python pour débutant
Il est de plus en plus courant de faire face à des situations où la quantité de données est tout simplement trop importante pour être gérée sur une seule machine. Heureusement, des technologies telles que Apache Spark, Hadoop et d’autres ont été développées pour résoudre ce problème. La puissance de ces systèmes peut être exploitée directement depuis Python en utilisant PySpark!
Traiter efficacement des jeux de données de gigaoctets et plus est bien à la portée de tout développeur Python, qu’il s’agisse d’un data scientist, d’un développeur web ou de tout autre élément intermédiaire.
Dans ce tutoriel, vous apprendrez:
- Quels concepts Python peuvent être appliqués au Big Data
- Comment utiliser Apache Spark et PySpark
- Comment écrire des programmes PySpark de base
- Comment exécuter des programmes PySpark sur de petits jeux de données localement
- Où aller ensuite pour utiliser vos compétences PySpark vers un système distribué
Concepts Big Data en Python
Malgré sa popularité juste Un langage de script, Python expose plusieurs paradigmes de programmation tels que la programmation orientée tableau, la programmation orientée objet, la programmation asynchrone et bien d’autres. La programmation fonctionnelle est un paradigme particulièrement intéressant pour les futurs professionnels du Big Data.
La programmation fonctionnelle est un paradigme commun lorsqu'il s'agit de Big Data. L'écriture de manière fonctionnelle crée un code parallèle embarrassant. Cela signifie qu’il est plus facile de prendre votre code et de le faire fonctionner sur plusieurs processeurs ou même sur des machines totalement différentes. Vous pouvez contourner les restrictions de mémoire physique et d'UC d'un poste de travail en s'exécutant simultanément sur plusieurs systèmes.
C'est la puissance de l'écosystème PySpark, qui vous permet de récupérer du code fonctionnel et de le distribuer automatiquement sur un cluster d'ordinateurs.
Heureusement pour les programmeurs Python, bon nombre des idées de base de la programmation fonctionnelle sont disponibles dans la bibliothèque standard et les fonctions intégrées de Python. Vous pouvez apprendre de nombreux concepts nécessaires au traitement des données volumineuses sans jamais quitter le confort de Python.
L'idée centrale de la programmation fonctionnelle est que les données doivent être manipulées par des fonctions sans maintenir aucun état externe. Cela signifie que votre code évite les variables globales et renvoie toujours nouvelles données au lieu de manipuler les données en place.
Une autre idée courante en programmation fonctionnelle concerne les fonctions anonymes. Python expose les fonctions anonymes en utilisant le lambda mot-clé, à ne pas confondre avec les fonctions AWS Lambda.
Maintenant que vous connaissez certains termes et concepts, vous pouvez explorer comment ces idées se manifestent dans l'écosystème Python.
Fonctions Lambda
Les fonctions lambda en Python sont définies en ligne et limitées à une seule expression. Vous avez probablement vu lambda fonctions lors de l'utilisation de la fonction intégrée triés () une fonction:
>>> X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
>>> impression(triés(X))
['Python', 'awesome!', 'is', 'programming']
>>> impression(triés(X, clé=lambda se disputer: se disputer.inférieur()))
['awesome!', 'is', 'programming', 'Python']
le clé paramètre à triés est appelé pour chaque élément de l'itérable. Cela rend le tri insensible à la casse en modifiant toutes les chaînes en minuscules. avant le tri a lieu.
Ceci est un cas d'utilisation courant pour lambda fonctions, petites fonctions anonymes qui ne maintiennent aucun état externe.
D’autres fonctions de programmation fonctionnelle courantes existent également dans Python, telles que filtre(), carte(), et réduire(). Toutes ces fonctions peuvent utiliser lambda fonctions ou fonctions standard définies avec def d'une manière similaire.
filtre(), carte(), et réduire()
Le intégré filtre(), carte(), et réduire() les fonctions sont toutes communes dans la programmation fonctionnelle. Vous verrez bientôt que ces concepts peuvent constituer une partie importante des fonctionnalités d’un programme PySpark.
Il est important de comprendre ces fonctions dans un contexte Python fondamental. Vous pourrez ensuite traduire ces connaissances en programmes PySpark et en API Spark.
filtre() permet de filtrer les éléments d’une liste itérable en fonction d’une condition, généralement exprimée en tant que lambda une fonction:
>>> X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
>>> impression(liste(filtre(lambda se disputer: len(se disputer) < 8, X)))
['Python', 'is']
filtre() prend un itérable, appelle le lambda fonction sur chaque élément et renvoie les éléments où le lambda revenu Vrai.
Remarque: Appel liste() est nécessaire parce que filtre() est aussi un iterable. filtre() ne vous donne que les valeurs lorsque vous les parcourez. liste() force tous les éléments en mémoire en même temps au lieu d’avoir à utiliser une boucle.
Vous pouvez imaginer utiliser filtre() pour remplacer un commun pour motif de boucle comme suit:
def is_less_than_8_characters(article):
revenir len(article) < 8
X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
résultats = []
pour article dans X:
si is_less_than_8_characters(article):
résultats.ajouter(article)
impression(résultats)
Ce code collecte toutes les chaînes de moins de 8 caractères. Le code est plus bavard que le filtre() exemple, mais il remplit la même fonction avec les mêmes résultats.
Un autre avantage moins évident de filtre() est-ce qu'il retourne un itérable. Ça signifie filtre() n’exige pas que votre ordinateur dispose de suffisamment de mémoire pour contenir tous les éléments de l’itéré à la fois. Ceci est de plus en plus important avec les ensembles Big Data pouvant atteindre rapidement plusieurs gigaoctets.
carte() est similaire à filtre() en ce qu 'il applique une fonction à chaque élément d'une variable, mais produit toujours un mappage un à un des éléments d'origine. le Nouveau iterable que carte() les retours auront toujours le même nombre d’éléments que l’itéré initial, ce qui n’était pas le cas avec filtre():
>>> X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
>>> impression(liste(carte(lambda se disputer: se disputer.plus haut(), X)))
['PYTHON', 'PROGRAMMING', 'IS', 'AWESOME!']
carte() appelle automatiquement le lambda fonctionner sur tous les articles, en remplaçant efficacement un pour boucle comme suit:
résultats = []
X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
pour article dans X:
résultats.ajouter(article.plus haut())
impression(résultats)
le pour boucle a le même résultat que le carte() exemple, qui regroupe tous les éléments en majuscules. Cependant, comme avec le filtre() Exemple, carte() renvoie une valeur itérable, ce qui permet à nouveau de traiter de grands ensembles de données trop volumineux pour tenir entièrement en mémoire.
Enfin, le dernier trio fonctionnel de la bibliothèque standard Python est réduire(). Comme avec filtre() et carte(), réduire()applique une fonction aux éléments d'un itérable.
De nouveau, la fonction appliquée peut être une fonction Python standard créée avec le def mot clé ou un lambda une fonction.
cependant, réduire() ne retourne pas un nouvel iterable. Au lieu, réduire() utilise la fonction appelée pour réduire l'itérable à une valeur unique:
>>> de functools importation réduire
>>> X = [[[['Python', 'la programmation', 'est', 'impressionnant!']
>>> impression(réduire(lambda val1, val2: val1 + val2, X))
Pythonprogrammingisawesome!
Ce code regroupe tous les éléments de la liste, de gauche à droite, en un seul élément. Il n'y a pas d'appel à liste() ici parce que réduire() renvoie déjà un seul article.
Remarque: Python 3.x déplacé le intégré réduire() fonctionner dans le functools paquet.
lambda, carte(), filtre(), et réduire() Ces concepts existent dans de nombreuses langues et peuvent être utilisés dans les programmes Python standard. Bientôt, ces concepts s’étendront à l’API PySpark pour traiter de grandes quantités de données.
Ensembles
Les ensembles constituent un autre élément de fonctionnalité courant existant dans Python standard et sont largement utiles pour le traitement Big Data. Les ensembles ressemblent beaucoup aux listes, à la différence qu’ils n’ont aucun ordre et ne peuvent pas contenir de valeurs en double. Vous pouvez penser à un ensemble similaire aux clés d'un dict Python.
Bonjour tout le monde à PySpark
Comme dans tout bon tutoriel de programmation, vous voudrez commencer avec un Bonjour le monde Exemple. Ci-dessous, l'équivalent PySpark:
importation pyspark
Caroline du Sud = pyspark.SparkContext('local[*]')
SMS = Caroline du Sud.fichier texte('fichier: //// usr / share / doc / python / copyright')
impression(SMS.compter())
python_lines = SMS.filtre(lambda ligne: 'python' dans ligne.inférieur())
impression(python_lines.compter())
Ne vous inquiétez pas pour tous les détails pour le moment. L’idée principale est de garder à l’esprit qu’un programme PySpark n’est pas très différent d’un programme Python classique.
Remarque: Ce programme déclenchera probablement une Exception sur votre système si PySpark n’est pas encore installé ou n’a pas le programme spécifié. droits d'auteur fichier, que vous verrez comment faire plus tard.
Vous apprendrez tous les détails de ce programme bientôt, mais regardez bien. Le programme compte le nombre total de lignes et le nombre de lignes qui ont le mot python dans un fichier nommé droits d'auteur.
Rappelles toi, un programme PySpark n’est pas si différent d’un programme Python classique, mais le modèle d'exécution peut être très différent depuis un programme Python normal, surtout si vous utilisez un cluster.
Il peut y avoir beaucoup de choses en arrière-plan qui répartissent le traitement sur plusieurs nœuds si vous êtes sur un cluster. Cependant, pour l’instant, considérez le programme comme un programme Python utilisant la bibliothèque PySpark.
Maintenant que vous avez découvert certains concepts fonctionnels communs à Python, ainsi qu’un simple programme PySpark, il est temps de plonger plus profondément dans Spark et PySpark.
Qu'est-ce que Spark?
Apache Spark est composé de plusieurs composants, il peut donc être difficile de le décrire. À la base, Spark est un générique moteur pour traiter de grandes quantités de données.
Spark est écrit en scala et fonctionne sur la machine virtuelle Java. Spark intègre des composants permettant de traiter des données en continu, d’apprentissage automatique, de traiter des graphiques et même d’interagir avec des données via SQL.
Dans ce guide, vous ne découvrirez que les principaux composants de Spark pour le traitement du Big Data. Cependant, tous les autres composants tels que l'apprentissage automatique, SQL, etc. sont également disponibles pour les projets Python via PySpark.
Qu'est-ce que PySpark?
Spark est implémenté dans Scala, un langage qui s'exécute sur la machine virtuelle Java. Comment accéder à toutes ces fonctionnalités via Python?
PySpark est la réponse.
La version actuelle de PySpark est 2.4.3 et fonctionne avec Python 2.7, 3.3 et supérieur.
Vous pouvez considérer PySpark comme un wrapper basé sur Python au-dessus de l'API Scala. Cela signifie que vous disposez de deux ensembles de documentation auxquels vous pouvez vous référer:
- Documentation de l'API PySpark
- Documentation de l'API Spark Scala
Les documents de l'API PySpark contiennent des exemples, mais vous souhaiterez souvent consulter la documentation de Scala et traduire le code en syntaxe Python pour vos programmes PySpark. Heureusement, Scala est un langage de programmation basé sur des fonctions très lisible.
PySpark communique avec l'API basée sur Spark Scala via la bibliothèque Py4J. Py4J n’est pas spécifique à PySpark ou à Spark. Py4J permet à tout programme Python de communiquer avec du code basé sur JVM.
PySpark est basé sur le paradigme fonctionnel pour deux raisons:
- Scala, la langue maternelle de Spark, est fonctionnelle.
- Le code fonctionnel est beaucoup plus facile à paralléliser.
Une autre façon de penser à PySpark est une bibliothèque qui permet de traiter de grandes quantités de données sur une seule machine ou un cluster de machines.
Dans un contexte Python, pensez à PySpark qui dispose d’un moyen de gérer le traitement parallèle sans avoir besoin de la filetage ou multitraitement modules. Spark prend en charge toute la communication et la synchronisation complexes entre les threads, les processus et même les différents processeurs.
API PySpark et structures de données
Pour interagir avec PySpark, vous créez des structures de données spécialisées appelées ensembles de données distribuées résilientes (RDD).
Les RDD masquent toute la complexité de la transformation et de la distribution automatique de vos données sur plusieurs nœuds à l'aide d'un planificateur si vous travaillez sur un cluster.
Pour mieux comprendre l’API et les structures de données de PySpark, rappelez-vous Bonjour le monde programme mentionné précédemment:
importation pyspark
Caroline du Sud = pyspark.SparkContext('local[*]')
SMS = Caroline du Sud.fichier texte('fichier: //// usr / share / doc / python / copyright')
impression(SMS.compter())
python_lines = SMS.filtre(lambda ligne: 'python' dans ligne.inférieur())
impression(python_lines.compter())
Le point d’entrée de tout programme PySpark est un SparkContext objet. Cet objet vous permet de vous connecter à un cluster Spark et de créer des RDD. le local[*] chaîne est une chaîne spéciale indiquant que vous utilisez un local cluster, qui est une autre façon de dire que vous travaillez en mode mono-ordinateur. le * indique à Spark de créer autant de threads de travail que de cœurs logiques sur votre ordinateur.
Créer un SparkContext peut être plus impliqué lorsque vous utilisez un cluster. Pour vous connecter à un cluster Spark, vous devrez peut-être gérer l'authentification et quelques autres informations spécifiques à votre cluster. Vous pouvez configurer ces détails de la même manière que:
conf = pyspark.SparkConf()
conf.setMaster('spark: // head_node: 56887')
conf.ensemble('spark.authenticate', Vrai)
conf.ensemble('spark.authenticate.secret', 'clef secrète')
Caroline du Sud = SparkContext(conf=conf)
Vous pouvez commencer à créer des RDD une fois que vous avez un SparkContext.
Vous pouvez créer des RDD de différentes manières, mais PySpark est une méthode courante. paralléliser () une fonction. paralléliser () peut transformer certaines structures de données Python telles que des listes et des nuplets en RDD, ce qui vous donne une fonctionnalité qui les rend tolérants aux pannes et distribués.
Pour mieux comprendre les RDD, prenons un autre exemple. Le code suivant crée un itérateur de 10 000 éléments puis utilise paralléliser () pour distribuer ces données dans 2 partitions:
>>> big_list = intervalle(10000)
>>> rdd = Caroline du Sud.paralléliser(big_list, 2)
>>> chances = rdd.filtre(lambda X: X % 2 ! = 0)
>>> chances.prendre(5)
[1, 3, 5, 7, 9]
paralléliser () transforme cet itérateur en un distribué ensemble de chiffres et vous donne toutes les capacités de l’infrastructure de Spark.
Notez que ce code utilise le code du RDD. filtre() méthode au lieu de celle de Python filtre(), que vous avez vu plus tôt. Le résultat est le même, mais ce qui se passe dans les coulisses est radicalement différent. En utilisant le RDD filtre() méthode, cette opération a lieu de manière distribuée sur plusieurs processeurs ou ordinateurs.
Encore une fois, imaginez ceci comme Spark faisant la multitraitement travailler pour vous, tous encapsulés dans la structure de données RDD.
prendre() est un moyen de voir le contenu de votre RDD, mais seulement un petit sous-ensemble. prendre() extrait ce sous-ensemble de données du système distribué sur une seule machine.
prendre() est important pour le débogage car l'inspection de l'ensemble de vos données sur une seule machine peut s'avérer impossible. Les RDD sont optimisés pour être utilisés sur le Big Data. Ainsi, dans un scénario réel, un seul ordinateur peut ne pas disposer de suffisamment de RAM pour stocker l'intégralité de votre jeu de données.
Remarque: Spark imprime temporairement des informations sur stdout lorsque vous exécutez des exemples comme celui-ci dans le shell, ce que vous verrez bientôt faire. Votre stdout pourrait montrer temporairement quelque chose comme [Stage 0:> (0 + 1) / 1].
le stdout text montre comment Spark divise les RDD et traite vos données en plusieurs étapes sur différents processeurs et machines.
Une autre façon de créer des RDD consiste à lire dans un fichier avec fichier texte(), que vous avez vu dans les exemples précédents. Les RDD sont l’une des structures de données fondamentales pour l’utilisation de PySpark, de sorte que de nombreuses fonctions de l’API renvoient des RDD.
L'une des principales distinctions entre les RDD et les autres structures de données est que le traitement est retardé jusqu'à ce que le résultat soit demandé. Ceci est similaire à un générateur Python. Les développeurs de l'écosystème Python utilisent généralement le terme évaluation lazy pour expliquer ce comportement.
Vous pouvez empiler plusieurs transformations sur le même RDD sans aucun traitement. Cette fonctionnalité est possible car Spark conserve un graphe acyclique dirigé des transformations. Le graphique sous-jacent n'est activé que lorsque les résultats finaux sont demandés. Dans l'exemple précédent, aucun calcul n'a eu lieu jusqu'à ce que vous ayez demandé les résultats en appelant prendre().
Il y a plusieurs façons de demander les résultats d'un RDD. Vous pouvez demander explicitement que les résultats soient évalués et collectés sur un seul nœud de cluster en utilisant collecte() sur un RDD. Vous pouvez également demander implicitement les résultats de différentes manières, l’une d’elles utilisant compter() comme vous l'avez vu plus tôt.
Remarque: Soyez prudent lorsque vous utilisez ces méthodes, car elles enregistrent la totalité du jeu de données en mémoire, ce qui ne fonctionnera pas si le jeu de données est trop volumineux pour tenir dans la RAM d'une seule machine.
Encore une fois, reportez-vous à la documentation de l'API PySpark pour plus de détails sur toutes les fonctionnalités possibles.
Installation de PySpark
En règle générale, vous exécuterez des programmes PySpark sur un cluster Hadoop, mais d’autres options de déploiement de cluster sont prises en charge. Vous pouvez lire la présentation du mode cluster de Spark pour plus de détails.
Remarque: La mise en place de l’un de ces groupes peut être difficile et sort du cadre de ce guide. Dans l’idéal, votre équipe doit faire appel à des ingénieurs DevOps de l’assistant pour vous aider à faire en sorte que cela fonctionne. Sinon, Hadoop publie un guide pour vous aider.
Dans ce guide, vous verrez plusieurs façons d’exécuter des programmes PySpark sur votre ordinateur local. C’est utile pour les tests et l’apprentissage, mais vous voudrez rapidement utiliser vos nouveaux programmes et les exécuter sur un cluster pour traiter réellement le Big Data.
Parfois, la configuration de PySpark en elle-même peut être difficile en raison de toutes les dépendances requises.
PySpark s'exécute sur la JVM et nécessite de nombreuses infrastructures Java sous-jacentes pour fonctionner. Cela dit, nous vivons à l'ère de Docker, ce qui facilite grandement les expériences avec PySpark.
Mieux encore, les incroyables développeurs derrière Jupyter ont fait le gros du travail pour vous. Ils publient un fichier Docker qui inclut toutes les dépendances de PySpark avec Jupyter. Vous pouvez donc expérimenter directement dans un cahier Jupyter!
Tout d’abord, vous devez installer Docker. Jetez un coup d’œil à Docker en action: plus en forme, plus heureux, plus productif si vous n’avez pas encore configuré Docker.
Remarque: Les images Docker peuvent être assez volumineuses. Assurez-vous d’utiliser environ 5 Go d’espace disque pour utiliser PySpark et Jupyter.
Ensuite, vous pouvez exécuter la commande suivante pour télécharger et lancer automatiquement un conteneur Docker avec une configuration prédéfinie à noeud unique PySpark. Cette commande peut prendre quelques minutes car elle télécharge les images directement à partir de DockerHub ainsi que toutes les conditions requises pour Spark, PySpark et Jupyter:
$ docker run -p 8888: 8888 cahier jupyter / pyspark
Une fois que cette commande a cessé d'imprimer, vous disposez d'un conteneur en cours d'exécution qui contient tout ce dont vous avez besoin pour tester vos programmes PySpark dans un environnement à un seul nœud.
Pour arrêter votre conteneur, tapez Ctrl+C dans la même fenêtre vous avez tapé le docker run commande dans.
Il est maintenant temps de lancer certains programmes!
Exécution des programmes PySpark
Il existe plusieurs manières d'exécuter des programmes PySpark, selon que vous préférez une ligne de commande ou une interface plus visuelle. Pour une interface de ligne de commande, vous pouvez utiliser la commande spark-submit commande standard, le shell Python standard ou le shell spécialisé PySpark.
Tout d’abord, vous verrez l’interface plus visuelle avec un bloc-notes Jupyter.
Jupyter Notebook
Vous pouvez exécuter votre programme dans un bloc-notes Jupyter en exécutant la commande suivante pour démarrer le conteneur Docker que vous avez précédemment téléchargé (s'il n'est pas déjà en cours d'exécution):
$ docker run -p 8888: 8888 cahier jupyter / pyspark
Exécuter la commande: jupyter notebook
[I 08:04:22.869 NotebookApp] Écrire un cookie de serveur de cahier secret à /home/jovyan/.local/share/jupyter/runtime/notebook_cookie_secret
[I 08:04:25.022 NotebookApp] Extension JupyterLab chargée à partir de /opt/conda/lib/python3.7/site-packages/jupyterlab
[I 08:04:25.022 NotebookApp] Le répertoire de l'application JupyterLab est / opt / conda / share / jupyter / lab
[I 08:04:25.027 NotebookApp] Servir des cahiers à partir du répertoire local: / home / jovyan
[I 08:04:25.028 NotebookApp] Le carnet de notes Jupyter fonctionne sous:
[I 08:04:25.029 NotebookApp] http: // (4d5ab7a93902 ou 127.0.0.1): 8888 /? token = 80149acebe00b2c98242aa9b87d24739c78e562f849e4437
[I 08:04:25.029 NotebookApp] Utilisez Control-C pour arrêter ce serveur et arrêter tous les noyaux (deux fois pour ignorer la confirmation).
[C 08:04:25.037 NotebookApp]
Pour accéder au bloc-notes, ouvrez ce fichier dans un navigateur:
fichier: ///home/jovyan/.local/share/jupyter/runtime/nbserver-6-open.html
Ou copiez et collez l'une de ces URL:
http: // (4d5ab7a93902 ou 127.0.0.1): 8888 /? token = 80149acebe00b2c98242aa9b87d24739c78e562f849e4437
Vous avez maintenant un conteneur fonctionnant avec PySpark. Notez que la fin de la docker run la sortie de commande mentionne une URL locale.
Remarque: La sortie du docker les commandes seront légèrement différentes sur chaque ordinateur, car les jetons, les ID de conteneur et les noms de conteneur sont tous générés de manière aléatoire.
Vous devez utiliser cette URL pour vous connecter au conteneur Docker exécutant Jupyter dans un navigateur Web. Copier et coller l'URL de votre sortie directement dans votre navigateur Web. Voici un exemple d’URL que vous verrez probablement:
$ http://127.0.0.1:8888/?token=80149acebe00b2c98242aa9b87d24739c78e562f849e4437
L'URL dans la commande ci-dessous sera probablement légèrement différent sur votre ordinateur, mais une fois que vous vous êtes connecté à cette URL dans votre navigateur, vous pouvez accéder à un environnement de bloc-notes Jupyter, qui devrait ressembler à ceci:

Dans la page du carnet Jupyter, vous pouvez utiliser le Nouveau bouton à l'extrême droite pour créer un nouveau shell Python 3. Ensuite, vous pouvez tester du code, comme le Bonjour le monde exemple d'avant:
importation pyspark
Caroline du Sud = pyspark.SparkContext('local[*]')
SMS = Caroline du Sud.fichier texte('fichier: //// usr / share / doc / python / copyright')
impression(SMS.compter())
python_lines = SMS.filtre(lambda ligne: 'python' dans ligne.inférieur())
impression(python_lines.compter())
Voici à quoi ressemblera ce code dans le bloc-notes Jupyter:

Il se passe beaucoup de choses en coulisse ici, il faut donc quelques secondes pour que vos résultats s'affichent. La réponse n’apparaîtra pas immédiatement après avoir cliqué sur la cellule.
Interface de ligne de commande
L’interface de ligne de commande offre diverses méthodes pour soumettre des programmes PySpark, notamment le shell PySpark et le spark-submit commander. Pour utiliser ces approches CLI, vous devez d’abord vous connecter à la CLI du système sur lequel PySpark est installé.
Pour vous connecter à la CLI de la configuration de Docker, vous devez démarrer le conteneur comme avant, puis l’attacher à ce conteneur. De nouveau, pour démarrer le conteneur, vous pouvez exécuter la commande suivante:
$ docker run -p 8888: 8888 cahier jupyter / pyspark
Une fois que le conteneur Docker est en cours d’exécution, vous devez vous y connecter via le shell plutôt qu’un bloc-notes Jupyter. Pour ce faire, exécutez la commande suivante pour rechercher le nom du conteneur:
$ conteneur docker ls
NOM DES PORTS DE STATUT CRÉÉS PAR UN COMMAND D'IMAGE D'IDENTIFIANT
4d5ab7a93902 jupyter / pyspark-notebook "tini -g - start-no…" Il y a 12 secondes Jusqu'à 10 secondes 0.0.0.0:8888->8888/tcp kind_edison
Cette commande vous montrera tous les conteneurs en cours d'exécution. Trouvez le CONTENANT ID du conteneur qui exécute le jupyter / pyspark-notebook l'image et l'utiliser pour se connecter à la frapper coquille à l'intérieur le conteneur:
$ docker exec -it 4d5ab7a93902 bash
jovyan @ 4d5ab7a93902: ~ $
Maintenant, vous devriez être connecté à un frapper rapide à l'intérieur du conteneur. Vous pouvez vérifier que tout fonctionne correctement, car l'invite de votre shell changera pour ressembler à quelque chose de similaire à jovyan @ 4d5ab7a93902, mais en utilisant l’identifiant unique de votre conteneur.
Remarque: Remplacer 4d5ab7a93902 avec le CONTENANT ID utilisé sur votre machine.
Grappe
Vous pouvez utiliser le spark-submit Commande installée avec Spark pour soumettre le code PySpark à un cluster à l'aide de la ligne de commande. Cette commande prend un programme PySpark ou Scala et l'exécute sur un cluster. C’est probablement ainsi que vous exécuterez vos véritables travaux de traitement de données volumineuses.
Remarque: Le chemin d'accès à ces commandes dépend de l'emplacement d'installation de Spark et ne fonctionnera probablement que si vous utilisez le conteneur Docker référencé.
Pour exécuter le Bonjour le monde Par exemple, (ou n’importe quel programme PySpark) avec le conteneur Docker en cours d’exécution, accédez d’abord au shell comme décrit ci-dessus. Une fois dans l'environnement du conteneur, vous pouvez créer des fichiers à l'aide de l'éditeur de texte nano.
Pour créer le fichier dans votre dossier actuel, lancez simplement nano avec le nom du fichier que vous voulez créer:
Tapez le contenu de la Bonjour le monde exemple et enregistrez le fichier en tapant Ctrl+X et en suivant les invites de sauvegarde:
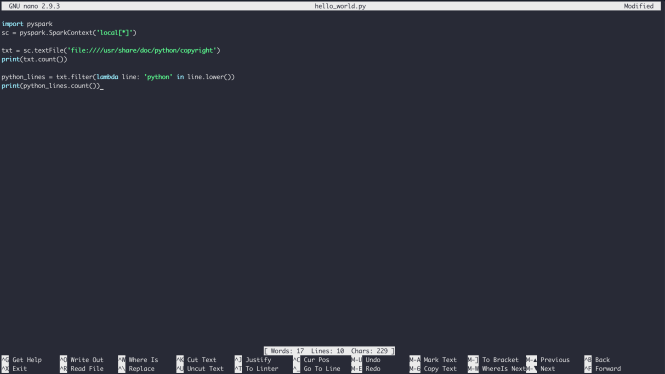
Enfin, vous pouvez exécuter le code via Spark avec le pyspark-submit commander:
$ / usr / local / spark / bin / spark-submit hello_world.py
Cette commande a pour résultat beaucoup sortie par défaut, il peut donc être difficile de voir la sortie de votre programme. Vous pouvez contrôler quelque peu la verbosité du journal dans votre programme PySpark en modifiant le niveau de votre SparkContext variable. Pour ce faire, placez cette ligne vers le haut de votre script:
Cela va omettre certains de la sortie de spark-submit afin que vous puissiez voir plus clairement le résultat de votre programme. Toutefois, dans un scénario réel, vous souhaiterez mettre toute sortie dans un fichier, une base de données ou un autre mécanisme de stockage pour faciliter le débogage ultérieur.
Heureusement, un programme PySpark a toujours accès à toute la bibliothèque standard de Python. Il n’est donc pas problématique de sauvegarder vos résultats dans un fichier:
importation pyspark
Caroline du Sud = pyspark.SparkContext('local[*]')
SMS = Caroline du Sud.fichier texte('fichier: //// usr / share / doc / python / copyright')
python_lines = SMS.filtre(lambda ligne: 'python' dans ligne.inférieur())
avec ouvrir('résultats.txt', 'w') comme file_obj:
file_obj.écrire(F'Nombre de lignes: txt.count () n')
file_obj.écrire(F'Nombre de lignes avec python: python_lines.count () n')
Maintenant, vos résultats sont dans un fichier séparé appelé résultats.txt pour faciliter la référence plus tard.
Remarque: Le code ci-dessus utilise des chaînes de caractères, introduites dans Python 3.6.
PySpark Shell
Une autre façon d’exécuter vos programmes avec PySpark consiste à utiliser le shell fourni avec PySpark lui-même. De nouveau, à l’aide de la configuration de Docker, vous pouvez vous connecter à la CLI du conteneur comme décrit ci-dessus. Ensuite, vous pouvez exécuter le shell Python spécialisé avec la commande suivante:
$ / usr / local / spark / bin / pyspark
Python 3.7.3 | emballé par conda-forge | (défaut, le 27 mars 2019, 23:01:00)
[GCC 7.3.0] :: Anaconda, Inc. sur linux
Tapez "aide", "copyright", "crédits" ou "licence" pour plus d'informations.
Utilisation du profil log4j par défaut de Spark: org / apache / spark / log4j-defaults.properties
Définition du niveau de journalisation par défaut sur "WARN".
Pour ajuster le niveau de journalisation, utilisez sc.setLogLevel (newLevel). Pour SparkR, utilisez setLogLevel (newLevel).
Bienvenue à
____ __
/ __ / __ ___ _____ / / __
_ / _ / _ `/ __ / '_ /
/ __ / .__ / _, _ / _ / / _ / _ version 2.4.1
/ _ /
Utilisation de Python version 3.7.3 (défaut, le 27 mars 2019 23:01:00)
SparkSession disponible en tant qu '«étincelle».
Vous êtes maintenant dans l’environnement shell Pyspark à l'intérieur votre conteneur Docker, et vous pouvez tester du code similaire à l'exemple du bloc-notes Jupyter:
>>> SMS = Caroline du Sud.fichier texte('fichier: //// usr / share / doc / python / copyright')
>>> impression(SMS.compter())
316
Vous pouvez maintenant travailler dans le shell Pyspark comme vous le feriez avec votre shell Python normal.
Remarque: Vous n'avez pas eu à créer un SparkContext variable dans l'exemple de shell Pyspark. Le shell PySpark crée automatiquement une variable, Caroline du Sud, pour vous connecter au moteur Spark en mode noeud unique.
Vous doit créer le vôtre SparkContext lors de la soumission de programmes PySpark réels avec spark-submit ou un cahier de Jupyter.
Vous pouvez également utiliser le shell Python standard pour exécuter vos programmes tant que PySpark est installé dans cet environnement Python. Le conteneur Docker que vous avez utilisé ne fait pas avoir PySpark activé pour l’environnement Python standard. Vous devez donc utiliser l'une des méthodes précédentes pour utiliser PySpark dans le conteneur Docker.
Comme vous l'avez déjà vu, PySpark est livré avec des bibliothèques supplémentaires pour effectuer des tâches telles que l'apprentissage automatique et la manipulation de grands ensembles de données à la manière de SQL. Cependant, vous pouvez également utiliser d'autres bibliothèques scientifiques courantes telles que NumPy et Pandas.
Vous devez les installer dans le même environnement sur chaque nœud de cluster, et ensuite votre programme peut les utiliser comme d’habitude. Ensuite, vous êtes libre d’utiliser toutes les astuces idiomatiques connues des pandas que vous connaissez déjà.
Rappelles toi: Les Pandas DataFrames sont évalués avec impatience de sorte que toutes les données doivent tenir dans la mémoire sur une seule machine.
Prochaines étapes pour le traitement de données massives réelles
Après avoir appris les bases de PySpark, vous voudrez sûrement commencer à analyser d’énormes quantités de données qui ne fonctionneront probablement pas si vous utilisez le mode machine unique. L'installation et la maintenance d'un cluster Spark sortent du cadre de ce guide et constituent probablement un travail à temps plein en soi.
Il est donc peut-être temps de vous rendre au service informatique de votre bureau ou d’envisager une solution de cluster hébergé Spark. Databricks est une solution hébergée potentielle.
Databricks vous permet d'héberger vos données avec Microsoft Azure ou AWS et dispose d'une période d'essai gratuite de 14 jours.
Après avoir fonctionné avec un cluster Spark, vous souhaiterez obtenir toutes vos données dans
ce groupe pour l'analyse. Spark dispose de plusieurs méthodes pour importer des données:
- Amazon S3
- Entrepôt de données Apache Hive
- Toute base de données avec une interface JDBC ou ODBC
Vous pouvez même lire des données directement à partir d'un système de fichiers réseau, comme le montrent les exemples précédents.
Les moyens d’accéder à toutes vos données ne manquent pas, que vous utilisiez une solution hébergée telle que Databricks ou votre propre cluster de machines.
Conclusion
PySpark est un bon point d'entrée dans le traitement des données volumineuses.
Dans ce tutoriel, vous avez appris que vous n’aviez pas à passer beaucoup de temps à apprendre à l’avance si vous maîtrisiez quelques concepts de programmation fonctionnels tels que carte(), filtre()et Python de base. En fait, vous pouvez utiliser tout le Python que vous connaissez déjà, y compris des outils familiers tels que NumPy et Pandas directement dans vos programmes PySpark.
Vous êtes maintenant capable de:
- Comprendre concepts Python intégrés qui s'appliquent au Big Data
- Écrire programmes de base PySpark
- Courir Programmes PySpark sur de petits jeux de données avec votre machine locale
- Explorer des solutions Big Data plus performantes comme un cluster Spark ou une autre solution hébergée personnalisée
[ad_2]