Formation Python
- WooCommerce 4.0 est là, mais faites attention avant de mettre à jour • WPShout
- Quel hôte gagne en 2020?
- Comment créer des modèles de page personnalisés WordPress (et pourquoi) • WPShout
- Épisode # 317 Python à la commission électorale fédérale américaine
- 30+ meilleurs thèmes de styles news et magazines pour WordPress
Manipuler des encodages de caractères en Python ou dans une autre langue peut parfois sembler douloureux. Des endroits tels que Stack Overflow posent des milliers de questions découlant de la confusion suscitée par des exceptions telles que UnicodeDecodeError et UnicodeEncodeError. Ce tutoriel est conçu pour effacer les Exception brouillard et illustrer que travailler avec du texte et des données binaires dans Python 3 peut être une expérience fluide. La prise en charge de Python Unicode est forte et robuste, mais sa maîtrise est longue.
Ce tutoriel est différent car il n’est pas indépendant de la langue, mais délibérément centré sur Python. Vous aurez toujours un aperçu de la langue, mais vous plongerez ensuite dans les illustrations en Python, avec des paragraphes contenant beaucoup de texte au minimum. Vous verrez comment utiliser les concepts d’encodage de caractères dans du code Python en direct.
À la fin de ce tutoriel, vous allez:
- Obtenez des aperçus conceptuels sur les encodages de caractères et les systèmes de numérotation
- Comprendre comment l’encodage entre en jeu avec Python
stretoctets - Connaître le support en Python pour les systèmes de numérotation à travers ses différentes formes de
intlittéraux - Familiarisez-vous avec les fonctions intégrées de Python relatives aux encodages de caractères et aux systèmes de numérotation
Les systèmes de codage et de numérotation des caractères sont si étroitement liés qu'ils doivent être abordés dans le même tutoriel, sans quoi leur traitement serait totalement inadéquat.
Remarque: Cet article est centré sur Python 3. Plus précisément, tous les exemples de code de ce didacticiel ont été générés à partir d’un shell CPython 3.7.2, bien que toutes les versions mineures de Python 3 devraient se comporter (généralement) de la même manière dans leur traitement de texte.
Si vous utilisez toujours Python 2 et que vous êtes intimidé par les différences de traitement des données texte et binaires par Python 2 et Python 3, nous espérons que ce tutoriel vous aidera à effectuer le changement.
Qu'est-ce qu'un encodage de personnage?
Il existe des dizaines voire des centaines de codages de caractères. La meilleure façon de commencer à comprendre ce qu’ils sont est de couvrir l’un des encodages de caractères les plus simples, ASCII.
Autodidacte ou formation en informatique, il est probable que vous ayez déjà vu un tableau ASCII une ou deux fois. L’ASCII est un bon endroit pour commencer à apprendre le codage de caractères car c’est un codage petit et contenu. (Trop petit, en fin de compte.)
Il comprend les éléments suivants:
- Lettres anglaises minuscules: une à travers z
- Lettres anglaises majuscules: UNE à travers Z
- Quelques signes de ponctuation et symboles:
"$"et"!", pour nommer un couple - Caractères blancs: un espace réel (
""), ainsi qu’une nouvelle ligne, un retour à la ligne, une tabulation horizontale, une tabulation verticale et quelques autres - Quelques caractères non imprimables: caractères tels que retour arrière,
" b", qui ne peut être imprimé littéralement de la même manière que la lettre UNE pouvez
Alors, quelle est une définition plus formelle d'un encodage de caractères?
À un niveau très élevé, c’est un moyen de traduire des caractères (tels que des lettres, des signes de ponctuation, des symboles, des espaces et des caractères de contrôle) en entiers et finalement en bits. Chaque caractère peut être codé en une séquence unique de bits. Ne vous inquiétez pas si vous êtes chancelant sur le concept de bits, car nous y arriverons sous peu.
Les différentes catégories décrites représentent des groupes de caractères. Chaque personnage a un correspondant point de code, que vous pouvez considérer comme juste un entier. Les caractères sont segmentés en différentes plages dans la table ASCII:
| Plage de points de code | Classe |
|---|---|
| 0 à 31 | Caractères de contrôle / non imprimables |
| 32 à 64 | Ponctuation, symboles, nombres et espace |
| 65 à 90 | Lettres majuscules de l'alphabet anglais |
| 91 à 96 | Graphèmes supplémentaires, tels que [[[[ et |
| 97 à 122 | Lettres de l'alphabet anglais minuscule |
| 123 à 126 | Graphèmes supplémentaires, tels que { et | |
| 127 | Caractère de contrôle / non imprimable (DEL) |
La table ASCII entière contient 128 caractères. Ce tableau capture la complète jeu de caractères que ASCII permet. Si vous ne voyez pas de caractère ici, vous ne pouvez simplement pas l’exprimer sous forme de texte imprimé dans le schéma de codage ASCII.
| Point de code | Le nom du personnage) | Point de code | Le nom du personnage) |
|---|---|---|---|
| 0 | NUL (Null) | 64 | @ |
| 1 | SOH (début de rubrique) | 65 | UNE |
| 2 | STX (début du texte) | 66 | B |
| 3 | ETX (fin du texte) | 67 | C |
| 4 | EOT (fin de transmission) | 68 | ré |
| 5 | ENQ (enquête) | 69 | E |
| 6 | ACK (accusé de réception) | 70 | F |
| 7 | BEL (Bell) | 71 | g |
| 8 | BS (Backspace) | 72 | H |
| 9 | HT (onglet horizontal) | 73 | je |
| dix | LF (saut de ligne) | 74 | J |
| 11 | VT (onglet vertical) | 75 | K |
| 12 | FF (Form Feed) | 76 | L |
| 13 | CR (retour chariot) | 77 | M |
| 14 | SO (Shift Out) | 78 | N |
| 15 | SI (déplacer dans) | 79 | O |
| 16 | DLE (Data Link Escape) | 80 | P |
| 17 | DC1 (Contrôle de périphérique 1) | 81 | Q |
| 18 | DC2 (Device Control 2) | 82 | R |
| 19 | DC3 (Device Control 3) | 83 | S |
| 20 | DC4 (Device Control 4) | 84 | T |
| 21 | NAK (accusé de réception négatif) | 85 | U |
| 22 | SYN (ralenti synchrone) | 86 | V |
| 23 | ETB (fin de transmission) | 87 | W |
| 24 | CAN (Annuler) | 88 | X |
| 25 | EM (fin du milieu) | 89 | Y |
| 26 | SUB (Substitute) | 90 | Z |
| 27 | ESC (échapper) | 91 | [[[[ |
| 28 | FS (séparateur de fichiers) | 92 | |
| 29 | GS (séparateur de groupe) | 93 | ] |
| 30 | RS (séparateur d'enregistrement) | 94 | ^ |
| 31 | US (séparateur d'unité) | 95 | _ |
| 32 | SP (espace) | 96 | ` |
| 33 | ! |
97 | une |
| 34 | " |
98 | b |
| 35 | # |
99 | c |
| 36 | $ |
100 | ré |
| 37 | % |
101 | e |
| 38 | Et |
102 | F |
| 39 | ' |
103 | g |
| 40 | ( |
104 | h |
| 41 | ) |
105 | je |
| 42 | * |
106 | j |
| 43 | + |
107 | k |
| 44 | , |
108 | l |
| 45 | - |
109 | m |
| 46 | . |
110 | n |
| 47 | / |
111 | o |
| 48 | 0 |
112 | p |
| 49 | 1 |
113 | q |
| 50 | 2 |
114 | r |
| 51 | 3 |
115 | s |
| 52 | 4 |
116 | t |
| 53 | 5 |
117 | vous |
| 54 | 6 |
118 | v |
| 55 | 7 |
119 | w |
| 56 | 8 |
120 | X |
| 57 | 9 |
121 | y |
| 58 | : |
122 | z |
| 59 | ; |
123 | |
| 61 | = |
125 | |
| 62 | > |
126 | ~ |
| 63 | ? |
127 | DEL (supprimer) |
le chaîne Module
Python chaîne Le module est un guichet unique pratique pour les constantes de chaîne qui entrent dans le jeu de caractères ASCII.
Voici le cœur du module dans toute sa splendeur:
# De lib / python3.7 / string.py
les espaces = ' t n r v f'
ascii_lowercase = 'abcdefghijklmnopqrstuvwxyz'
ascii_uppercase = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'
ascii_letters = ascii_lowercase + ascii_uppercase
chiffres = '0123456789'
hexdigits = chiffres + 'a B c d e F' + 'A B C D E F'
octdigits = '01234567'
ponctuation = r"" "!" # $% & '() * +, -. / :;<=>? @[]^ _` ~ "" "
imprimable = chiffres + ascii_letters + ponctuation + les espaces
La plupart de ces constantes devraient s'auto-documenter dans leur nom d'identifiant. Nous couvrirons quoi hexdigits et octdigits sont sous peu.
Vous pouvez utiliser ces constantes pour la manipulation quotidienne des chaînes:
>>> importation chaîne
>>> s = "Qu'est-ce qui ne va pas avec ASCII?!?!?"
>>> s.bande de retour(chaîne.ponctuation)
'Quel est le problème avec ASCII'
Remarque: string.printable comprend tous string.whitespace. Ceci est légèrement en désaccord avec une autre méthode pour tester si un personnage est considéré comme imprimable, à savoir: str.isprintable (), ce qui vous dira qu'aucun des ' v', ' n', ' r', ' f', ' t' sont considérés comme imprimables.
La différence subtile est due à la définition: str.isprintable () considère quelque chose d’imprimable si “tous ses caractères sont considérés comme imprimables repr (). "
Un peu de recyclage
C’est le bon moment pour un bref rappel sur le bit, l'unité d'information la plus fondamentale qu'un ordinateur connaisse.
Un bit est un signal qui n'a que deux états possibles. Il y a différentes façons de représenter symboliquement un bit qui signifie la même chose:
- 0 ou 1
- "Oui ou non"
VraiouFaux- "Allumé ou éteint"
Notre tableau ASCII de la section précédente utilise ce que vous et moi appellerions simplement des nombres (0 à 127), mais qui sont plus précisément appelés nombres en base 10 (décimal).
Vous pouvez également exprimer chacun de ces nombres en base 10 avec une séquence de bits (base 2). Voici les versions binaires de 0 à 10 en décimal:
| Décimal | Binaire (compact) | Binaire (forme rembourrée) |
|---|---|---|
| 0 | 0 | 00000000 |
| 1 | 1 | 00000001 |
| 2 | dix | 00000010 |
| 3 | 11 | 00000011 |
| 4 | 100 | 00000100 |
| 5 | 101 | 00000101 |
| 6 | 110 | 00000110 |
| 7 | 111 | 00000111 |
| 8 | 1000 | 00001000 |
| 9 | 1001 | 00001001 |
| dix | 1010 | 00001010 |
Notez que comme le nombre décimal n augmente, il faut plus bits significatifs pour représenter le caractère configuré pour inclure ce nombre.
Voici un moyen pratique de représenter les chaînes ASCII sous forme de séquences de bits en Python. Chaque caractère de la chaîne ASCII reçoit un pseudo-codage sur 8 bits, avec des espaces entre les séquences de 8 bits représentant chacun un seul caractère:
>>> def make_bitseq(s: str) -> str:
... si ne pas s.isascii():
... élever ValueError("ASCII seulement autorisé")
... revenir "".joindre(F"ord (i): 08b" pour je dans s)
>>> make_bitseq("morceaux")
'01100010 01101001 01110100 01110011'
>>> make_bitseq("CASQUETTES")
'01000011 01000001 01010000 01010011'
>>> make_bitseq("$ 25.43")
'00100100 00110010 00110101 00101110 00110100 00110011'
>>> make_bitseq("~ 5")
'01111110 00110101'
Remarque: .isascii () a été introduit dans Python 3.7.
Le f-string f "ord (i): 08b" utilise le mini-langage de spécification de format de Python, qui permet de spécifier le formatage des champs de remplacement dans les chaînes de format:
-
Le côté gauche du côlon,
ord (i), est l’objet dont la valeur sera formatée et insérée dans la sortie. En utilisantord ()vous donne le point de code base 10 pour un seulstrpersonnage. -
Le côté droit des deux-points est le spécificateur de format.
08veux dire largeur 8, 0 rembourré, et lebfonctionne comme un signe pour afficher le nombre obtenu en base 2 (binaire).
Cette astuce est principalement juste pour le plaisir, et elle échouera très mal pour tout personnage que vous ne voyez pas présent dans la table ASCII. Nous verrons plus tard comment d’autres encodages corrigent ce problème.
Nous avons besoin de plus de bits!
Il existe une formule extrêmement importante liée à la définition d’un bit. Étant donné un nombre de bits, n, le nombre de valeurs possibles distinctes pouvant être représentées dans n bits est 2n:
def n_possible_values(nbits: int) -> int:
revenir 2 ** nbits
Voici ce que cela signifie:
- 1 bit vous permettra d'exprimer 21 == 2 valeurs possibles.
- 8 bits vous permettront d'exprimer 28 == 256 valeurs possibles.
- 64 bits vous permettront d'exprimer 264 == 18 446 744 073 709 551 616 valeurs possibles.
Il existe un corollaire à cette formule: étant donné une plage de valeurs possibles différentes, comment trouver le nombre de bits, n, que faut-il pour que la gamme soit pleinement représentée? Ce que vous essayez de résoudre, c’est n dans l'équation 2n = x (où tu sais déjà X).
Voici ce que cela signifie:
>>> de math importation plafond, bûche
>>> def n_bits_requis(nvalues: int) -> int:
... revenir plafond(bûche(nvalues) / bûche(2))
>>> n_bits_requis(256)
8
La raison pour laquelle vous devez utiliser un plafond dans n_bits_required () est de prendre en compte les valeurs qui ne sont pas des puissances propres de 2. Disons que vous devez stocker un jeu de caractères de 110 caractères au total. Naïvement, cela devrait prendre log (110) / log (2) == 6.781 bits, mais il n’existe pas de 0.781 bits. 110 valeurs nécessiteront 7 bits, pas 6, les derniers emplacements étant inutiles:
>>> n_bits_requis(110)
7
Tout cela sert à prouver un concept: ASCII est, à proprement parler, un code à 7 bits. La table ASCII que vous avez vue ci-dessus contient 128 points de code et caractères, compris entre 0 et 127. Cela nécessite 7 bits:
>>> n_bits_requis(128) # 0 à 127
7
>>> n_possible_values(7)
128
Le problème, c’est que les ordinateurs modernes ne stockent pas grand-chose dans des emplacements 7 bits. Ils traitent en unités de 8 bits, classiquement appelées un octet.
Remarque: Tout au long de ce tutoriel, je suppose qu'un octet fait référence à 8 bits, comme il le fait depuis les années 1960, plutôt qu'à une autre unité de stockage. Vous êtes libre d'appeler cela un octuor si tu préfères.
Cela signifie que l'espace de stockage utilisé par ASCII est à moitié vide. Si la raison n’est pas claire, repensez à la table décimale à binaire présentée ci-dessus. Vous pouvez exprimer les nombres 0 et 1 avec 1 bit seulement, ou vous pouvez utiliser 8 bits pour les exprimer respectivement 00000000 et 00000001.
Vous pouvez exprimer les nombres 0 à 3 avec seulement 2 bits, ou 00 à 11, ou vous pouvez utiliser 8 bits pour les exprimer respectivement 00000000, 00000001, 00000010 et 00000011. Le point de code ASCII le plus élevé, 127, ne requiert que 7 bits significatifs.
Sachant cela, vous pouvez voir que make_bitseq () convertit les chaînes ASCII en un str représentation d'octets, où chaque caractère consomme un octet:
>>> make_bitseq("morceaux")
'01100010 01101001 01110100 01110011'
La sous-utilisation par ASCII des octets de 8 bits offerts par les ordinateurs modernes a conduit à une famille de codages informels conflictuels, chacun spécifiant des caractères supplémentaires à utiliser avec les 128 points de code restants autorisés dans un schéma de codage de caractères à 8 bits.
Non seulement ces différents codages se sont-ils heurtés, mais chacun d’eux était en soi une représentation grossièrement incomplète des personnages du monde, indépendamment du fait qu’ils utilisaient un bit supplémentaire.
Au fil des ans, un méga-schéma d'encodage de caractères est venu les gouverner tous. Cependant, avant d’y arriver, parlons un instant des systèmes de numérotation, qui sont à la base des schémas de codage de caractères.
Couvrant toutes les bases: Autres systèmes de numération
Dans la discussion sur ASCII ci-dessus, vous avez vu que chaque caractère correspond à un entier compris entre 0 et 127.
Cette plage de nombres est exprimée en décimal (base 10). C’est la façon dont vous, moi et le reste d’entre nous sommes habitués à compter, sans aucune raison plus compliquée que celle que nous avons 10 doigts.
Mais il existe également d'autres systèmes de numérotation qui sont particulièrement répandus dans le code source de CPython. Bien que le «numéro sous-jacent» soit le même, tous les systèmes de numérotation ne sont que des façons différentes d’exprimer le même nombre.
Si je vous ai demandé quel numéro la chaîne "11" vous avez raison de me jeter un regard étrange avant de répondre qu’il en représente onze.
Toutefois, cette représentation sous forme de chaîne peut exprimer différents numéros sous-jacents dans différents systèmes de numérotation. En plus du nombre décimal, les solutions de rechange incluent les systèmes de numérotation courants suivants:
- Binaire: base 2
- Octal: base 8
- Hexadécimal (hex): base 16
Mais que signifie pour nous de dire que, dans un certain système de numérotation, les nombres sont représentés en base N?
À mon avis, c’est la meilleure façon d’exprimer ce que cela signifie: c’est le nombre de doigts sur lequel vous pouvez compter dans ce système.
Si vous souhaitez une introduction beaucoup plus complète, mais tout en douceur, aux systèmes de numérotation, le logiciel de Charles Petzold Code est un livre incroyablement cool qui explore en détail les fondements du code informatique.
Une façon de montrer comment différents systèmes de numérotation interprètent la même chose consiste à utiliser Python. int () constructeur. Si vous passez un str à int (), Python supposera par défaut que la chaîne exprime un nombre en base 10, sauf indication contraire de votre part:
>>> int('11')
11
>>> int('11', base=dix) # 10 est déjà la valeur par défaut
11
>>> int('11', base=2) # Binaire
3
>>> int('11', base=8) # Octal
9
>>> int('11', base=16) # Hex
17
Il existe un moyen plus courant de dire à Python que votre entier est saisi dans une base autre que 10. Python accepte littéral formes de chacun des 3 systèmes de numérotation alternatifs ci-dessus:
| Type de littéral | Préfixe | Exemple |
|---|---|---|
| n / a | n / a | 11 |
| Littéral binaire | 0b ou 0B |
0b11 |
| Littéral octal | 0o ou 0O |
0o11 |
| Hex littéral | 0x ou 0X |
0x11 |
Tous sont des sous-formes de littéraux entiers. Vous pouvez voir que ceux-ci produisent les mêmes résultats, respectivement, que les appels à int () avec non-défaut base valeurs. Ils sont tous juste int à Python:
>>> 11
11
>>> 0b11 # Littéral binaire
3
>>> 0o11 # Littéral octal
9
>>> 0x11 # Hex littéral
17
Voici comment vous pouvez taper les équivalents binaire, octal et hexadécimal des nombres décimaux 0 à 20. Tous ces éléments sont parfaitement valables dans un interpréteur Python ou dans un code source, et tous s’affichent comme étant de type. int:
| Décimal | Binaire | Octal | Hex |
|---|---|---|---|
0 |
0b0 |
0o0 |
0x0 |
1 |
0b1 |
0o1 |
0x1 |
2 |
0b10 |
0o2 |
0x2 |
3 |
0b11 |
0o3 |
0x3 |
4 |
0b100 |
0o4 |
0x4 |
5 |
0b101 |
0o5 |
0x5 |
6 |
0b110 |
0o6 |
0x6 |
7 |
0b111 |
0o7 |
0x7 |
8 |
0b1000 |
0o10 |
0x8 |
9 |
0b1001 |
0o11 |
0x9 |
dix |
0b1010 |
0o12 |
0xa |
11 |
0b1011 |
0o13 |
0xb |
12 |
0b1100 |
0o14 |
0xc |
13 |
0b1101 |
0o15 |
0xd |
14 |
0b1110 |
0o16 |
0xe |
15 |
0b1111 |
0o17 |
0xf |
16 |
0b10000 |
0o20 |
0x10 |
17 |
0b10001 |
0o21 |
0x11 |
18 |
0b10010 |
0o22 |
0x12 |
19 |
0b10011 |
0o23 |
0x13 |
20 |
0b10100 |
0o24 |
0x14 |
C’est incroyable de voir à quel point ces expressions sont répandues dans la bibliothèque standard Python. Si vous voulez voir par vous-même, accédez à l’endroit où votre lib / python3.7 / répertoire est assis, et vérifiez l’utilisation de littéraux hexagonaux comme ceci:
$ grep -nri --include "* . py" -e " b0x" lib / python3.7
Cela devrait fonctionner sur tout système Unix qui a grep. Vous pourriez utiliser " b0o" pour rechercher des littéraux octaux ou “ b0b” pour rechercher des littéraux binaires.
Quel est l’argument pour utiliser ces solutions de rechange? int syntaxes littérales? En bref, c’est parce que 2, 8 et 16 sont tous des puissances de 2, alors que 10 ne l’est pas. Ces trois systèmes de numéros alternatifs offrent parfois un moyen d’exprimer des valeurs de manière conviviale. Par exemple, le nombre 65536 ou 216, est juste 10000 en hexadécimal, ou 0x10000 en tant que littéral hexadécimal Python.
Entrez Unicode
Comme vous avez pu le constater, le problème de l’ASCII est qu’il n’ya pas assez de jeux de caractères pour accueillir l’ensemble des langues, dialectes, symboles et glyphes du monde. (Ce n’est même pas assez grand pour l’anglais seul.)
Unicode sert fondamentalement le même but que ASCII, mais il englobe simplement une manière, façon plus grand ensemble de points de code. Quelques codages sont apparus chronologiquement entre ASCII et Unicode, mais ils ne valent pas vraiment la peine d'être mentionnés, car Unicode et l'un de ses schémas de codage, UTF-8, sont désormais utilisés de manière prédominante.
Considérez l’Unicode comme une version massive de la table ASCII, qui comporte 1 114 112 points de code possibles. C’est 0 à 1 114 111, ou 0 à 17 * (216) – 1, ou 0x10ffff hexadécimal. En fait, ASCII est un sous-ensemble parfait d'Unicode. Les 128 premiers caractères de la table Unicode correspondent précisément aux caractères ASCII auxquels vous vous attendez raisonnablement.
Dans l'intérêt d'être techniquement exigeant, Unicode lui-même est ne pas un encodage. Unicode est plutôt mis en œuvre différents encodages de caractères, que vous verrez bientôt. Unicode est mieux conçu comme une carte (quelque chose comme un dict) ou une table de base de données à 2 colonnes. Il mappe des personnages (comme "une", "¢", ou même "") en nombres entiers positifs distincts. Un encodage de caractères doit offrir un peu plus.
Unicode contient pratiquement tous les caractères que vous pouvez imaginer, y compris ceux qui ne le sont pas. Un de mes favoris est la marque embarrassante de droite à gauche, qui a le point de code 8207 et est utilisée dans le texte contient avec des scripts de langue de gauche à droite et de droite à gauche, tels qu'un article contenant l'anglais et l'arabe. paragraphes.
Remarque: Le monde des encodages de caractères est l’un des nombreux détails techniques à grain fin sur lesquels certaines personnes aiment s’amuser. Un de ces détails est que seulement 1 111 998 des points de code Unicode sont réellement utilisables, pour deux raisons archaïques.
Unicode vs UTF-8
Les gens ont vite compris que tous les personnages du monde ne pouvaient être regroupés dans un octet. Il est donc évident que des codages modernes et plus complets doivent utiliser plusieurs octets pour coder certains caractères.
Vous avez également vu plus haut qu'Unicode n'est techniquement pas un encodage de caractères à part entière. Pourquoi donc?
Unicode ne vous dit pas une chose: il ne vous dit pas comment obtenir des bits réels à partir de texte – juste des points de code. Cela ne vous en dit pas assez sur la façon de convertir du texte en données binaires et vice versa.
Unicode est un standard de codage abstrait, pas un codage. C’est là que les codages UTF-8 et d’autres entrent en jeu. Le standard Unicode (une correspondance de caractères en points de code) définit plusieurs codages différents à partir de son jeu de caractères unique.
UTF-8, ainsi que ses cousins moins utilisés, UTF-16 et UTF-32, sont des formats de codage permettant de représenter les caractères Unicode sous forme de données binaires d'un ou de plusieurs octets par caractère. Nous allons parler des UTF-16 et UTF-32 dans un instant, mais UTF-8 a remporté de loin la plus grande part du gâteau.
Cela nous amène à une définition attendue depuis longtemps. Qu'est-ce que cela signifie, formellement, de encoder et décoder?
Encodage et décodage en Python 3
Python 3 str type est censé représenter un texte lisible par l'homme et peut contenir n'importe quel caractère Unicode.
le octets Le type, à l'inverse, représente des données binaires, ou des séquences d'octets bruts, qui n'ont pas intrinsèquement de codage.
Le codage et le décodage consistent à passer de l’un à l’autre:
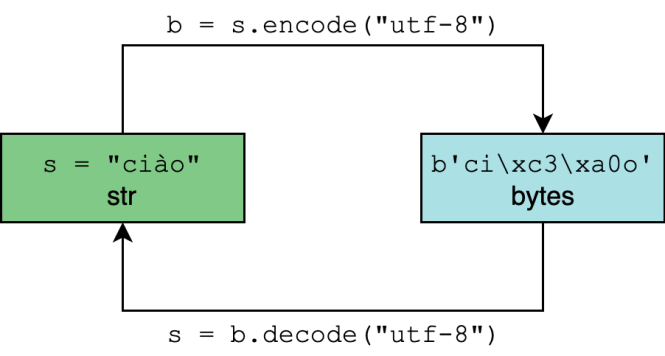
Dans .encoder() et .décoder(), la codage paramètre est "utf-8" par défaut, même s’il est généralement plus sûr et sans ambiguïté de le spécifier:
>>> "CV".encoder("utf-8")
b'r xc3 xa9sum xc3 xa9 '
>>> "El Niño".encoder("utf-8")
b'El Ni xc3 xb1o '
>>> b"r xc3 xa9somme xc3 xa9".décoder("utf-8")
'CV'
>>> b"El Ni xc3 xb1o ".décoder("utf-8")
'El Niño'
Les résultats de str.encode () est un octets objet. Les deux octets littéraux (tels que b "r xc3 xa9sum xc3 xa9") et les représentations d'octets n'autorisent que les caractères ASCII.
C'est pourquoi, en appelant "El Niño" .encode ("utf-8"), le compatible ASCII "El" est autorisé à être représenté tel quel, mais le n avec tilde est échappé à " xc3 xb1". Cette séquence désordonnée représente deux octets, 0xc3 et 0xb1 en hex:
>>> "".joindre(F"i: 08b" pour je dans (0xc3, 0xb1))
'11000011 10110001'
C'est le personnage ñ nécessite deux octets pour sa représentation binaire sous UTF-8.
Remarque: Si vous tapez aide (str.encode), vous verrez probablement un défaut de codage = 'utf-8'. Faites attention à exclure cela et simplement à utiliser "résumé" .encode (), car la valeur par défaut peut être différente dans Windows avant Python 3.6.
Python 3: All-In sur Unicode
Python 3 est tout-en-un sur Unicode et UTF-8 en particulier. Voici ce que cela signifie:
-
Le code source Python 3 est supposé être UTF-8 par défaut. Cela signifie que vous n'avez pas besoin
# - * - codage: UTF-8 - * -Au sommet de.pyfichiers en Python 3. -
Tout le texte (
str) est Unicode par défaut. Le texte codé Unicode est représenté sous forme de données binaires (octets). lestrtype peut contenir n’importe quel caractère Unicode littéral, tel que"Δv / Δt", qui seront tous stockés en tant que Unicode. -
N'importe quel élément du jeu de caractères Unicode est caché dans les identificateurs, ce qui signifie
résumé = "~ / Documents / resume.pdf"est valable si cela vous tente. -
Python
rémodule par défaut à lare.UNICODEdrapeau plutôt quere.ASCII. Cela signifie, par exemple, quer " w"correspond aux caractères Unicode, pas seulement aux lettres ASCII. -
Le défaut
codagedansstr.encode ()etbytes.decode ()est UTF-8.
Il y a une autre propriété qui est plus nuancée, qui est que le défaut codage à la intégré ouvrir() dépend de la plate-forme et dépend de la valeur de locale.getpreferredencoding ():
>>> # Mac OS X High Sierra
>>> importation lieu
>>> lieu.obtenir un codage préféré()
'UTF-8'
>>> # Windows Server 2012
>>> importation lieu
>>> lieu.obtenir un codage préféré()
'cp1252'
Un octet, deux octets, trois octets, quatre
Une caractéristique cruciale est que UTF-8 est un codage de longueur variable. Il est tentant de passer sous silence ce que cela signifie, mais cela vaut la peine d’être approfondi.
Repensez à la section sur ASCII. Tout ce qui est en ASCII étendu exige au plus un octet d’espace. Vous pouvez rapidement le prouver avec l'expression suivante du générateur:
>>> tout(len(chr(je).encoder("ascii")) == 1 pour je dans intervalle(128))
Vrai
UTF-8 est assez différent. Un caractère Unicode donné peut occuper de un à quatre octets. Voici un exemple de caractère Unicode unique occupant quatre octets:
>>> ibrow = ""
>>> len(ibrow)
1
>>> ibrow.encoder("utf-8")
b ' xf0 x9f xa4 xa8'
>>> len(ibrow.encoder("utf-8"))
4
>>> # Calling list () sur un objet octet vous donne
>>> # la valeur décimale pour chaque octet
>>> liste(b' xf0 x9f xa4 xa8')
[240, 159, 164, 168]
C’est une caractéristique subtile mais importante de len ():
- La longueur d'un caractère Unicode unique en tant que Python
strvolonté toujours être 1, peu importe le nombre d'octets qu'il occupe. - La longueur du même caractère encodé pour
octetssera n'importe où entre 1 et 4.
Le tableau ci-dessous récapitule les types de caractères généraux pouvant être insérés dans chaque compartiment d'une longueur en octets:
| Plage décimale | Gamme Hex | Ce qui est inclu | Exemples |
|---|---|---|---|
| 0 à 127 | " u0000" à " u007F" |
US ASCII | "UNE", " n", "7", "&" |
| 128 à 2047 | " u0080" à " u07FF" |
La plupart des alphabets latins * | "ê", "±", "", "ñ" |
| 2048 à 65535 | " u0800" à " uFFFF" |
Parties supplémentaires du plan multilingue (BMP) ** | "", "", "", "" |
| 65536 à 1114111 | " U00010000" à " U0010FFFF" |
Autre*** | "", "", "", "", |
* Tels que l'anglais, l'arabe, le grec et l'irlandais
** Un grand choix de langues et de symboles, principalement en chinois, japonais et coréen, par volume (alphabets ASCII et latin)
*** Caractères chinois, japonais, coréens et vietnamiens supplémentaires, ainsi que plus de symboles et d'émojis
Remarque: Afin de ne pas perdre de vue la situation dans son ensemble, il existe un ensemble supplémentaire de fonctionnalités techniques de UTF-8 qui ne sont pas abordées ici car elles sont rarement visibles pour un utilisateur Python.
Par exemple, UTF-8 utilise en réalité des codes de préfixe indiquant le nombre d'octets d'une séquence. Cela permet à un décodeur de savoir quels octets appartiennent ensemble dans un codage de longueur variable et de laisser le premier octet servir d'indicateur du nombre d'octets dans la séquence à venir.
L'article de Wikipedia sur UTF-8 ne craint pas les détails techniques, et il existe toujours la norme Unicode officielle pour votre plus grand plaisir de lecture.
Qu'en est-il des UTF-16 et UTF-32?
Revenons à deux autres variantes de codage, UTF-16 et UTF-32.
La différence entre ceux-ci et UTF-8 est substantielle dans la pratique. Voici un exemple de l’importance de la différence avec une conversion aller-retour:
>>> des lettres = "αβγδ"
>>> données brutes = des lettres.encoder("utf-8")
>>> données brutes.décoder("utf-8")
'αβγδ'
>>> données brutes.décoder("utf-16") # 😧
'돎듎'
Dans ce cas, coder quatre lettres grecques avec UTF-8 puis décoder de nouveau en texte en UTF-16 produirait un texte str c'est dans une langue complètement différente (coréen).
Des résultats manifestement faux comme celui-ci sont possibles lorsque le même encodage n'est pas utilisé dans les deux sens. Deux variantes de décodage identique octets objet peut produire des résultats qui ne sont même pas dans la même langue.
Ce tableau récapitule la plage ou le nombre d'octets sous UTF-8, UTF-16 et UTF-32:
| Codage | Octets par caractère (inclus) | Longueur variable |
|---|---|---|
| UTF-8 | 1 à 4 | Oui |
| UTF-16 | 2 à 4 | Oui |
| UTF-32 | 4 | Non |
Un autre aspect curieux de la famille UTF est que UTF-8 ne sera pas toujours prend moins de place que UTF-16. Cela peut paraître mathématiquement contre-intuitif, mais c’est tout à fait possible:
>>> texte = "鄭啟源 羅智堅"
>>> len(texte.encoder("utf-8"))
26
>>> len(texte.encoder("utf-16"))
22
La raison en est que le code pointe dans la plage U + 0800 à travers U + FFFF (2048 à 65535 en décimal) occupent trois octets en UTF-8, contre deux seulement en UTF-16.
Je ne vous recommande absolument pas de monter à bord du train UTF-16, que vous utilisiez ou non une langue dont les caractères sont généralement dans cette plage. Entre autres raisons, l’un des arguments forts en faveur de l’utilisation de UTF-8 est que, dans le monde de l’encodage, c’est une excellente idée de se fondre dans la foule.
Sans oublier, nous sommes en 2019: la mémoire de l’ordinateur est bon marché, donc économiser 4 octets en vous détournant de votre façon d’utiliser UTF-16 n’est sans doute pas rentable.
Fonctions intégrées de Python
Vous avez réussi la partie difficile. Il est temps d’utiliser ce que vous avez vu jusqu’à présent en Python.
Python possède un groupe de fonctions intégrées qui ont trait en quelque sorte aux systèmes de numérotation et au codage de caractères:
ascii ()poubelle()octets ()chr ()hex ()int ()oct()ord ()str ()
Ceux-ci peuvent être regroupés logiquement en fonction de leur objectif:
-
ascii (),poubelle(),hex (), etoct()sont destinés à obtenir une représentation différente d'une entrée. Chacun produit unstr. La première,ascii (), produit une représentation uniquement ASCII d’un objet, avec échappement des caractères non-ASCII. Les trois autres donnent les représentations binaire, hexadécimale et octale d'un entier, respectivement. Ce ne sont que représentations, pas un changement fondamental dans l'entrée. -
octets (),str (), etint ()sont des constructeurs de classe pour leurs types respectifs,octets,str, etint. Ils offrent chacun des moyens de forcer l'entrée dans le type souhaité. Par exemple, comme vous l'avez vu précédemment, alors queint (11.0)est probablement plus commun, vous pourriez aussi voirint ('11 ', base = 16). -
ord ()etchr ()sont des inverses les uns des autres en ce queord ()convertit unstrcaractère à son point de code base 10, tandis quechr ()fait le contraire.
Voici un aperçu plus détaillé de chacune de ces neuf fonctions:
| Une fonction | Signature | Accepte | Type de retour | Objectif |
|---|---|---|---|---|
ascii () |
ascii (obj) |
Varie | str |
Représentation ASCII uniquement d'un objet, avec échappement de caractères non-ASCII |
poubelle() |
bin (nombre) |
nombre: int |
str |
Représentation binaire d'un entier, avec le préfixe "0b" |
octets () |
octets (iterable_of_ints)
|
Varie | octets |
Forcer (convertir) l'entrée en octets, données binaires brutes |
chr () |
chr (i) |
i: int
|
str |
Convertir un point de code entier en un seul caractère Unicode |
hex () |
hex (nombre) |
nombre: int |
str |
Représentation hexadécimale d'un entier, avec le préfixe "0x" |
int () |
int ([x])
|
Varie | int |
Forcer (convertir) l'entrée en int |
oct() |
oct (nombre) |
nombre: int |
str |
Représentation octale d'un entier, avec le préfixe "0o" |
ord () |
ord (c) |
c: str
|
int |
Convertir un seul caractère Unicode en son point de code entier |
str () |
str (objet = '')
|
Varie | str |
Forcer (convertir) l'entrée en str, texte |
Vous pouvez développer la section ci-dessous pour voir quelques exemples de chaque fonction.
ascii () vous donne une représentation d'un objet uniquement en ASCII, avec échappement des caractères non-ASCII:
>>> Ascii("abcdefg")
"'abcdefg'"
>>> Ascii("jalepeño")
"'jalepe \ xf1o'"
>>> Ascii((1, 2, 3))
'(1, 2, 3)'
>>> Ascii(0xc0ffee) # Hex littéral (int)
'12648430'
poubelle() vous donne une représentation binaire d'un entier, avec le préfixe "0b":
>>> poubelle(0)
'0b0'
>>> poubelle(400)
'0b110010000'
>>> poubelle(0xc0ffee) # Hex littéral (int)
'0b11000000111111111111111110'
>>> [[[[poubelle(je) pour je dans [[[[1, 2, 4, 8, 16]] # `int` + compréhension de la liste
['0b1', '0b10', '0b100', '0b1000', '0b10000']
octets () contraint l'entrée à octets, représentant des données binaires brutes:
>>> # Iterable of ints
>>> octets((104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100))
b'hello world '
>>> octets(intervalle(97, 123)) # Iterable of ints
b'abcdefghijklmnopqrstuvwxyz '
>>> octets("vrai", "utf-8") # Chaîne + encodage
b'real xf0 x9f x90 x8d '
>>> octets(dix)
b ' x00 x00 x00 x00 x00 x00 x00 x00 x00 x00'
>>> octets.fromhex('c0 ff ee')
b ' xc0 xff xee'
>>> octets.fromhex("72 65 61 6c 70 79 74 68 6f 6e")
b'realpython '
chr () convertit un point de code entier en un seul caractère Unicode:
>>> chr(97)
'une'
>>> chr(7048)
''
>>> chr(1114111)
' U0010ffff'
>>> chr(0x10FFFF) # Hex littéral (int)
' U0010ffff'
>>> chr(0b01100100) # Littéral binaire (int)
'ré'
hex () donne la représentation hexadécimale d'un entier, avec le préfixe "0x":
>>> hexagone(100)
'0x64'
>>> [[[[hexagone(je) pour je dans [[[[1, 2, 4, 8, 16]]
['0x1', '0x2', '0x4', '0x8', '0x10']
>>> [[[[hexagone(je) pour je dans intervalle(16)]
['0x0''0x1''0x2''0x3''0x4''0x5''0x6''0x7'['0x0''0x1''0x2''0x3''0x4''0x5''0x6''0x7'['0x0''0x1''0x2''0x3''0x4''0x5''0x6''0x7'['0x0''0x1''0x2''0x3''0x4''0x5''0x6''0x7'
'0x8', '0x9', '0xa', '0xb', '0xc', '0xd', '0xe', '0xf']
int () contraint l'entrée à int, interprétant éventuellement l'entrée dans une base donnée:
>>> int(11.0)
11
>>> int('11')
11
>>> int('11', base=2)
3
>>> int('11', base=8)
9
>>> int('11', base=16)
17
>>> int(0xc0ffee - 1,0)
12648429
>>> int.from_bytes(b"x0f", "little")
15
>>> int.from_bytes(b'xc0xffxee', "big")
12648430
ord() converts a single Unicode character to its integer code point:
>>> ord("une")
97
>>> ord("ę")
281
>>> ord("ᮈ")
7048
>>> [[[[ord(je) pour je dans "hello world"]
[104, 101, 108, 108, 111, 32, 119, 111, 114, 108, 100]
str() coerces the input to str, representing text:
>>> str("str of string")
'str of string'
>>> str(5)
'5'
>>> str([[[[1, 2, 3, 4]) # Like [1, 2, 3, 4].__str__(), but use str()
'[1, 2, 3, 4]'
>>> str(b"xc2xbc cup of flour", "utf-8")
'¼ cup of flour'
>>> str(0xc0ffee)
'12648430'
Python String Literals: Ways to Skin a Cat
Rather than using the str() constructor, it’s commonplace to type a str literally:
>>> repas = "shrimp and grits"
That may seem easy enough. But the interesting side of things is that, because Python 3 is Unicode-centric through and through, you can “type” Unicode characters that you probably won’t even find on your keyboard. You can copy and paste this right into a Python 3 interpreter shell:
>>> alphabet = 'αβγδεζηθικλμνξοπρςστυφχψ'
>>> impression(alphabet)
αβγδεζηθικλμνξοπρςστυφχψ
Besides placing the actual, unescaped Unicode characters in the console, there are other ways to type Unicode strings as well.
One of the densest sections of Python’s documentation is the portion on lexical analysis, specifically the section on string and bytes literals. Personally, I had to read this section about one, two, or maybe nine times for it to really sink in.
Part of what it says is that there are up to six ways that Python will allow you to type the same Unicode character.
The first and most common way is to type the character itself literally, as you’ve already seen. The tough part with this method is finding the actual keystrokes. That’s where the other methods for getting and representing characters come into play. Voici la liste complète:
| Escape Sequence | Sens | How To Express "une" |
|---|---|---|
"ooo" |
Character with octal value ooo |
"141" |
"xhh" |
Character with hex value hh |
"x61" |
"Nname" |
Character named prénom in the Unicode database |
"NLATIN SMALL LETTER A" |
"uxxxx" |
Character with 16-bit (2-byte) hex value xxxx |
"u0061" |
"Uxxxxxxxx" |
Character with 32-bit (4-byte) hex value xxxxxxxx |
"U00000061" |
Here’s some proof and validation of the above:
>>> (
... "une" ==
... "x61" ==
... "NLATIN SMALL LETTER A" ==
... "u0061" ==
... "U00000061"
... )
Vrai
Now, there are two main caveats:
-
Not all of these forms work for all characters. The hex representation of the integer 300 is
0x012c, which simply isn’t going to fit into the 2-hex-digit escape code"xhh". The highest code point that you can squeeze into this escape sequence is"xff"("ÿ"). Similarly for"ooo", it will only work up to"777"("ǿ"). -
Pour
xhh,uxxxx, etUxxxxxxxx, exactly as many digits are required as are shown in these examples. This can throw you for a loop because of the way that Unicode tables conventionally display the codes for characters, with a leadingU+and variable number of hex characters. They key is that Unicode tables most often do not zero-pad these codes.
For instance, if you consult unicode-table.com for information on the Gothic letter faihu (or fehu), "", you’ll see that it is listed as having the code U+10346.
How do you put this into "uxxxx" ou "Uxxxxxxxx"? Well, you can’t fit it in "uxxxx" because it’s a 4-byte character, and to use "Uxxxxxxxx" to represent this character, you’ll need to left-pad the sequence:
>>> "U00010346"
''
This also means that the "Uxxxxxxxx" form is the only escape sequence that is capable of holding tout Unicode character.
Remarque: Here’s a short function to convert strings that look like "U+10346" into something Python can work with. It uses str.zfill():
>>> def make_uchr(code: str):
... revenir chr(int(code.lstrip("U+").zfill(8), 16))
>>> make_uchr("U+10346")
''
>>> make_uchr("U+0026")
'&'
Other Encodings Available in Python
So far, you’ve seen four character encodings:
- ASCII
- UTF-8
- UTF-16
- UTF-32
There are a ton of other ones out there.
One example is Latin-1 (also called ISO-8859-1), which is technically the default for the Hypertext Transfer Protocol (HTTP), per RFC 2616. Windows has its own Latin-1 variant called cp1252.
Remarque: ISO-8859-1 is still very much present out in the wild. le demandes library follows RFC 2616 “to the letter” in using it as the default encoding for the content of an HTTP/HTTPS response. If the word “text” is found in the Type de contenu header, and no other encoding is specified, then demandes will use ISO-8859-1.
The complete list of accepted encodings is buried way down in the documentation for the codecs module, which is part of Python’s Standard Library.
There’s one more useful recognized encoding to be aware of, which is "unicode-escape". If you have a decoded str and want to quickly get a representation of its escaped Unicode literal, then you can specify this encoding in .encode():
>>> alef = chr(1575) # Or "u0627"
>>> alef_hamza = chr(1571) # Or "u0623"
>>> alef, alef_hamza
('ا', 'أ')
>>> alef.encoder("unicode-escape")
b'\u0627'
>>> alef_hamza.encoder("unicode-escape")
b'\u0623'
You Know What They Say About Assumptions…
Just because Python makes the assumption of UTF-8 encoding for files and code that vous generate doesn’t mean that you, the programmer, should operate with the same assumption for external data.
Let’s say that again because it’s a rule to live by: when you receive binary data (bytes) from a third party source, whether it be from a file or over a network, the best practice is to check that the data specifies an encoding. If it doesn’t, then it’s on you to ask.
All I/O happens in bytes, not text, and bytes are just ones and zeros to a computer until you tell it otherwise by informing it of an encoding.
Here’s an example of where things can go wrong. You’re subscribed to an API that sends you a recipe of the day, which you receive in octets and have always decoded using .decode("utf-8") with no problem. On this particular day, part of the recipe looks like this:
>>> Les données = b"xbc cup of flour"
It looks as if the recipe calls for some flour, but we don’t know how much:
>>> Les données.décoder("utf-8")
Traceback (most recent call last):
Fichier "" , line 1, dans
Uh oh. There’s that pesky UnicodeDecodeError that can bite you when you make assumptions about encoding. You check with the API host. Lo and behold, the data is actually sent over encoded in Latin-1:
>>> Les données.décoder("latin-1")
'¼ cup of flour'
There we go. In Latin-1, every character fits into a single byte, whereas the “¼” character takes up two bytes in UTF-8 ("xc2xbc").
The lesson here is that it can be dangerous to assume the encoding of any data that is handed off to you. Ses d'habitude UTF-8 these days, but it’s the small percentage of cases where it’s not that will blow things up.
If you really do need to abandon ship and guess an encoding, then have a look at the chardet library, which uses methodology from Mozilla to make an educated guess about ambiguously encoded text. That said, a tool like chardet should be your last resort, not your first.
Odds and Ends: unicodedata
We would be remiss not to mention unicodedata from the Python Standard Library, which lets you interact with and do lookups on the Unicode Character Database (UCD):
>>> importation unicodedata
>>> unicodedata.prénom("€")
'EURO SIGN'
>>> unicodedata.lookup("EURO SIGN")
'€'
Emballer
In this article, you’ve decoded the wide and imposing subject of character encoding in Python.
You’ve covered a lot of ground here:
- Fundamental concepts of character encodings and numbering systems
- Integer, binary, octal, hex, str, and bytes literals in Python
- Python’s built-in functions related to character encoding and numbering systems
- Python 3’s treatment of text versus binary dat
Now, go forth and encode!
Ressources
For even more detail about the topics covered here, check out these resources:
The Python docs have two pages on the subject:
[ad_2]