élément peut avoir une identifiant attribut attribué. Comme son nom l'indique déjà, identifiant attribut rend l'élément identifiable de manière unique sur la page. Vous pouvez commencer à analyser votre page en sélectionnant un élément spécifique par son ID.
Revenez aux outils de développement et identifiez l'objet HTML contenant toutes les offres d'emploi. Explorez en survolant certaines parties de la page et en cliquant avec le bouton droit de la souris. Inspecter.
Remarque: N'oubliez pas qu'il est utile de revenir périodiquement à votre navigateur et d'explorer la page de manière interactive à l'aide d'outils de développement. Cela vous aide à trouver les éléments exacts que vous recherchez.
Au moment d'écrire ces lignes, l'élément que vous recherchez est un
identifiant attribut qui a la valeur "RésultatsConteneur". Il a également quelques autres attributs, mais voici l'essentiel de ce que vous recherchez:
<div identifiant="RésultatsConteneur">
</div>
Beautiful Soup vous permet de trouver cet élément spécifique facilement grâce à son identifiant:
résultats = soupe.trouver(identifiant='ResultsContainer')
Pour faciliter la visualisation, vous pouvez .enjoliver() tout objet Belle Soupe lorsque vous l'imprimez. Si vous appelez cette méthode sur le résultats variable que vous venez d’attribuer ci-dessus, vous devriez voir tout le code HTML contenu dans le
impression(résultats.enjoliver())
Lorsque vous utilisez l’ID de l’élément, vous pouvez choisir un élément parmi le reste du code HTML. Cela vous permet de travailler uniquement avec cette partie spécifique du code HTML de la page. On dirait que la soupe vient d'être un peu plus mince! Cependant, il est encore assez dense.
Rechercher des éléments par nom de classe HTML
Vous avez vu que chaque offre d'emploi est emballée dans un
contenu de la carte. Maintenant, vous pouvez travailler avec votre nouvel objet Beautiful Soup appelé résultats et sélectionnez uniquement les offres d'emploi. Ce sont, après tout, les parties du code HTML qui vous intéressent! Vous pouvez le faire en une seule ligne de code:
job_elems = résultats.Trouver tout('section', classe_='contenu de la carte')
Ici, vous appelez .Trouver tout() sur un objet Beautiful Soup, qui renvoie une valeur itérable contenant tout le code HTML de toutes les offres d'emploi affichées sur cette page.
Jetez un coup d'œil à tous:
pour job_elem dans job_elems:
impression(job_elem, fin=' n'*2)
C’est déjà très joli, mais il reste encore beaucoup de HTML! Vous avez vu précédemment que votre page comporte des noms de classe descriptifs sur certains éléments. Ne choisissons que ceux:
pour job_elem dans job_elems:
# Chaque job_elem est un nouvel objet BeautifulSoup.
# Vous pouvez utiliser les mêmes méthodes que précédemment.
title_elem = job_elem.trouver('h2', classe_='Titre')
company_elem = job_elem.trouver('div', classe_='entreprise')
location_elem = job_elem.trouver('div', classe_='emplacement')
impression(title_elem)
impression(company_elem)
impression(location_elem)
impression()
Génial! Vous vous rapprochez de plus en plus des données qui vous intéressent. Néanmoins, il se passe beaucoup de choses avec toutes ces balises et attributs HTML flottants:
<h2 classe="Titre"> <une contournement des données="vrai" data-m_impr_a_placement_id="JSR2CW" data-m_impr_j_cid="4" data-m_impr_j_coc="" data-m_impr_j_jawsid="371676273" data-m_impr_j_jobid="0" data-m_impr_j_jpm="2" data-m_impr_j_jpt="3" data-m_impr_j_lat="30.1882" data-m_impr_j_lid="619" data-m_impr_j_long="-95.6732" data-m_impr_j_occid="11838" data-m_impr_j_p="3" data-m_impr_j_postingid="4755ec59-d0db-4ce9-8385-b4df7c1e9f7c" data-m_impr_j_pvc="4496dab8-a60c-4f02-a2d1-6213320e7213" data-m_impr_s_t="t" data-m_impr_uuid="0b620778-73c7-4550-9db5-df4efad23538" href="https://job-openings.monster.com/python-developer-woodlands-wa-us-lancesoft-inc/4755ec59-d0db-4ce9-8385-b4df7c1e9f7c" sur clic="clickJobTitle ('plid = 619 & pcid = 4 & poccid = 11838', 'Développeur logiciel', ''); clickJobTitleSiteCat ('" events.event48 ":" true "," eVar25 ":" Python Developer "," eVar66 ":" Monster "," eVar67 ":" JSR2CW "," eVar26 ":" _ LanceSoft Inc "," eVar31 ":" Woodlands_WA _ "," prop24 ":" 2019-07-02T12: 00 "," eVar53 ":" 1500127001001 ", "eVar50": "agrégé", "eVar74": "normal" ') ">Développeur Python
</une> </h2>
<div classe="entreprise">
<envergure classe="prénom">LanceSoft Inc</envergure>
<ul classe="list-inline">
</ul>
</div>
<div classe="emplacement">
<envergure classe="prénom">
Woodlands, WA
</envergure>
</div>
Vous verrez comment réduire ce résultat dans la section suivante.
Pour le moment, vous souhaitez uniquement voir le titre, la société et l'emplacement de chaque offre d'emploi. Et voici! Belle soupe vous a couvert. Vous pouvez ajouter .texte à un objet Beautiful Soup de ne renvoyer que le contenu du texte des éléments HTML que l'objet contient:
pour job_elem dans job_elems:
title_elem = job_elem.trouver('h2', classe_='Titre')
company_elem = job_elem.trouver('div', classe_='entreprise')
location_elem = job_elem.trouver('div', classe_='emplacement')
impression(title_elem.texte)
impression(company_elem.texte)
impression(location_elem.texte)
impression()
Exécutez l'extrait de code ci-dessus et vous verrez le contenu du texte affiché. Cependant, vous aurez également beaucoup d’espace. Puisque vous travaillez maintenant avec des chaînes Python, vous pouvez .bande() les espaces superflus. Vous pouvez également appliquer toute autre méthode de chaîne Python familière pour nettoyer davantage votre texte.
Remarque: Le Web est en désordre et vous ne pouvez pas compter sur une structure de page cohérente. Par conséquent, vous rencontrerez le plus souvent des erreurs lors de l’analyse HTML.
Lorsque vous exécutez le code ci-dessus, vous pouvez rencontrer un problème. AttributeError:
AttributeError: l'objet 'NoneType' n'a pas d'attribut 'text'
Si tel est le cas, prenez du recul et examinez vos résultats précédents. Y at-il des articles d'une valeur de Aucun? Vous avez peut-être remarqué que la structure de la page n'est pas totalement uniforme. Il pourrait y avoir une annonce qui s’affiche différemment des offres d’emploi classiques, ce qui peut donner des résultats différents. Pour ce tutoriel, vous pouvez ignorer en toute sécurité l'élément problématique et le ignorer lors de l'analyse du code HTML:
pour job_elem dans job_elems:
title_elem = job_elem.trouver('h2', classe_='Titre')
company_elem = job_elem.trouver('div', classe_='entreprise')
location_elem = job_elem.trouver('div', classe_='emplacement')
si Aucun dans (title_elem, company_elem, location_elem):
continuer
impression(title_elem.texte.bande())
impression(company_elem.texte.bande())
impression(location_elem.texte.bande())
impression()
N'hésitez pas à explorer pourquoi l'un des éléments est renvoyé en tant que Aucun. Vous pouvez utiliser la déclaration conditionnelle que vous avez écrite ci-dessus pour impression() et inspecter l’élément concerné plus en détail. Que pensez-vous qu'il se passe là-bas?
Une fois que vous avez terminé les étapes ci-dessus, essayez de réexécuter votre script. Les résultats sont finalement bien meilleurs:
Développeur Python
LanceSoft Inc
Woodlands, WA
Senior Engagement Manager
Zuora
Sydney, NSW
Rechercher des éléments par nom de classe et contenu de texte
A présent, vous avez nettoyé la liste des tâches que vous avez vues sur le site Web. Bien que ce soit déjà très intéressant, vous pouvez rendre votre script plus utile. Cependant, toutes les offres d'emploi ne semblent pas être des tâches de développeur qui pourraient vous intéresser en tant que développeur Python. Par conséquent, au lieu d’imprimer tous les travaux de la page, vous devez d’abord les filtrer en fonction de certains mots clés.
Vous savez que les titres de poste de la page sont conservés dans
éléments. Pour filtrer uniquement pour
spécifiques, vous pouvez utiliser le chaîne argument:
python_jobs = résultats.Trouver tout('h2', chaîne='Développeur Python')
python_jobs = résultats.Trouver tout('h2', chaîne='Développeur Python')
Ce code trouve tout
éléments où la chaîne contenue correspond 'Développeur Python' exactement. Notez que vous appelez directement la méthode lors de votre première résultats variable. Si vous allez de l'avant et impression() la sortie de l'extrait de code ci-dessus sur votre console, vous pourriez être déçu, car il sera probablement vide:
Il y avait certainement un travail avec ce titre dans les résultats de la recherche, alors pourquoi ne s'affiche-t-il pas? Quand vous utilisez chaîne = comme vous l'avez fait ci-dessus, votre programme recherche exactement cette chaîne. Toute différence de capitalisation ou d’espace empêchera la correspondance de l’élément. Dans la section suivante, vous trouverez un moyen de rendre la chaîne plus générale.
Passer une fonction à une belle méthode de soupe
En plus des chaînes, vous pouvez souvent passer des fonctions comme arguments aux méthodes Beautiful Soup. Vous pouvez modifier la ligne de code précédente pour utiliser une fonction à la place:
python_jobs = résultats.Trouver tout('h2',
chaîne=lambda texte: 'python' dans texte.inférieur())
Maintenant vous passez un fonction anonyme au chaîne = argument. La fonction lambda regarde le texte de chaque
élément, le convertit en minuscule et vérifie si la sous-chaîne 'python' se trouve n'importe où là-bas. Maintenant, vous avez un match:
>>>
>>> impression(len(python_jobs))
1
>>> impression(len(python_jobs))
1
Votre programme a trouvé une correspondance!
Remarque: Si vous ne trouvez toujours pas de correspondance, essayez d’adapter votre chaîne de recherche. Les offres d'emploi sur cette page changent constamment et il se peut qu'aucun emploi ne comprenant la sous-chaîne ne soit répertorié. 'python' dans son titre au moment où vous travaillez sur ce tutoriel.
Le processus de recherche d’éléments spécifiques en fonction de leur contenu textuel constitue un moyen puissant de filtrer votre réponse HTML en fonction des informations recherchées. Beautiful Soup vous permet d'utiliser des chaînes exactes ou des fonctions en tant qu'arguments pour filtrer le texte dans les objets Beautiful Soup.
À ce stade, votre script Python supprime déjà le site et filtre son code HTML en fonction des offres d'emploi correspondantes. Bien joué! Cependant, il manque encore le lien pour postuler à un emploi.
Pendant que vous inspectiez la page, vous avez constaté que le lien fait partie de l’élément qui a la Titre Classe HTML. Le code actuel supprime l’ensemble du lien lorsqu’il accède à la .texte attribut de son élément parent. Comme vous l’avez déjà vu, .texte contient uniquement le contenu de texte visible d'un élément HTML. Les balises et attributs ne font pas partie de cela. Pour obtenir l'URL réelle, vous voulez extrait un de ces attributs au lieu de le jeter.
Regardez la liste des résultats filtrés python_jobs que vous avez créé ci-dessus. L'URL est contenue dans le href attribut du imbriqué étiquette. Commencez par aller chercher le element. Then, extract the value of its href attribute using square-bracket notation:
python_jobs = results.find_all('h2',
chaîne=lambda texte: "python" dans texte.inférieur())
pour p_job dans python_jobs:
link = p_job.find('a')[[[['href']
impression(p_job.texte.strip())
impression(F"Apply here: link n")
The filtered results will only show links to job opportunities that include python in their title. You can use the same square-bracket notation to extract other HTML attributes as well. A common use case is to fetch the URL of a link, as you did above.
If you’ve written the code alongside this tutorial, then you can already run your script as-is. To wrap up your journey into web scraping, you could give the code a final makeover and create a command line interface app that looks for Software Developer jobs in any location you define.
You can check out a command line app version of the code you built in this tutorial at the link below:
If you’re interested in learning how to adapt your script as a command line interface, then check out How to Build Command Line Interfaces in Python With argparse.
Additional Practice
Below is a list of other job boards. These linked pages also return their search results as static HTML responses. To keep practicing your new skills, you can revisit the web scraping process using any or all of the following sites:
Go through this tutorial again from the top using one of these other sites. You’ll see that the structure of each website is different and that you’ll need to re-build the code in a slightly different way to fetch the data you want. This is a great way to practice the concepts that you just learned. While it might make you sweat every so often, your coding skills will be stronger for it!
During your second attempt, you can also explore additional features of Beautiful Soup. Use the documentation as your guidebook and inspiration. Additional practice will help you become more proficient at web scraping using Python, requests, and Beautiful Soup.
Conclusion
Beautiful Soup is packed with useful functionality to parse HTML data. It’s a trusted and helpful companion for your web scraping adventures. Its documentation is comprehensive and relatively user-friendly to get started with. You’ll find that Beautiful Soup will cater to most of your parsing needs, from navigating to advanced searching through the results.
In this tutorial, you’ve learned how to scrape data from the Web using Python, requests, and Beautiful Soup. You built a script that fetches job postings from the Internet and went through the full web scraping process from start to finish.
You learned how to:
- Inspect the HTML structure of your target site with your browser’s developer tools
- Gain insight into how to decipher the data encoded in URLs
- Télécharger the page’s HTML content using Python’s
requestslibrary - Parse the downloaded HTML with Beautiful Soup to extract relevant information
With this general pipeline in mind and powerful libraries in your toolkit, you can go out and see what other websites you can scrape! Have fun, and remember to always be respectful and use your programming skills responsibly.
You can download the source code for the sample script that you built in this tutorial by clicking on the link below:
[ad_2]