Formation Python
Réseaux antagonistes génératifs (GAN) sont des réseaux neuronaux qui génèrent du matériel, comme des images, de la musique, de la parole ou du texte, similaire à ce que les humains produisent.
Les GAN ont été un sujet de recherche actif ces dernières années. Le directeur de la recherche sur l'IA de Facebook, Yann LeCun, a qualifié la formation contradictoire d '«idée la plus intéressante de ces 10 dernières années» dans le domaine de l'apprentissage automatique. Ci-dessous, vous découvrirez le fonctionnement des GAN avant de mettre en œuvre vos propres modèles génératifs.
Dans ce didacticiel, vous apprendrez:
- Quel modèle génératif est et en quoi il diffère d'un modèle discriminant
- Comment sont les GAN structuré et qualifié
- Comment construisez votre propre GAN en utilisant PyTorch
- Comment formez votre GAN pour des applications pratiques utilisant un GPU et PyTorch
Commençons!
Bonus gratuit: 5 Réflexions sur la maîtrise de Python, un cours gratuit pour les développeurs Python qui vous montre la feuille de route et l'état d'esprit dont vous aurez besoin pour faire passer vos compétences Python au niveau supérieur.
Que sont les réseaux conflictuels génératifs?
Réseaux antagonistes génératifs sont des systèmes d'apprentissage automatique qui peuvent apprendre à imiter une distribution donnée de données. Ils ont été proposés pour la première fois dans un article NeurIPS de 2014 par l'expert en apprentissage profond Ian Goodfellow et ses collègues.
Les GAN sont constitués de deux réseaux de neurones, l'un formé pour générer des données et l'autre formé pour distinguer les fausses données des données réelles (d'où la nature «contradictoire» du modèle). Bien que l'idée d'une structure pour générer des données ne soit pas nouvelle, en matière de génération d'images et de vidéos, les GAN ont fourni des résultats impressionnants tels que:
Les structures qui génèrent des données, y compris les GAN, sont prises en compte modèles génératifs contrairement au plus largement étudié modèles discriminants. Avant de plonger dans les GAN, vous examinerez les différences entre ces deux types de modèles.
Modèles discriminatoires vs génératifs
Si vous avez étudié les réseaux de neurones, la plupart des applications que vous avez rencontrées ont probablement été implémentées à l’aide de modèles discriminants. Les réseaux antagonistes génératifs, quant à eux, font partie d'une classe différente de modèles connus sous le nom de modèles génératifs.
Les modèles discriminatoires sont ceux utilisés pour la plupart des classification ou régression problèmes. À titre d'exemple de problème de classification, supposons que vous souhaitiez entraîner un modèle pour classer les images de chiffres manuscrits de 0 à 9. Pour cela, vous pouvez utiliser un ensemble de données étiqueté contenant des images de chiffres manuscrits et leurs étiquettes associées indiquant quel chiffre chacun l'image représente.
Au cours du processus d'entraînement, vous utiliserez un algorithme pour ajuster les paramètres du modèle. L'objectif serait de minimiser une fonction de perte afin que le modèle apprenne distribution de probabilité de la sortie étant donné l'entrée. Après la phase d'apprentissage, vous pouvez utiliser le modèle pour classer une nouvelle image de chiffre manuscrite en estimant le chiffre le plus probable auquel l'entrée correspond, comme illustré dans la figure ci-dessous:

Vous pouvez imaginer des modèles discriminants pour les problèmes de classification comme des blocs qui utilisent les données d'apprentissage pour apprendre les limites entre les classes. Ils utilisent ensuite ces limites pour discriminer une entrée et prédire sa classe. En termes mathématiques, les modèles discriminants apprennent la probabilité conditionnelle P(y|X) de la sortie y étant donné l'entrée X.
Outre les réseaux de neurones, d'autres structures peuvent être utilisées comme modèles discriminants tels que les modèles de régression logistique et les machines vectorielles de support (SVM).
Les modèles génératifs comme les GAN, cependant, sont formés pour décrire comment un ensemble de données est généré en termes de probabiliste modèle. En échantillonnant à partir d'un modèle génératif, vous êtes en mesure de générer de nouvelles données. Alors que les modèles discriminants sont utilisés pour l'apprentissage supervisé, les modèles génératifs sont souvent utilisés avec des ensembles de données non étiquetés et peuvent être considérés comme une forme d'apprentissage non supervisé.
En utilisant l'ensemble de données de chiffres manuscrits, vous pouvez entraîner un modèle génératif pour générer de nouveaux chiffres. Pendant la phase d’apprentissage, vous utiliserez un algorithme pour ajuster les paramètres du modèle afin de minimiser une fonction de perte et apprendre la distribution de probabilité de l’ensemble d’apprentissage. Ensuite, avec le modèle entraîné, vous pouvez générer de nouveaux échantillons, comme illustré dans la figure suivante:

Pour produire de nouveaux échantillons, les modèles génératifs considèrent généralement un stochastique, ou aléatoire, élément qui influence les échantillons générés par le modèle. Les échantillons aléatoires utilisés pour piloter le générateur sont obtenus à partir d'un espace latent dans lequel les vecteurs représentent une sorte de forme compressée des échantillons générés.
Contrairement aux modèles discriminants, les modèles génératifs apprennent la probabilité P(X) des données d'entrée Xet en disposant de la distribution des données d'entrée, ils sont en mesure de générer de nouvelles instances de données.
Remarque: Les modèles génératifs peuvent également être utilisés avec des ensembles de données étiquetés. Quand ils le sont, ils sont formés pour connaître la probabilité P(X|y) de l'entrée X étant donné la sortie y. Ils peuvent également être utilisés pour les tâches de classification, mais en général, les modèles discriminants fonctionnent mieux en matière de classification.
Vous pouvez trouver plus d'informations sur les forces et les faiblesses relatives des classificateurs discriminants et génératifs dans l'article On Discriminative vs. Generative Classifiers: A Compare of Logistics Regression and Naive Bayes.
Bien que les GAN aient reçu beaucoup d’attention ces dernières années, ils ne sont pas la seule architecture pouvant être utilisée comme modèle génératif. Outre les GAN, il existe diverses autres architectures de modèle génératif telles que:
Cependant, ces derniers temps, les GAN ont attiré le plus grand intérêt du public en raison des résultats passionnants de la génération d'images et de vidéos.
Maintenant que vous connaissez les bases des modèles génératifs, vous allez voir comment fonctionnent les GAN et comment les former.
L'architecture des réseaux conflictuels génératifs
Les réseaux antagonistes génératifs consistent en une structure globale composée de deux réseaux de neurones, l'un appelé le Générateur et l'autre appelé le discriminateur.
Le rôle du générateur est d'estimer la distribution de probabilité des échantillons réels afin de fournir des échantillons générés ressemblant à des données réelles. Le discriminateur, à son tour, est formé pour estimer la probabilité qu'un échantillon donné provienne des données réelles plutôt que d'être fourni par le générateur.
Ces structures sont appelées réseaux antagonistes génératifs parce que le générateur et le discriminateur sont entraînés à se concurrencer: le générateur essaie de mieux tromper le discriminateur, tandis que le discriminateur essaie de mieux identifier les échantillons générés.
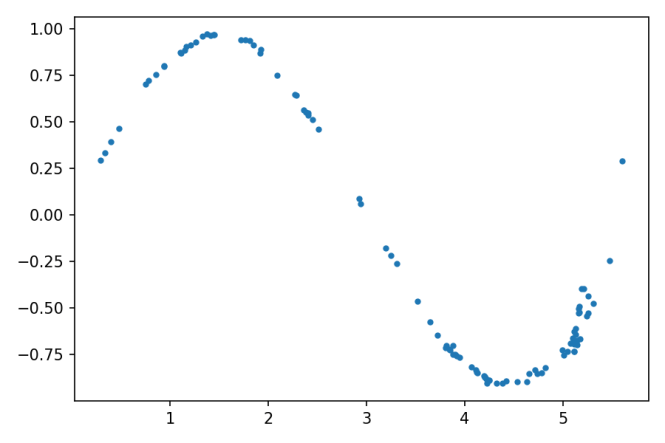
Pour comprendre le fonctionnement de la formation GAN, considérons un exemple de jouet avec un ensemble de données composé d'échantillons bidimensionnels (X₁, X₂), avec X₁ dans l'intervalle de 0 à 2π et X₂ = péché (X₁), comme illustré dans la figure suivante:

Comme vous pouvez le voir, cet ensemble de données se compose de points (X₁, X₂) situé sur une courbe sinusoïdale, ayant une distribution très particulière. La structure globale d'un GAN pour générer des paires (X₁, X₂) ressemblant aux échantillons de l'ensemble de données est illustré dans la figure suivante:

Le générateur g est alimenté par des données aléatoires d'un espace latent, et son rôle est de générer des données ressemblant aux échantillons réels. Dans cet exemple, vous avez un espace latent bidimensionnel, de sorte que le générateur est alimenté en aléatoire (z₁, z₂) paires et doit les transformer pour qu'elles ressemblent aux échantillons réels.
La structure du réseau neuronal g peut être arbitraire, vous permettant d'utiliser des réseaux de neurones comme un perceptron multicouche (MLP), un réseau de neurones convolutif (CNN), ou toute autre structure tant que les dimensions de l'entrée et de la sortie correspondent aux dimensions de l'espace latent et du réel Les données.
Le discriminateur ré est alimenté avec des échantillons réels de l'ensemble de données d'entraînement ou des échantillons générés fournis par g. Son rôle est d'estimer la probabilité d'appartenance de l'entrée à l'ensemble de données réel. La formation est effectuée de sorte que ré génère 1 lorsqu'il est alimenté par un échantillon réel et 0 lorsqu'il alimente un échantillon généré.
Comme avec g, vous pouvez choisir une structure de réseau neuronal arbitraire pour ré tant qu'il respecte les dimensions d'entrée et de sortie nécessaires. Dans cet exemple, l'entrée est bidimensionnelle. Pour un discriminateur binaire, la sortie peut être un scalaire allant de 0 à 1.
Le processus de formation GAN consiste en un jeu minimax à deux joueurs dans lequel ré est adapté pour minimiser l'erreur de discrimination entre les échantillons réels et générés, et g est adapté pour maximiser la probabilité de ré commettre une erreur.
Bien que l'ensemble de données contenant les données réelles ne soit pas étiqueté, les processus d'apprentissage pour ré et g sont exécutés de manière supervisée. A chaque étape de la formation, ré et g ont leurs paramètres mis à jour. En fait, dans la proposition originale du GAN, les paramètres de ré sont mis à jour k fois, tandis que les paramètres de g sont mis à jour une seule fois pour chaque étape de la formation. Cependant, pour simplifier la formation, vous pouvez envisager k égal à 1.
Entraîner ré, à chaque itération, vous étiquetez certains échantillons réels tirés des données d'apprentissage comme 1 et certains échantillons générés fournis par g comme 0. De cette façon, vous pouvez utiliser un cadre d'entraînement supervisé conventionnel pour mettre à jour les paramètres ré afin de minimiser une fonction de perte, comme indiqué dans le schéma suivant:

Pour chaque lot de données d'entraînement contenant des échantillons réels et générés étiquetés, vous mettez à jour les paramètres de ré pour minimiser une fonction de perte. Après les paramètres de ré sont mis à jour, vous vous entraînez g pour produire des échantillons mieux générés. La sortie de g est connecté à ré, dont les paramètres sont maintenus figés, comme illustré ici:

Vous pouvez imaginer le système composé de g et ré comme un système de classification unique qui reçoit des échantillons aléatoires en entrée et sort la classification, qui dans ce cas peut être interprétée comme une probabilité.
Quand g fait un assez bon travail pour tromper ré, la probabilité de sortie doit être proche de 1. Vous pouvez également utiliser un cadre de formation supervisée classique ici: l'ensemble de données pour former le système de classification composé de g et ré serait fourni par des échantillons d'entrée aléatoires, et l'étiquette associée à chaque échantillon d'entrée serait 1.
Pendant l'entraînement, les paramètres de ré et g sont mis à jour, il est prévu que les échantillons générés fournis par g ressemblera plus étroitement aux données réelles, et ré aura plus de difficulté à distinguer les données réelles des données générées.
Maintenant que vous savez comment fonctionnent les GAN, vous êtes prêt à mettre en œuvre les vôtres en utilisant PyTorch.
Votre premier GAN
En tant que première expérience avec des réseaux antagonistes génératifs, vous implémenterez l'exemple décrit dans la section précédente.
Pour exécuter l'exemple, vous allez utiliser la bibliothèque PyTorch, que vous pouvez installer à l'aide de la distribution Anaconda Python et du package conda et du système de gestion de l'environnement. Pour en savoir plus sur Anaconda et conda, consultez le didacticiel sur la configuration de Python pour l'apprentissage automatique sous Windows.
Pour commencer, créez un environnement conda et activez-le:
$ conda create --name gan
$ conda activer gan
Après avoir activé l'environnement conda, votre invite affichera son nom, gan. Ensuite, vous pouvez installer les packages nécessaires dans l'environnement:
$ conda installer -c pytorch pytorche=1.4.0
$ conda installer matplotlib jupyter
Étant donné que PyTorch est un framework très activement développé, l'API peut changer sur les nouvelles versions. Pour vous assurer que l'exemple de code s'exécutera, vous installez la version spécifique 1.4.0.
Outre PyTorch, vous allez utiliser Matplotlib pour travailler avec des tracés et un bloc-notes Jupyter pour exécuter le code dans un environnement interactif. Cela n'est pas obligatoire, mais cela facilite le travail sur des projets d'apprentissage automatique.
Pour un rappel sur l'utilisation de Matplotlib et Jupyter Notebooks, jetez un œil à Python Plotting With Matplotlib (Guide) et Jupyter Notebook: An Introduction.
Avant d'ouvrir Jupyter Notebook, vous devez enregistrer le conda gan l'environnement afin que vous puissiez créer des blocs-notes en l'utilisant comme noyau. Pour ce faire, avec le gan environnement activé, exécutez la commande suivante:
$ python -m ipykernel install --user --name gan
Vous pouvez maintenant ouvrir Jupyter Notebook en exécutant cahier Jupyter. Créez un nouveau bloc-notes en cliquant sur Nouveau puis en sélectionnant gan.
Dans le Notebook, commencez par importer les bibliothèques nécessaires:
importer torche
de torche importer nn
importer math
importer matplotlib.pyplot comme plt
Ici, vous importez la bibliothèque PyTorch avec torche. Vous importez également nn juste pour pouvoir mettre en place les réseaux de neurones de manière moins verbeuse. Ensuite, vous importez math pour obtenir la valeur de la constante pi, et vous importez les outils de traçage Matplotlib comme plt comme d'habitude.
Il est recommandé de configurer un graine de générateur aléatoire afin que l'expérience puisse être reproduite à l'identique sur n'importe quelle machine. Pour ce faire dans PyTorch, exécutez le code suivant:
Le nombre 111 représente la graine aléatoire utilisée pour initialiser le générateur de nombres aléatoires, qui est utilisé pour initialiser les poids du réseau neuronal. Malgré le caractère aléatoire de l'expérience, elle doit fournir les mêmes résultats tant que la même graine est utilisée.
Maintenant que l'environnement est défini, vous pouvez préparer les données d'entraînement.
Préparation des données d'entraînement
Les données d'entraînement sont composées de paires (X₁, X₂) pour que X₂ se compose de la valeur du sinus de X₁ pour X₁ dans l'intervalle de 0 à 2π. Vous pouvez l'implémenter comme suit:
1 train_data_length = 1024
2 train_data = torche.zéros((train_data_length, 2))
3 train_data[:[:[:[: 0] = 2 * math.pi * torche.rand(train_data_length)
4 train_data[:[:[:[: 1] = torche.péché(train_data[:[:[:[: 0])
5 train_labels = torche.zéros(train_data_length)
6 train_set = [[[[
7 (train_data[[[[je], train_labels[[[[je]) pour je dans gamme(train_data_length)
8 ]
Ici, vous composez un ensemble d'entraînement avec 1024 paires (X₁, X₂). Dans ligne 2, vous initialisez train_data, un tenseur de dimensions 1024 lignes et 2 colonnes, toutes contenant des zéros. UNE tenseur est un tableau multidimensionnel similaire à un tableau NumPy.
Dans ligne 3, vous utilisez la première colonne de train_data pour stocker des valeurs aléatoires dans l'intervalle de 0 à 2π. Puis dans ligne 4, vous calculez la deuxième colonne du tenseur comme le sinus de la première colonne.
Ensuite, vous aurez besoin d'un tenseur d'étiquettes, requis par le chargeur de données de PyTorch. Puisque les GAN utilisent des techniques d'apprentissage non supervisées, les étiquettes peuvent être n'importe quoi. Ils ne seront pas utilisés, après tout.
Dans ligne 5, tu crées train_labels, un tenseur rempli de zéros. Enfin, dans lignes 6 à 8, tu crées train_set comme une liste de tuples, avec chaque ligne de train_data et train_labels représenté dans chaque tuple comme prévu par le chargeur de données de PyTorch.
Vous pouvez examiner les données d'entraînement en traçant chaque point (X₁, X₂):
plt.terrain(train_data[:[:[:[: 0], train_data[:[:[:[: 1], ".")
La sortie doit être quelque chose de similaire à la figure suivante:

Avec train_set, vous pouvez créer un chargeur de données PyTorch:
taille du lot = 32
train_loader = torche.utils.Les données.DataLoader(
train_set, taille du lot=taille du lot, mélanger=Vrai
)
Ici, vous créez un chargeur de données appelé train_loader, qui mélangera les données de train_set et renvoyer des lots de 32 échantillons que vous utiliserez pour entraîner les réseaux de neurones.
Après avoir configuré les données d'apprentissage, vous devez créer les réseaux de neurones pour le discriminateur et le générateur qui composeront le GAN. Dans la section suivante, vous implémenterez le discriminateur.
Mettre en œuvre le discriminateur
Dans PyTorch, les modèles de réseaux de neurones sont représentés par des classes qui héritent de nn.Module, vous devrez donc définir une classe pour créer le discriminateur. Pour plus d'informations sur la définition des classes, jetez un œil à la programmation orientée objet (POO) dans Python 3.
Le discriminateur est un modèle avec une entrée bidimensionnelle et une sortie unidimensionnelle. Il recevra un échantillon des données réelles ou du générateur et fournira la probabilité que l'échantillon appartienne aux données d'apprentissage réelles. Le code ci-dessous montre comment créer un discriminateur:
1 classe Discriminateur(nn.Module):
2 def __init__(soi):
3 super().__init__()
4 soi.modèle = nn.Séquentiel(
5 nn.Linéaire(2, 256),
6 nn.ReLU(),
7 nn.Abandonner(0,3),
8 nn.Linéaire(256, 128),
9 nn.ReLU(),
dix nn.Abandonner(0,3),
11 nn.Linéaire(128, 64),
12 nn.ReLU(),
13 nn.Abandonner(0,3),
14 nn.Linéaire(64, 1),
15 nn.Sigmoïde(),
16 )
17
18 def vers l'avant(soi, X):
19 production = soi.modèle(X)
20 revenir production
Tu utilises .__ init __ () pour construire le modèle. Tout d'abord, vous devez appeler super () .__ init __ () courir .__ init __ () de nn.Module. Le discriminateur que vous utilisez est un réseau de neurones MLP défini de manière séquentielle en utilisant nn.Séquentiel (). Il présente les caractéristiques suivantes:
-
Lignes 5 et 6: L'entrée est bidimensionnelle et la première couche masquée est composée de
256neurones avec activation ReLU. -
Lignes 8, 9, 11 et 12: Les deuxième et troisième couches cachées sont composées de
128et64neurones, respectivement, avec activation ReLU. -
Lignes 14 et 15: La sortie est composée d'un seul neurone avec une activation sigmoïdale pour représenter une probabilité.
-
Lignes 7, 10 et 13: Après les première, deuxième et troisième couches cachées, vous utilisez la suppression pour éviter le surajustement.
Enfin, vous utilisez .vers l'avant() pour décrire comment la sortie du modèle est calculée. Ici, X représente l'entrée du modèle, qui est un tenseur bidimensionnel. Dans cette mise en œuvre, la sortie est obtenue en alimentant l'entrée X au modèle que vous avez défini sans aucun autre traitement.
Après avoir déclaré la classe discriminante, vous devez instancier un Discriminateur objet:
discriminateur = Discriminateur()
discriminateur représente une instance du réseau neuronal que vous avez défini et est prêt à être formé. Cependant, avant de mettre en œuvre la boucle d'apprentissage, votre GAN a également besoin d'un générateur. Vous en mettrez en œuvre un dans la section suivante.
Implémentation du générateur
Dans les réseaux antagonistes génératifs, le générateur est le modèle qui prend des échantillons d'un espace latent en tant qu'entrée et génère des données ressemblant aux données de l'ensemble d'apprentissage. Dans ce cas, il s'agit d'un modèle avec une entrée bidimensionnelle, qui recevra des points aléatoires (z₁, z₂), et une sortie bidimensionnelle qui doit fournir (X₁, X₂) points ressemblant à ceux des données d'entraînement.
La mise en œuvre est similaire à ce que vous avez fait pour le discriminateur. Tout d'abord, vous devez créer un Générateur classe qui hérite de nn.Module, définissant l'architecture du réseau neuronal, puis vous devez instancier un Générateur objet:
1 classe Générateur(nn.Module):
2 def __init__(soi):
3 super().__init__()
4 soi.modèle = nn.Séquentiel(
5 nn.Linéaire(2, 16),
6 nn.ReLU(),
7 nn.Linéaire(16, 32),
8 nn.ReLU(),
9 nn.Linéaire(32, 2),
dix )
11
12 def vers l'avant(soi, X):
13 production = soi.modèle(X)
14 revenir production
15
16 Générateur = Générateur()
Ici, Générateur représente le réseau neuronal du générateur. Il est composé de deux calques masqués avec 16 et 32 neurones, à la fois avec activation ReLU et une couche d'activation linéaire avec 2 neurones dans la sortie. De cette façon, la sortie sera constituée d'un vecteur avec deux éléments pouvant être n'importe quelle valeur allant de l'infini négatif à l'infini, ce qui représentera (X₁, X₂).
Maintenant que vous avez défini les modèles pour le discriminateur et le générateur, vous êtes prêt à effectuer la formation!
Formation des modèles
Avant d'entraîner les modèles, vous devez configurer certains paramètres à utiliser pendant l'entraînement:
1 g / D = 0,001
2 num_epochs = 300
3 loss_function = nn.BCELoss()
Ici, vous configurez les paramètres suivants:
-
Ligne 1 définit le taux d'apprentissage (
g / D), que vous utiliserez pour adapter les pondérations du réseau. -
Ligne 2 définit le nombre d'époques (
num_epochs), qui définit le nombre de répétitions de l'entraînement utilisant l'ensemble de l'entraînement qui seront effectuées. -
Ligne 3 affecte la variable
loss_functionà la fonction d'entropie croisée binaireBCELoss (), qui est la fonction de perte que vous utiliserez pour entraîner les modèles.
La fonction d'entropie croisée binaire est une fonction de perte appropriée pour l'apprentissage du discriminateur car elle considère une tâche de classification binaire. Il convient également à l'entraînement du générateur car il alimente sa sortie vers le discriminateur, qui fournit une sortie binaire observable.
PyTorch implémente diverses règles de mise à jour du poids pour l'entraînement des modèles dans torch.optim. Vous utiliserez l'algorithme d'Adam pour entraîner les modèles de discriminateur et de générateur. Pour créer les optimiseurs en utilisant torch.optim, exécutez les lignes suivantes:
1 optimizer_discriminator = torche.optim.Adam(discriminateur.paramètres(), g / D=g / D)
2 optimizer_generator = torche.optim.Adam(Générateur.paramètres(), g / D=g / D)
Enfin, vous devez implémenter une boucle d'apprentissage dans laquelle des échantillons d'apprentissage sont envoyés aux modèles et leurs pondérations sont mises à jour pour minimiser la fonction de perte:
1 pour époque dans gamme(num_epochs):
2 pour n, (real_samples, _) dans énumérer(train_loader):
3 # Données pour la formation du discriminateur
4 real_samples_labels = torche.ceux((taille du lot, 1))
5 latent_space_samples = torche.Randn((taille du lot, 2))
6 échantillons_générés = Générateur(latent_space_samples)
7 generated_samples_labels = torche.zéros((taille du lot, 1))
8 all_samples = torche.chat((real_samples, échantillons_générés))
9 all_samples_labels = torche.chat(
dix (real_samples_labels, generated_samples_labels)
11 )
12
13 # Former le discriminateur
14 discriminateur.zero_grad()
15 output_discriminator = discriminateur(all_samples)
16 loss_discriminator = loss_function(
17 output_discriminator, all_samples_labels)
18 loss_discriminator.en arrière()
19 optimizer_discriminator.étape()
20
21 # Données pour l'entraînement du générateur
22 latent_space_samples = torche.Randn((taille du lot, 2))
23
24 # Formation du générateur
25 Générateur.zero_grad()
26 échantillons_générés = Générateur(latent_space_samples)
27 output_discriminator_generated = discriminateur(échantillons_générés)
28 loss_generator = loss_function(
29 output_discriminator_generated, real_samples_labels
30 )
31 loss_generator.en arrière()
32 optimizer_generator.étape()
33
34 # Afficher la perte
35 si époque % dix == 0 et n == taille du lot - 1:
36 impression(F"Époque: époque Perte D.: loss_discriminator")
37 impression(F"Époque: époque Perte G.: loss_generator")
Pour les GAN, vous mettez à jour les paramètres du discriminateur et du générateur à chaque itération d'apprentissage. Comme cela se fait généralement pour tous les réseaux de neurones, le processus d'apprentissage se compose de deux boucles, l'une pour les époques d'apprentissage et l'autre pour les lots de chaque époque. À l'intérieur de la boucle interne, vous commencez à préparer les données pour entraîner le discriminateur:
-
Ligne 2: Vous obtenez les échantillons réels du lot actuel à partir du chargeur de données et les attribuez à
real_samples. Notez que la première dimension du tenseur a le nombre d'éléments égal àtaille du lot. Il s'agit de la manière standard d'organiser les données dans PyTorch, chaque ligne du tenseur représentant un échantillon du lot. -
Ligne 4: Tu utilises
torch.ones ()pour créer des étiquettes avec la valeur1pour les vrais échantillons, puis vous attribuez les étiquettes àreal_samples_labels. -
Lignes 5 et 6: Vous créez les échantillons générés en stockant des données aléatoires dans
latent_space_samples, que vous alimentez ensuite au générateur pour obteniréchantillons_générés. -
Ligne 7: Tu utilises
torch.zeros ()pour attribuer la valeur0aux étiquettes des échantillons générés, puis vous stockez les étiquettes dansgenerated_samples_labels. -
Lignes 8 à 11: Vous concaténez les échantillons et étiquettes réels et générés et les stockez dans
all_samplesetall_samples_labels, que vous utiliserez pour former le discriminateur.
Ensuite, dans lignes 14 à 19, vous formez le discriminateur:
-
Ligne 14: Dans PyTorch, il est nécessaire d'effacer les dégradés à chaque étape d'entraînement pour éviter de les accumuler. Vous faites cela en utilisant
.zero_grad (). -
Ligne 15: Vous calculez la sortie du discriminateur à l'aide des données d'apprentissage dans
all_samples. -
Lignes 16 et 17: Vous calculez la fonction de perte en utilisant la sortie du modèle dans
output_discriminatoret les étiquettes dansall_samples_labels. -
Ligne 18: Vous calculez les dégradés pour mettre à jour les poids avec
loss_discriminator.backward (). -
Ligne 19: Vous mettez à jour les poids du discriminateur en appelant
optimizer_discriminator.step ().
Ensuite, dans ligne 22, vous préparez les données pour entraîner le générateur. Vous stockez des données aléatoires dans latent_space_samples, avec un nombre de lignes égal à taille du lot. Vous utilisez deux colonnes car vous fournissez des données bidimensionnelles en entrée du générateur.
Vous entraînez le générateur à lignes 25 à 32:
-
Ligne 25: Vous effacez les dégradés avec
.zero_grad (). -
Ligne 26: Vous alimentez le générateur avec
latent_space_sampleset stocker sa sortie danséchantillons_générés. -
Ligne 27: Vous alimentez la sortie du générateur dans le discriminateur et stockez sa sortie dans
output_discriminator_generated, que vous utiliserez comme sortie de l'ensemble du modèle. -
Lignes 28 à 30: Vous calculez la fonction de perte à l'aide de la sortie du système de classification stockée dans
output_discriminator_generatedet les étiquettes dansreal_samples_labels, qui sont tous égaux à1. -
Lignes 31 et 32: Vous calculez les gradients et mettez à jour les poids du générateur. N'oubliez pas que lorsque vous avez formé le générateur, vous avez gelé les poids du discriminateur depuis que vous avez créé
optimizer_generatoravec son premier argument égal àgenerateur.paramètres ().
Enfin, sur lignes 35 à 37, vous affichez les valeurs des fonctions de discrimination et de perte du générateur à la fin de chaque dix époques.
Comme les modèles utilisés dans cet exemple ont peu de paramètres, la formation sera terminée en quelques minutes. Dans la section suivante, vous utiliserez le GAN formé pour générer des échantillons.
Vérification des échantillons générés par le GAN
Les réseaux antagonistes génératifs sont conçus pour générer des données. Ainsi, une fois le processus d'apprentissage terminé, vous pouvez obtenir des échantillons aléatoires de l'espace latent et les envoyer au générateur pour obtenir des échantillons générés:
latent_space_samples = torche.Randn(100, 2)
échantillons_générés = Générateur(latent_space_samples)
Ensuite, vous pouvez tracer les échantillons générés et vérifier s'ils ressemblent aux données d'apprentissage. Avant de tracer le échantillons_générés données, vous devrez utiliser .détacher() pour renvoyer un tenseur du graphe de calcul PyTorch, que vous utiliserez ensuite pour calculer les gradients:
échantillons_générés = échantillons_générés.détacher()
plt.terrain(échantillons_générés[:[:[:[: 0], échantillons_générés[:[:[:[: 1], ".")
La sortie doit être similaire à la figure suivante:
Vous pouvez voir que la distribution des données générées ressemble à celle des données réelles. En utilisant un tenseur d'échantillons d'espace latent fixe et en le transmettant au générateur à la fin de chaque époque pendant le processus d'entraînement, vous pouvez visualiser l'évolution de l'entraînement:

Notez qu'au début du processus d'apprentissage, la distribution des données générées est très différente des données réelles. Cependant, à mesure que la formation progresse, le générateur apprend la distribution réelle des données.
Maintenant que vous avez effectué votre première implémentation d'un réseau antagoniste génératif, vous allez passer par une application plus pratique utilisant des images.
Générateur de chiffres manuscrits avec un GAN
Les réseaux antagonistes génératifs peuvent également générer des échantillons de grande dimension tels que des images. Dans cet exemple, vous allez utiliser un GAN pour générer des images de chiffres manuscrits. Pour cela, vous allez entraîner les modèles à l'aide de l'ensemble de données MNIST de chiffres manuscrits, qui est inclus dans le torchvision paquet.
Pour commencer, vous devez installer torchvision dans le activé gan environnement conda:
$ conda installer -c pytorch torchvision=0.5.0
Encore une fois, vous utilisez une version spécifique de torchvision pour vous assurer que l'exemple de code fonctionnera, comme vous l'avez fait avec pytorche. Une fois l'environnement configuré, vous pouvez commencer à implémenter les modèles dans Jupyter Notebook. Ouvrez-le et créez un nouveau notebook en cliquant sur Nouveau puis en sélectionnant gan.
Comme dans l'exemple précédent, vous commencez par importer les bibliothèques nécessaires:
importer torche
de torche importer nn
importer math
importer matplotlib.pyplot comme plt
importer torchvision
importer torchvision.transforms comme se transforme
Outre les bibliothèques que vous avez importées auparavant, vous aurez besoin torchvision et se transforme pour obtenir les données d'entraînement et effectuer des conversions d'image.
Encore une fois, configurez la graine du générateur aléatoire pour pouvoir répliquer l'expérience:
Étant donné que cet exemple utilise des images dans l'ensemble d'apprentissage, les modèles doivent être plus complexes, avec un plus grand nombre de paramètres. Cela rend le processus de formation plus lent, prenant environ deux minutes par époque lors de l'exécution sur le processeur. Vous aurez besoin d’une cinquantaine d’époques pour obtenir un résultat pertinent, de sorte que le temps d’entraînement total lors de l’utilisation d’un processeur est d’une centaine de minutes.
Pour réduire le temps de formation, vous pouvez utiliser un GPU pour entraîner le modèle si vous en avez un disponible. Cependant, vous devrez déplacer manuellement les tenseurs et les modèles vers le GPU afin de les utiliser dans le processus d'entraînement.
Vous pouvez vous assurer que votre code fonctionnera sur l'une ou l'autre des configurations en créant un dispositif objet qui pointe soit vers le CPU, soit, le cas échéant, vers le GPU:
dispositif = ""
si torche.cuda.est disponible():
dispositif = torche.dispositif("cuda")
autre:
dispositif = torche.dispositif("CPU")
Plus tard, vous utiliserez ceci dispositif pour définir où les tenseurs et les modèles doivent être créés, en utilisant le GPU si disponible.
Maintenant que l'environnement de base est défini, vous pouvez préparer les données d'entraînement.
Préparation des données d'entraînement
L'ensemble de données MNIST se compose d'images en niveaux de gris 28 × 28 pixels de chiffres manuscrits de 0 à 9. Pour les utiliser avec PyTorch, vous devrez effectuer des conversions. Pour cela, vous définissez transformer, une fonction à utiliser lors du chargement des données:
transformer = se transforme.Composer(
[[[[se transforme.ToTensor(), se transforme.Normaliser((0,5,), (0,5,))]
)
La fonction comprend deux parties:
transforms.ToTensor ()convertit les données en un tenseur PyTorch.transforms.Normaliser ()convertit la plage des coefficients du tenseur.
Les coefficients originaux donnés par transforms.ToTensor () compris entre 0 et 1, et comme les arrière-plans de l'image sont noirs, la plupart des coefficients sont égaux à 0 lorsqu'ils sont représentés à l'aide de cette plage.
transforms.Normaliser () change la plage des coefficients de -1 à 1 en soustrayant 0,5 à partir des coefficients d'origine et en divisant le résultat par 0,5. Avec cette transformation, le nombre d'éléments égal à 0 dans les échantillons d'entrée est considérablement réduit, ce qui facilite la formation des modèles.
Les arguments de transforms.Normaliser () sont deux tuples, (M₁, ..., Mₙ) et (S₁, ..., Sₙ), avec n représentant le nombre de canaux des images. Les images en niveaux de gris telles que celles de l'ensemble de données MNIST n'ont qu'un seul canal, les tuples n'ont donc qu'une seule valeur. Ensuite, pour chaque canal je de l'image, transforms.Normaliser () soustrait Mᵢ à partir des coefficients et divise le résultat par Sᵢ.
Vous pouvez maintenant charger les données d'entraînement en utilisant torchvision.datasets.MNIST et effectuez les conversions en utilisant transformer:
train_set = torchvision.ensembles de données.MNIST(
racine=".", train=Vrai, Télécharger=Vrai, transformer=transformer
)
L'argument download = True garantit que la première fois que vous exécutez le code ci-dessus, l'ensemble de données MNIST sera téléchargé et stocké dans le répertoire actuel, comme indiqué par l'argument racine.
Maintenant que vous avez créé train_set, vous pouvez créer le chargeur de données comme vous l'avez fait auparavant:
taille du lot = 32
train_loader = torche.utils.Les données.DataLoader(
train_set, taille du lot=taille du lot, mélanger=Vrai
)
Vous pouvez utiliser Matplotlib pour tracer des échantillons des données d'entraînement. Pour améliorer la visualisation, vous pouvez utiliser cmap = gray_r pour inverser la carte des couleurs et tracer les chiffres en noir sur fond blanc:
real_samples, mnist_labels = suivant(iter(train_loader))
pour je dans gamme(16):
hache = plt.sous-tracé(4, 4, je + 1)
plt.imshow(real_samples[[[[je].remodeler(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
La sortie doit être quelque chose de similaire à ce qui suit:

Comme vous pouvez le voir, il existe des chiffres avec différents styles d'écriture manuscrite. Au fur et à mesure que le GAN apprend la distribution des données, il génère également des chiffres avec différents styles d'écriture manuscrite.
Maintenant que vous avez préparé les données d'entraînement, vous pouvez implémenter les modèles de discriminateur et de générateur.
Mettre en œuvre le discriminateur et le générateur
Dans ce cas, le discriminateur est un réseau de neurones MLP qui reçoit une image de 28 x 28 pixels et fournit la probabilité que l'image appartienne aux données d'apprentissage réelles.
Vous pouvez définir le modèle avec le code suivant:
1 classe Discriminateur(nn.Module):
2 def __init__(soi):
3 super().__init__()
4 soi.modèle = nn.Séquentiel(
5 nn.Linéaire(784, 1024),
6 nn.ReLU(),
7 nn.Abandonner(0,3),
8 nn.Linéaire(1024, 512),
9 nn.ReLU(),
dix nn.Abandonner(0,3),
11 nn.Linéaire(512, 256),
12 nn.ReLU(),
13 nn.Abandonner(0,3),
14 nn.Linéaire(256, 1),
15 nn.Sigmoïde(),
16 )
17
18 def vers l'avant(soi, X):
19 X = X.vue(X.Taille(0), 784)
20 production = soi.modèle(X)
21 revenir production
Pour entrer les coefficients d'image dans le réseau de neurones MLP, vous les vectorisez afin que le réseau de neurones reçoive des vecteurs avec 784 coefficients.
La vectorisation se produit dans la première ligne de .vers l'avant(), comme l'appel à x.view () convertit la forme du tenseur d'entrée. Dans ce cas, la forme d'origine de l'entrée X est 32 × 1 × 28 × 28, où 32 est la taille de lot que vous avez définie. Après la conversion, la forme de X devient 32 x 784, chaque ligne représentant les coefficients d'une image de l'ensemble d'apprentissage.
To run the discriminator model using the GPU, you have to instantiate it and send it to the GPU with .to(). To use a GPU when there’s one available, you can send the model to the device object you created earlier:
discriminator = Discriminator().à(device=device)
Since the generator is going to generate more complex data, it’s necessary to increase the dimensions of the input from the latent space. In this case, the generator is going to be fed a 100-dimensional input and will provide an output with 784 coefficients, which will be organized in a 28 × 28 tensor representing an image.
Here’s the complete generator model code:
1 class Générateur(nn.Module):
2 def __init__(soi):
3 super().__init__()
4 soi.model = nn.Séquentiel(
5 nn.Linear(100, 256),
6 nn.ReLU(),
7 nn.Linear(256, 512),
8 nn.ReLU(),
9 nn.Linear(512, 1024),
dix nn.ReLU(),
11 nn.Linear(1024, 784),
12 nn.Tanh(),
13 )
14
15 def vers l'avant(soi, X):
16 output = soi.model(X)
17 output = output.vue(X.size(0), 1, 28, 28)
18 return output
19
20 generator = Générateur().à(device=device)
Dans line 12, you use the hyperbolic tangent function Tanh() as the activation of the output layer since the output coefficients should be in the interval from -1 to 1. In line 20, you instantiate the generator and send it to device to use the GPU if one is available.
Now that you have the models defined, you’ll train them using the training data.
Training the Models
To train the models, you need to define the training parameters and optimizers like you did in the previous example:
lr = 0.0001
num_epochs = 50
loss_function = nn.BCELoss()
optimizer_discriminator = torch.optim.Adam(discriminator.parameters(), lr=lr)
optimizer_generator = torch.optim.Adam(generator.parameters(), lr=lr)
To obtain a better result, you decrease the learning rate from the previous example. You also set the number of epochs to 50 to reduce the training time.
The training loop is very similar to the one you used in the previous example. In the highlighted lines, you send the training data to device to use the GPU if available:
1 pour epoch dans range(num_epochs):
2 pour n, (real_samples, mnist_labels) dans enumerate(train_loader):
3 # Data for training the discriminator
4 real_samples = real_samples.à(device=device)
5 real_samples_labels = torch.ones((batch_size, 1)).à(
6 device=device
7 )
8 latent_space_samples = torch.randn((batch_size, 100)).à(
9 device=device
dix )
11 generated_samples = generator(latent_space_samples)
12 generated_samples_labels = torch.zeros((batch_size, 1)).à(
13 device=device
14 )
15 all_samples = torch.cat((real_samples, generated_samples))
16 all_samples_labels = torch.cat(
17 (real_samples_labels, generated_samples_labels)
18 )
19
20 # Training the discriminator
21 discriminator.zero_grad()
22 output_discriminator = discriminator(all_samples)
23 loss_discriminator = loss_function(
24 output_discriminator, all_samples_labels
25 )
26 loss_discriminator.backward()
27 optimizer_discriminator.step()
28
29 # Data for training the generator
30 latent_space_samples = torch.randn((batch_size, 100)).à(
31 device=device
32 )
33
34 # Training the generator
35 generator.zero_grad()
36 generated_samples = generator(latent_space_samples)
37 output_discriminator_generated = discriminator(generated_samples)
38 loss_generator = loss_function(
39 output_discriminator_generated, real_samples_labels
40 )
41 loss_generator.backward()
42 optimizer_generator.step()
43
44 # Show loss
45 si n == batch_size - 1:
46 impression(f"Epoch: epoch Loss D.: loss_discriminator")
47 impression(f"Epoch: epoch Loss G.: loss_generator")
Some of the tensors don’t need to be sent to the GPU explicitly with device. This is the case with generated_samples dans line 11, which will already be sent to an available GPU since latent_space_samples et generator were sent to the GPU previously.
Since this example features more complex models, the training may take a bit more time. After it finishes, you can check the results by generating some samples of handwritten digits.
Checking the Samples Generated by the GAN
To generate handwritten digits, you have to take some random samples from the latent space and feed them to the generator:
latent_space_samples = torch.randn(batch_size, 100).à(device=device)
generated_samples = generator(latent_space_samples)
To plot generated_samples, you need to move the data back to the CPU in case it’s running on the GPU. For that, you can simply call .cpu(). As you did previously, you also need to call .detach() before using Matplotlib to plot the data:
generated_samples = generated_samples.cpu().detach()
pour je dans range(16):
ax = plt.subplot(4, 4, je + 1)
plt.imshow(generated_samples[[[[je].reshape(28, 28), cmap="gray_r")
plt.xticks([])
plt.yticks([])
The output should be digits resembling the training data, as in the following figure:

After fifty epochs of training, there are several generated digits that resemble the real ones. You can improve the results by considering more training epochs. As with the previous example, by using a fixed latent space samples tensor and feeding it to the generator at the end of each epoch during the training process, you can visualize the evolution of the training:

You can see that at the beginning of the training process, the generated images are completely random. As the training progresses, the generator learns the distribution of the real data, and at about twenty epochs, some generated digits already resemble real data.
Conclusion
Toutes nos félicitations! You’ve learned how to implement your own generative adversarial networks. You first went through a toy example to understand the GAN structure before diving into a practical application that generates images of handwritten digits.
You saw that, despite the complexity of GANs, machine learning frameworks like PyTorch make the implementation more straightforward by offering automatic differentiation and easy GPU setup.
In this tutorial, you learned:
- What the difference is between discriminative et generative models
- How generative adversarial networks are structured et trained
- How to use tools like PyTorch et un GPU to implement and train GAN models
GANs are a very active research topic, with several exciting applications proposed in recent years. If you’re interested in the subject, keep an eye on the technical and scientific literature to check for new application ideas.
Lectures complémentaires
Now that you know the basics of using generative adversarial networks, you can start studying more elaborate applications. The following books are a great way to deepen your knowledge:
It’s worth mentioning that machine learning is a broad subject, and there are a lot of different model structures besides generative adversarial networks. For more information on machine learning, check out the following resources:
There’s so much to learn in the world of machine learning. Keep studying and feel free to leave any questions or comments below!
[ad_2]